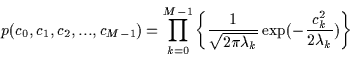![[*]](http://vismod.www.media.mit.edu/vismod/support/latex2html-98//cross_ref_motif.gif) . In Figure , we
display the 60 scalar code representing one face from our training set. This encoding
is performed for each face x
. In Figure , we
display the 60 scalar code representing one face from our training set. This encoding
is performed for each face x
With K-L decomposition, there is no correlation between the coefficients in the
key (i.e., each dimension in the 60 dimensional space populated by face-points
is fully uncorrelated)[17]. Consequently, the dataset appears as a
multivariate random Gaussian distribution. The corresponding 60 dimensional
probability density function is approximated in the L2 sense by
Equation [17]:
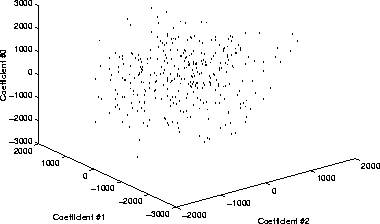
The envelope of this Gaussian distribution is a hyperellipsoid [17]
whose axis along each dimension is proportional to the eigenvalue of the
dimension. In other words, the hyperellipsoid is ``thin'' in the higher-order
dimensions and relatively wide in the lower-order ones. Although it is
impossible to visualize the distribution in 60 dimensions, an idea of this
arrangement can be seen in Figure which shows the
distribution of the data set along the 3 first-order coefficients (associated
with the 3 first-order eigenvectors).
![\begin{figure}% latex2html id marker 2963
\center
\begin{tabular}[b]{cc}
\eps...
...a key in KL-space]
{Converting a mug-shot into a key in KL-space. }\end{figure}](img213.gif)