The set of input images in Figure ![[*]](http://vismod.www.media.mit.edu/vismod/support/latex2html-98//cross_ref_motif.gif) illustrates some of
the variations in the intensity image that detection must be capable of
overcoming to properly localize the face. These variations need appropriate
compensation to isolate only the relevant data necessary for recognition.
Furthermore, note that these variations can occur in any combination and are
not mutually exclusive.
illustrates some of
the variations in the intensity image that detection must be capable of
overcoming to properly localize the face. These variations need appropriate
compensation to isolate only the relevant data necessary for recognition.
Furthermore, note that these variations can occur in any combination and are
not mutually exclusive.
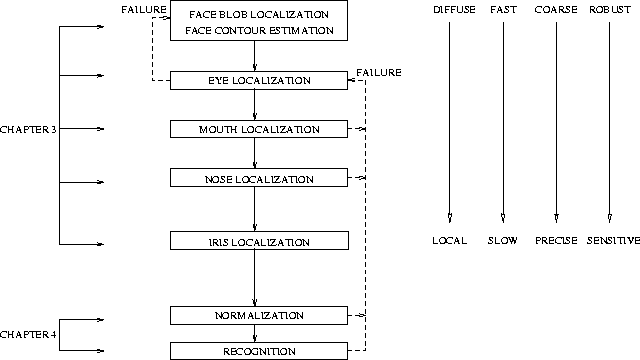
We propose a hierarchical detection method which can quickly and reliably converge to a localization of the face amidst a wide range of external visual stimuli and variation. It is necessary to precede expensive computations with simple and efficient ones in this hierarchy to maximize efficiency. The results of the initial, diffuse and large search space computations narrow the search space for the more localized, higher precision operations that will follow. In other words, the results of preliminary detections guide the use of subsequent operations in a feed-forward manner to restrict their application to only significant parts of the image. This reduces the probability of error since the subsequent detection steps will not be distracted by irrelevant image data. Furthermore, more robust operations precede more sensitive ones in our hierarchy since the sensitive operations in the hierarchy need to have adequate initialization from previous stages to prevent failure.
Figure displays the sequence of search steps for the face
detection. We begin by searching for possible face or head-like blobs in the
image. The detected blob candidates are examined to obtain an approximation of
their contours. If these exhibit a face-like contour, their interior is
scanned for the presence of eyes. Each of the possible pairs of eyes detected
in the face are examined one at a time to see if they are in an appropriate
position with respect to the facial contour. If they are, then we search for a
mouth isolated by the facial contour and the position of the detected eyes.
Once a mouth has been detected, the region to be searched for a nose is better
isolated and we determine the nose position. Lastly, these facial coordinates
are used to more accurately locate the iris within the eye region, if they are
visible. The final result is a set of geometrical coordinates that specify the
position, scale and pose of all possible faces in the image. The last few
stages will be discussed in Chapter 4 which utilizes the facial coordinates to
normalize the image and perform recognition. Note the many feedback loops
which propagate data upwards in the hierarchy. These are used by the later
stages to report failure to the preliminary stages so that appropriate action can
be taken. For instance, if we fail to find a mouth, the pair of possible eyes
that was used to guide the search for the mouth was not a valid one and we
should consider the use of another possible pair of eyes.
Note the qualitative comparison of the different stages on the right of
Figure . This is a figurative description of the
coarse-to-fine approach of the algorithm. The initial stages of the search are
very fast and coarse since they use low resolution operators. Furthermore,
these operators are used to search relatively large regions in the image.
Additionally, the early stages are robust to noise and do not need to have
constrained data to function. Later stages yield more precise localization
information and use high resolution, slow operators. However, they are
sensitive to distracting external data or noise and therefore need to be
applied in a small, constrained window for a local analysis. In other words,
they need to be guided by the previous, robust stages of the search. This
figurative description of the stages is merely intended to reflect the spirit
with which detection is to be approached. In short, it begins with a 'quick
and dirty' estimate of where the face is and then slowly refines its
localization around that neighbourhood by searching for more precise albeit
elusive targets (such as the iris). This concept (coarseness to fineness) will
become clearer as the individual stages of the algorithm and their
interdependencies are explained later.
We implement this hierarchical search as a control structure which utilizes a palette of tools that includes the biologically and perceptually motived computations developed in Chapter 2. These are used to extract low-level geometrical descriptions of image data which will be processed to generate a robust and accurate localization of the face.
Note that the detection algorithm is based on a variety of heuristics that vaguely describe a model for the human face. The multitude of thresholds and geometric relationships that we introduce at each stage of the localization define our model of the human face cumulatively. Furthermore, the thresholds and constraints on this face model have been kept relatively lax to allow for a wide range of face imaging situations. Consequently, the numerical parameters that are utilized are not critical, nor are they optimal or unnecessarily sensitive. Rather, the parameters allow for large margins of safety and are forgiving, allowing face detection to proceed despite noise, variations, etc. Thus, a flexible, forgiving model gives the system greater robustness and fewer misdetections. In fact, a face is such a multi-dimensional, highly deformable object that an explicit, precisely parametrized model would be very difficult to derive and manipulate.
![\begin{figure}% latex2html id marker 1067
\center
\begin{tabular}[b]{ccccc}
\...
...age. (h) Changes in facial expression. (i)
Out-of-plane rotation. }\end{figure}](img70.gif)