
Brief Bio
I am a professor of computer science at Columbia. I am also a researcher at Apple.
I was previously a research scientist at Google and a visiting researcher at Cruise. I completed my PhD at MIT in 2017 advised by Antonio Torralba and my BS at UC Irvine in 2011, where I got my start working with Deva Ramanan.
I received the 2024 PAMI Young Researcher Award and the 2021 NSF CAREER Award. I served as Senior Program Chair for ICLR in 2025 and General Chair in 2026, and currently sit on the board.
Research
By training machines to observe and interact with their surroundings, our research aims to create robust and versatile models for perception. Our lab often investigates visual models that capitalize on large amounts of unlabeled data and transfer across tasks and modalities. Other interests include robotics, interpretable models, and other modalities such as sound, language, and beyond.
The lab recruits one or two PhD students each year. Prospective PhD students should apply to the PhD program. Due to the volume of email we receive, we unfortunately cannot respond to emails about applications.
PhD Students and Postdocs





Graduated PhD Students and Former Postdocs
Representative Papers
Our research creates perception systems with diverse skills, including spatial, physical, logical, and reasoning abilities, for flexibly analyzing visual data. Our multimodal approach provides versatile representations for tasks like 3D reconstruction, visual question answering, and robot manipulation, while offering inherent explainability and excellent zero-shot generalization. The below papers highlight key examples of these capabilities.
Machine perception is challenging because most knowledge about our world, such as physical commonsense, is not written down. Through large amounts of unlabeled video and interaction with the natural world, we create algorithms that learn perceptual skills without manual supervision.
We create interpretable machine learning methods for perception that allow people to audit decisions and reprogram representations. Unlike black-box neural networks, we develop methods that are explainable by construction while still offering excellent performance.
Central to our research is forming an integrative perspective on perception to build accurate and robust models. Our research exploits the natural synchronization between vision, sound, and other modalities to learn cross-modal representations for tasks like recognition, source localization, and artistic correspondence.
We create new representations for spatial awareness, allowing vision systems to reconstruct scenes in 3D and anticipate object dynamics in the future. We often tightly integrate geometry, physics, and generative models in order to equip 3D vision systems with intuitive, and sometimes un-intuitive, physical skills.
We develop multi-modal learning methods for robotics, integrating vision, sound, interaction, and other modalities together in order to learn representations for perception, design, and action.
We leverage visual data to accelerate scientific discovery, developing methods that can identify patterns, make hypotheses, and generate insights across diverse scientific domains.
We harness language to learn neuro-symbolic methods for computer vision, establishing methods that rapidly generalize to open world tasks while offering inherent explainability too.
Critical applications require systems that are trustworthy and reliable. Our research demonstrates that predictive models have intrinsic empirical and theoretical advantages for improving robustness and generalization.
2026

Robot Critics that Sweat the Small Stuff
Sruthi Sudhakar, Junbang Liang, Sreehari Rammohan, Pavel Tokmakov, Richard Zemel, Carl Vondrick
arXiv 2026
PaperProject PageBibTeX

Do multimodal models imagine electric sheep?
Santhosh Kumar Ramakrishnan, Carl Vondrick, Raja Giryes, Philipp Krähenbühl, Vladlen Koltun
arXiv 2026
PaperBibTeX

Few-Shot Design Optimization by Exploiting Auxiliary Information
Arjun Mani, Carl Vondrick, Richard Zemel
ICML 2026
PaperProject PageBibTeX
2025

New York Smells: A Large Multimodal Dataset for Olfaction
Ege Ozguroglu, Junbang Liang, Ruoshi Liu, Mia Chiquier, Michael DeTienne, Wesley Wei Qian, Alexandra Horowitz, Andrew Owens, Carl Vondrick
arXiv 2025
PaperProject PageBibTeX
Video Generators are Robot Policies
Junbang Liang, Pavel Tokmakov, Ruoshi Liu, Sruthi Sudhakar, Paarth Shah, Rares Ambrus, Carl Vondrick
arXiv 2025
PaperProject PageBibTeX
MINERVA: Evaluating Complex Video Reasoning
Arsha Nagrani, Sachit Menon, Ahmet Iscen, Shyamal Buch, Ramin Mehran, Nilpa Jha, Anja Hauth, Yukun Zhu, Carl Vondrick, Mikhail Sirotenko, Cordelia Schmid, Tobias Weyand
ICCV 2025
PaperDatasetBibTeX

Towards LLM Agents for Earth Observation
Chia Hsiang Kao, Wenting Zhao, Shreelekha Revankar, Samuel Speas, Snehal Bhagat, Rajeev Datta, Cheng Perng Phoo, Utkarsh Mall, Carl Vondrick, Kavita Bala, Bharath Hariharan
arXiv 2025
PaperProject PageBibTeX
Teaching Humans Subtle Differences with DIFF-usion
Mia Chiquier, Orr Avrech, Yossi Gandelsman, Berthy Feng, Katherine Bouman, Carl Vondrick
arXiv 2025
PaperProject PageBibTeX
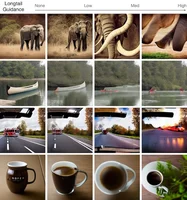
Generative Data Mining with Longtail-Guided Diffusion
David S. Hayden, Mao Ye, Timur Garipov, Gregory P. Meyer, Carl Vondrick, Zhao Chen, Yuning Chai, Eric Wolff, Siddhartha S. Srinivasa
ICML 2025
PaperBibTeX

DiSciPLE: Learning Interpretable Programs for Scientific Visual Discovery
Utkarsh Mall, Cheng Perng Phoo, Mia Chiquier, Bharath Hariharan, Kavita Bala, Carl Vondrick
CVPR 2025
PaperProject PageBibTeX
Self-Improving Autonomous Underwater Manipulation
Ruoshi Liu, Huy Ha, Mengxue Hou, Shuran Song, Carl Vondrick
ICRA 2025
PaperProject PageBibTeX
2024
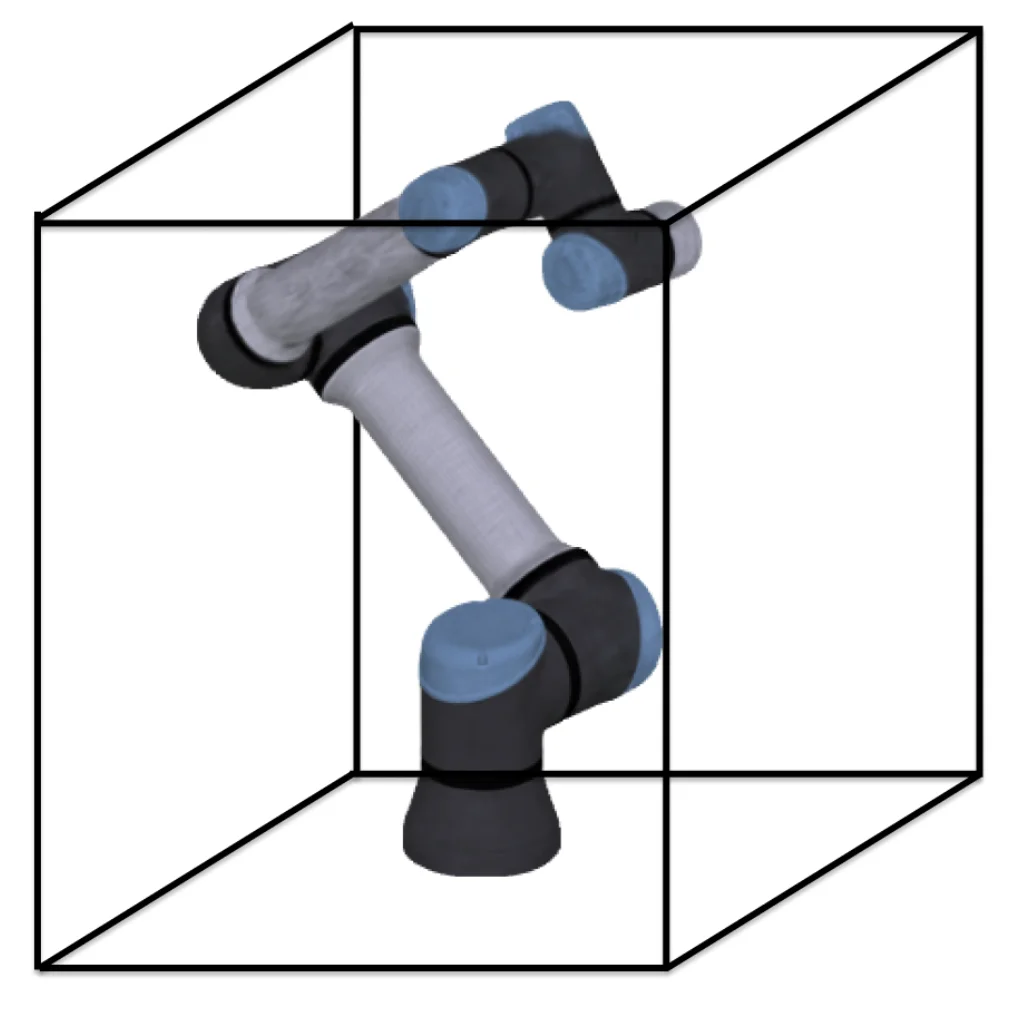
Differentiable Robot Rendering
Ruoshi Liu, Alper Canberk, Shuran Song, Carl Vondrick
CoRL 2024 (Oral)
PaperProject PageBibTeX
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, Carl Vondrick
CoRL 2024
PaperProject PageBibTeX

Whiteboard-of-Thought: Thinking Step-by-Step Across Modalities
Sachit Menon, Richard Zemel, Carl Vondrick
EMNLP 2024
PaperProject PageBibTeX
EraseDraw: Learning to Draw Step-by-Step via Erasing Objects from Images
Alper Canberk, Maksym Bondarenko, Ege Ozguroglu, Ruoshi Liu, Carl Vondrick
ECCV 2024
PaperProject PageBibTeX
How Video Meetings Change Your Expression
Sumit Sarin, Utkarsh Mall, Purva Tendulkar, Carl Vondrick
ECCV 2024
PaperProject PageBibTeX

Controlling the World by Sleight of Hand
Sruthi Sudhakar, Ruoshi Liu, Basile Van Hoorick, Carl Vondrick, and Richard Zemel
ECCV 2024 (Oral)
PaperBibTeX
Generative Camera Dolly: Extreme Monocular Dynamic Novel View Synthesis
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, Carl Vondrick
ECCV 2024 (Oral)
PaperProject PageBibTeX
Evolving Interpretable Visual Classifiers with Large Language Models
Mia Chiquier, Utkarsh Mall, Carl Vondrick
ECCV 2024
PaperProject PageBibTeX

SelfIE: Self-Interpretation of Large Language Model Embeddings
Haozhe Chen, Carl Vondrick, Chengzhi Mao
ICML 2024
PaperProject PageBibTeX
PaperBot: Learning to Design Real-World Tools Using Paper
Ruoshi Liu, Junbang Liang, Sruthi Sudhakar, Huy Ha, Cheng Chi, Shuran Song, Carl Vondrick
arXiv 2024
PaperProject PageBibTeX
pix2gestalt: Amodal Segmentation by Synthesizing Wholes
Ege Ozguroglu, Ruoshi Liu, Dídac Surís, Dian Chen, Achal Dave, Pavel Tokmakov, Carl Vondrick
CVPR 2024
PaperProject PageBibTeX

Raidar: geneRative AI Detection viA Rewriting
Chengzhi Mao, Carl Vondrick, Hao Wang, Junfeng Yang
ICLR 2024
PaperBibTeX
Interpreting and Controlling Vision Foundation Models via Text Explanations
Haozhe Chen, Junfeng Yang, Carl Vondrick, Chengzhi Mao
ICLR 2024
PaperBibTeX

Sin3DM: Learning a Diffusion Model from a Single 3D Textured Shape
Rundi Wu, Ruoshi Liu, Carl Vondrick, Changxi Zheng
ICLR 2024
PaperProject PageBibTeX

Remote Sensing Vision-Language Foundation Models without Annotations via Ground Remote Alignment
Utkarsh Mall, Cheng Perng Phoo, Meilin Liu, Carl Vondrick, Bharath Hariharan, Kavita Bala
ICLR 2024
PaperBibTeX
2023

Objaverse-XL: A Universe of 10M+ 3D Objects
Matt Deitke, et al.
NeurIPS 2023
PaperBibTeX
ViperGPT: Visual Inference via Python Execution for Reasoning
Dídac Surís, Sachit Menon, Carl Vondrick
ICCV 2023 (Oral)
PaperProject PageCodeBibTeX
Zero-1-to-3: Zero-shot One Image to 3D Object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, Carl Vondrick
ICCV 2023 (Oral)
PaperProject PageCodeDemoBibTeX
Muscles in Action
Mia Chiquier, Carl Vondrick
ICCV 2023
PaperProject PageBibTeX
SurfsUp: Learning Fluid Simulation for Novel Surfaces
Arjun Mani, Ishaan Preetam Chandratreya, Elliot Creager, Carl Vondrick, Richard Zemel
ICCV 2023
PaperProject PageBibTeX
Landscape Learning for Neural Network Inversion
Ruoshi Liu, Chengzhi Mao, Purva Tendulkar, Hao Wang, Carl Vondrick
ICCV 2023
PaperBlog PostBibTeX
SHIFT3D: Synthesizing Hard Inputs For Tricking 3D Detectors
Hongge Chen, Zhao Chen, Greg Meyer, Dennis Park, Carl Vondrick, Ashish Shrivastava, Yuning Chai
ICCV 2023
PaperBibTeX

Robust Perception through Equivariance
Chengzhi Mao, Lingyu Zhang, Abhishek Joshi, Junfeng Yang, Hao Wang, Carl Vondrick
ICML 2023
PaperProject PageBibTeX

Humans as Light Bulbs: 3D Human Reconstruction from Thermal Reflection
Ruoshi Liu, Carl Vondrick
CVPR 2023
PaperProject PageBibTeX

What You Can Reconstruct from a Shadow
Ruoshi Liu, Sachit Menon, Chengzhi Mao, Dennis Park, Simon Stent, Carl Vondrick
CVPR 2023
PaperBlog PostBibTeX
Tracking through Containers and Occluders in the Wild
Basile Van Hoorick, Pavel Tokmakov, Simon Stent, Jie Li, Carl Vondrick
CVPR 2023
PaperProject PageDatasetsCodeBibTeX

FLEX: Full-Body Grasping Without Full-Body Grasps
Purva Tendulkar, Dídac Surís, Carl Vondrick
CVPR 2023
PaperProject PageBibTeX

Doubly Right Object Recognition: A Why Prompt for Visual Rationales
Chengzhi Mao, Revant Teotia, Amrutha Sundar, Sachit Menon, Junfeng Yang, Xin Wang, Carl Vondrick
CVPR 2023
PaperBibTeX
Affective Faces for Goal-Driven Dyadic Communication
Scott Geng, Revant Teotia, Purva Tendulkar, Sachit Menon, Carl Vondrick
arXiv 2023
PaperProject PageBibTeX

Visual Classification via Description from Large Language Models
Sachit Menon, Carl Vondrick
ICLR 2023 (Oral)
PaperProject PageCodeDemoBibTeX

Understanding Zero-Shot Adversarial Robustness for Large-Scale Models
Chengzhi Mao, Scott Geng, Junfeng Yang, Xin Wang, Carl Vondrick
ICLR 2023
PaperBibTeX
2022
Adversarially Robust Video Perception by Seeing Motion
Lingyu Zhang, Chengzhi Mao, Junfeng Yang, Carl Vondrick
arXiv 2022
PaperProject PageBibTeX
Task Bias in Vision-Language Models
Sachit Menon, Ishaan Preetam Chandratreya, Carl Vondrick
arXiv 2022
PaperBibTeX
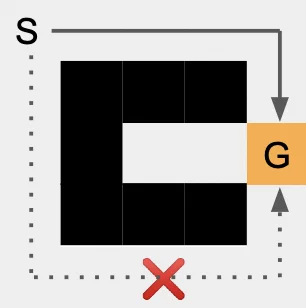
Private Multiparty Perception for Navigation
Hui Lu, Mia Chiquier, Carl Vondrick
NeurIPS 2022
PaperProject PageCodeBibTeX
Representing Spatial Trajectories as Distributions
Dídac Surís, Carl Vondrick
NeurIPS 2022
PaperProject PageBibTeX

Forget-me-not! Contrastive Critics for Mitigating Posterior Collapse
Sachit Menon, David Blei, Carl Vondrick
UAI 2022
PaperBibTeX
Revealing Occlusions with 4D Neural Fields
Basile Van Hoorick, Purva Tendulkar, Dídac Surís, Dennis Park, Simon Stent, Carl Vondrick
CVPR 2022
PaperProject PageTalkBibTeX

Globetrotter: Connecting Languages by Connecting Images
Dídac Surís, Dave Epstein, Carl Vondrick
CVPR 2022 (Oral)
PaperProject PageCodeBibTeX

Causal Transportability for Visual Recognition
Chengzhi Mao, Kevin Xia, James Wang, Hao Wang, Junfeng Yang, Elias Bareinboim, Carl Vondrick
CVPR 2022
PaperBibTeX

It's Time for Artistic Correspondence in Music and Video
Dídac Surís, Carl Vondrick, Bryan Russell, Justin Salamon
CVPR 2022
PaperProject PageBibTeX

UnweaveNet: Unweaving Activity Stories
Will Price, Carl Vondrick, Dima Damen
CVPR 2022
PaperBibTeX
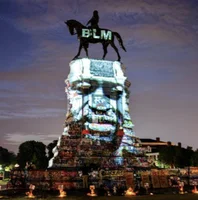
There is a Time and Place for Reasoning Beyond the Image
Xingyu Fu, Ben Zhou, Ishaan Preetam Chandratreya, Carl Vondrick, Dan Roth
ACL 2022 (Oral)
PaperCode + DataBibTeX
Real-Time Neural Voice Camouflage
Mia Chiquier, Chengzhi Mao, Carl Vondrick
ICLR 2022 (Oral)
PaperProject PageScienceBibTeX

Discrete Representations Strengthen Vision Transformer Robustness
Chengzhi Mao, Lu Jiang, Mostafa Dehghani, Carl Vondrick, Rahul Sukthankar, Irfan Essa
ICLR 2022
PaperBibTeX
2021
Full-Body Visual Self-Modeling of Robot Morphologies
Boyuan Chen, Robert Kwiatkowski, Carl Vondrick, Hod Lipson
Science Robotics 2022
PaperProject PageCodeBibTeX
The Boombox: Visual Reconstruction from Acoustic Vibrations
Boyuan Chen, Mia Chiquier, Hod Lipson, Carl Vondrick
CoRL 2021
PaperProject PageVideo OverviewBibTeX

Adversarial Attacks are Reversible with Natural Supervision
Chengzhi Mao, Mia Chiquier, Hao Wang, Junfeng Yang, Carl Vondrick
ICCV 2021
PaperCodeBibTeX

Dissecting Image Crops
Basile Van Hoorick, Carl Vondrick
ICCV 2021
PaperCodeBibTeX
Learning the Predictability of the Future
Dídac Surís, Ruoshi Liu, Carl Vondrick
CVPR 2021
PaperProject PageCodeModelsTalkBibTeX
Generative Interventions for Causal Learning
Chengzhi Mao, Amogh Gupta, Augustine Cha, Hao Wang, Junfeng Yang, Carl Vondrick
CVPR 2021
PaperCodeBibTeX

Learning Goals from Failure
Dave Epstein, Carl Vondrick
CVPR 2021
PaperProject PageDataCodeTalkBibTeX
Visual Behavior Modelling for Robotic Theory of Mind
Boyuan Chen, Carl Vondrick, Hod Lipson
Scientific Reports 2021
PaperProject PageBibTeX
2020
Listening to Sounds of Silence for Speech Denoising
Ruilin Xu, Rundi Wu, Yuko Ishiwaka, Carl Vondrick, Changxi Zheng
NeurIPS 2020
PaperProject PageBibTeX

Multitask Learning Strengthens Adversarial Robustness
Chengzhi Mao, Amogh Gupta, Vikram Nitin, Baishakhi Ray, Shuran Song, Junfeng Yang, Carl Vondrick
ECCV 2020
PaperBibTeX
We Have So Much In Common: Modeling Semantic Relational Set Abstractions in Videos
Alex Andonian, Camilo Fosco, Mathew Monfort, Allen Lee, Carl Vondrick, Rogerio Feris
ECCV 2020
PaperProject PageBibTeX

Learning to Learn Words from Visual Scenes
Dídac Surís, Dave Epstein, Heng Ji, Shih-Fu Chang, Carl Vondrick
ECCV 2020
PaperProject PageCodeTalkBibTeX
Oops! Predicting Unintentional Action in Video
Dave Epstein, Boyuan Chen, Carl Vondrick
CVPR 2020
PaperProject PageDataCodeTalkBibTeX
2019
Metric Learning for Adversarial Robustness
Chengzhi Mao, Ziyuan Zhong, Junfeng Yang, Carl Vondrick, Baishakhi Ray
NeurIPS 2019
PaperCodeBibTeX

VideoBERT: A Joint Model for Video and Language Representation Learning
Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, Cordelia Schmid
ICCV 2019
PaperBlogBibTeX

Multi-level Multimodal Common Semantic Space for Image-Phrase Grounding
Hassan Akbari, Svebor Karaman, Surabhi Bhargava, Brian Chen, Carl Vondrick, Shih-Fu Chang
CVPR 2019
PaperCodeBibTeX

Relational Action Forecasting
Chen Sun, Abhinav Shrivastava, Carl Vondrick, Rahul Sukthankar, Kevin Murphy, Cordelia Schmid
CVPR 2019
PaperBibTeX

Moments in Time Dataset: one million videos for event understanding
Mathew Monfort et al
PAMI 2019
PaperProject PageBibTeX
2018
Tracking Emerges by Colorizing Videos
Carl Vondrick, Abhinav Shrivastava, Alireza Fathi, Sergio Guadarrama, Kevin Murphy
ECCV 2018
PaperBlogBibTeX
The Sound of Pixels
Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick, Josh McDermott, Antonio Torralba
ECCV 2018
PaperProject PageBibTeX

Actor-centric Relation Network
Chen Sun, Abhinav Shrivastava, Carl Vondrick, Kevin Murphy, Rahul Sukthankar, Cordelia Schmid
ECCV 2018
PaperBibTeX
AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions
Chunhui Gu et al
CVPR 2018 (Spotlight)
PaperProject PageBibTeX
2017

Following Gaze in Video
Adria Recasens, Carl Vondrick, Aditya Khosla, Antonio Torralba
ICCV 2017
PaperBibTeX
Generating the Future with Adversarial Transformers
Carl Vondrick, Antonio Torralba
CVPR 2017
PaperProject PageBibTeX
Cross-Modal Scene Networks
Yusuf Aytar, Lluis Castrejon, Carl Vondrick, Hamed Pirsiavash, Antonio Torralba
PAMI 2017
PaperProject PageBibTeX

See, Hear, and Read: Deep Aligned Representations
Yusuf Aytar, Carl Vondrick, Antonio Torralba
arXiv 2017
PaperProject PageBibTeX
2016
Generating Videos with Scene Dynamics
Carl Vondrick, Hamed Pirsiavash, Antonio Torralba
NeurIPS 2016
PaperProject PageCodeNBCScientific AmericanNew ScientistMIT NewsBibTeX
SoundNet: Learning Sound Representations from Unlabeled Video
Yusuf Aytar, Carl Vondrick, Antonio Torralba
NeurIPS 2016
PaperProject PageCodeNPRNew ScientistWeek JuniorMIT NewsBibTeX

Anticipating Visual Representations with Unlabeled Video
Carl Vondrick, Hamed Pirsiavash, Antonio Torralba
CVPR 2016 (Spotlight)
PaperProject PageNPRCNNAPWiredStephen ColbertMIT NewsBibTeX
Predicting Motivations of Actions by Leveraging Text
Carl Vondrick, Deniz Oktay, Hamed Pirsiavash, Antonio Torralba
CVPR 2016
PaperdatasetBibTeX

Learning Aligned Cross-Modal Representations from Weakly Aligned Data
Lluis Castrejon, Yusuf Aytar, Carl Vondrick, Hamed Pirsiavash, Antonio Torralba
CVPR 2016
PaperProject PageDemoBibTeX

Visualizing Object Detection Features
Carl Vondrick, Aditya Khosla, Hamed Pirsiavash, Tomasz Malisiewicz, Antonio Torralba
IJCV 2016
PaperProject PageSlidesMIT NewsBibTeX
2015

Do We Need More Training Data?
Xiangxin Zhu, Carl Vondrick, Charless C. Fowlkes, Deva Ramanan
IJCV 2015
PaperdatasetBibTeX

Learning Visual Biases from Human Imagination
Carl Vondrick, Hamed Pirsiavash, Aude Oliva, Antonio Torralba
NeurIPS 2015
PaperProject PageTechnology ReviewBibTeX

Where are they looking?
Adria Recasens, Aditya Khosla, Carl Vondrick, Antonio Torralba
NeurIPS 2015
PaperProject PageDemoBibTeX
2014

Assessing the Quality of Actions
Hamed Pirsiavash, Carl Vondrick, Antonio Torralba
ECCV 2014
PaperProject PageBibTeX
2013
HOGgles: Visualizing Object Detection Features
Carl Vondrick, Aditya Khosla, Tomasz Malisiewicz, Antonio Torralba
ICCV 2013 (Oral)
PaperProject PageslidesMIT NewsBibTeX
2012
Do We Need More Training Data or Better Models for Object Detection?
Xiangxin Zhu, Carl Vondrick, Deva Ramanan, Charless C. Fowlkes
BMVC 2012
PaperDatasetBibTeX
Efficiently Scaling Up Crowdsourced Video Annotation
Carl Vondrick, Donald Patterson, Deva Ramanan
IJCV 2012
PaperProject PageBibTeX
2011

Video Annotation and Tracking with Active Learning
Carl Vondrick, Deva Ramanan
NeurIPS 2011
PaperProject PageBibTeX
A Large-scale Benchmark Dataset for Event Recognition
Sangmin Oh, et al.
CVPR 2011
PaperProject PageBibTeX
2010
Efficiently Scaling Up Video Annotation with Crowdsourced Marketplaces
Carl Vondrick, Deva Ramanan, Donald Patterson
ECCV 2010
PaperProject PageBibTeX
Teaching
- Computer Vision II (Summer 2021, Spring 2022-2025)
- Computer Vision I (Fall 2018-2019)
- Advanced Computer Vision (Spring 2019)
- Machine Learning Frontiers (Fall 2024-2025)
- Representation Learning (Fall 2020-2022)
Funding
- National Science Foundation
- Defense Advanced Research Projects Agency
- Toyota Research Institute
- Amazon Research