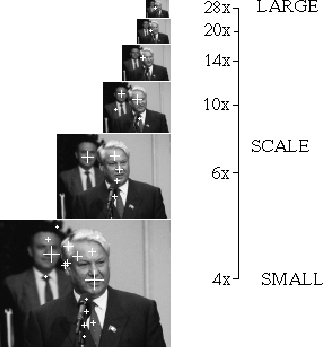
We begin with an arbitrary image of a natural uncontrived scene containing
people. We then generate an intensity image pyramid as in
Figure ![[*]](http://vismod.www.media.mit.edu/vismod/support/latex2html-98//cross_ref_motif.gif) and a corresponding edge map pyramid as shown in
Figure . We use the edge map pyramid to apply
the symmetry transform at various scales. This allows us to detect blobs of
arbitrary size in the image. The blob detector uses only the 6 annular
sampling regions described in Table . We can afford to
limit the number of annular sampling regions to six at this stage since the
subaveraging involved in the pyramid obviates the need for more scale
invariance in the operator. We apply the general symmetry transform to each of
the edge maps and mark the centers of the detected blobs on the intensity
pyramid. The general transform (not the dark or bright symmetry transform) was
utilized since heads and faces do not consistently appear either brighter or
darker than the background of a scene. This multi-scale interest detection
operation provides us with the blob detection pyramid displayed in
Figure .
and a corresponding edge map pyramid as shown in
Figure . We use the edge map pyramid to apply
the symmetry transform at various scales. This allows us to detect blobs of
arbitrary size in the image. The blob detector uses only the 6 annular
sampling regions described in Table . We can afford to
limit the number of annular sampling regions to six at this stage since the
subaveraging involved in the pyramid obviates the need for more scale
invariance in the operator. We apply the general symmetry transform to each of
the edge maps and mark the centers of the detected blobs on the intensity
pyramid. The general transform (not the dark or bright symmetry transform) was
utilized since heads and faces do not consistently appear either brighter or
darker than the background of a scene. This multi-scale interest detection
operation provides us with the blob detection pyramid displayed in
Figure .
We thresholded the output of the interest map so that only attentional peaks
exhibiting a certain minimal level of interest will appear in the output. The
threshold on the interest map is very tolerant and allows many extremely weak
blobs to register. Thus, the precise selection of an interest map threshold is
not critical. Furthermore, we only consider the five (5) strongest peaks of
interest or the five most significant blobs for each scale in the multi-scalar
analysis. This is to prevent the system from spending too much time at each
scale investigating blobs. We expect the face to be somewhat dominant in the
image so that it will be one of the strongest five blobs in the image (at the
scale it resides in). If we expect many faces or other blobs in the image at
the same scale, this value can be increased beyond 5. This would be
advantageous, for example, when analyzing group photos. Both a threshold on
interest value and the limitation on the number of peaks are required since we
do not wish to ever process more than 5 blobs per scale for efficiency and we
require the blobs to exhibit a minimal level of significance to warrant any
investigation whatsoever. Furthermore, we stop applying the interest operator
for scales smaller than 4x. The interest operator is limited in size to r=9
pixels and consequently, the blobs detected at scales lower than 4x would be
too small and would have insufficient resolution for subsequent facial feature
localization and recognition. For example, the blobs detected at scale 3x
would be less than 54 ![]() 54 pixel objects and the representation of a
face at such a resolution would prevent accurate facial feature detection.
54 pixel objects and the representation of a
face at such a resolution would prevent accurate facial feature detection.
The peaks in Figure are shown before we
threshold the interest response, threshold the number of blobs per scale
(maximum of 5) and before we limit the scale of the search. Once these three
limits are introduced, the number of peaks generated by the face blob
detection stage will drop as shown on the right hand side of
Figure . Only a total of 5 peaks are valid after this
filtering (as seen by the 5 square grids that remain for processing by the
next stages).
There is some redundancy as some blobs are detected more than once at adjacent scales. This is due to overlap in scale-space of our symmetry transform operator. However, this redundancy or multiple-hit phenomenon is not problematic since we will use later stages to select only one 'hit' or one face out of several redundant blob responses. Additionally, the detection of non-facial blobs is not problematic at this stage. Since each blob is to undergo further processing to determine if it is truly a face, we can allow false alarms during blob detection. Finally, lack of accuracy in our blob detector is also acceptable at this stage since we will refine the localization of faces in subsequent stages. What is most dangerous at this early stage of the algorithm is a total miss of a face or head blob in the image. Fortunately, a clear miss of the face in our multi-scalar blob detection is extremely unlikely since heads and faces have consistently strong responses in the perceptual interest map.