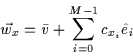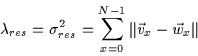![[*]](http://vismod.www.media.mit.edu/vismod/support/latex2html-98//cross_ref_motif.gif) . The remapped approximations for
Figure are shown in Figure . Note the low
degree of ``lossiness'' of the compression despite the large compression ratio
of 7000 pixels to 60 coefficients (i.e., 117:1 compression).
. The remapped approximations for
Figure are shown in Figure . Note the low
degree of ``lossiness'' of the compression despite the large compression ratio
of 7000 pixels to 60 coefficients (i.e., 117:1 compression).
We can quantify the lossiness in the KL-based decomposition by measuring the
variance between the original vector ![]() and the optimal linear
approximation vector
and the optimal linear
approximation vector ![]() .
This residual variance, residuex accounts
for the total variance in our vector that cannot be spanned by the
eigenvectors. The total residual variance in the dataset that cannot be
spanned by the eigenvectors is denoted by
.
This residual variance, residuex accounts
for the total variance in our vector that cannot be spanned by the
eigenvectors. The total residual variance in the dataset that cannot be
spanned by the eigenvectors is denoted by
![]() and
computed using Equation :
and
computed using Equation :
We have thus described a method for converting a mug-shot image into a 60-scalar code which describes it in the KL domain. Furthermore, we have shown how this transformation can be inverted so that the 60-element code can be used to regenerate an approximation to the original image. Thus, the KL transform and ``inverse'' KL transform are added to our palette of tools.
![\begin{figure}% latex2html id marker 2999
\center
\begin{tabular}[b]{ccccc}
\...
...
{Re-approximating the gallery's mug-shot images after KL-encoding}\end{figure}](img217.gif)