|
The Columbia X-Cultural Deception Corpus Department of Computer Science - Columbia University |
|
Internal
• Speech Lab
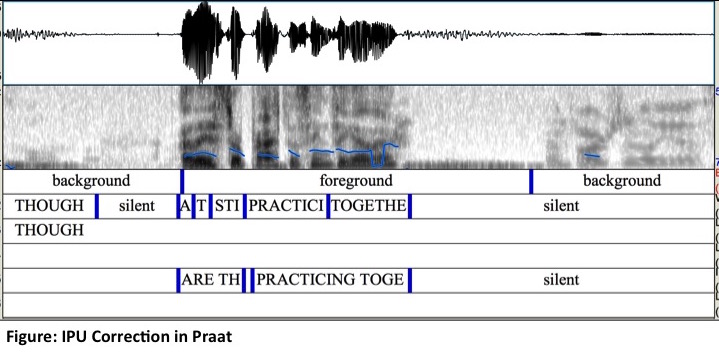
| AnnotationTo facilitate seamless transcription, the two channels of audio were separated. We collected the transcripts through Amazon Mechanical Turk (AMT): a large-scale crowdsourcing service that is used to perform "Human Intelligence Tasks" (HITs). Each HIT contained 21 clips (one for quality control, and 20 others). A research assistant correctly transcribed the quality control clip; the clips transcribed were compared to this correct clip to see how the transcribers were performing overall. We posted, and obtained, three transcripts for each audio segment from three different transcribers. Once we had a single, consensus, transcript for each clip, we force aligned the transcript with the audio. We utilized the Kaldi Speech Recognition Toolkit. For this forced alignment, the acoustic model we used was a triphone Gaussian Mixture Model (GMM) with Feature space Maximum Likelihood Linear Regression (fMLLR) adaptation and trained using the standard Kaldi recipe and the Wall Street Journal corpus. Using the CMUDict as a lexicon resulted in approximately 4,006 out-of- vocabulary (OOV) tokens from all transcriptions. These OOVs included 2,202 true OOV terms (this includes proper names which did not appear in CMUDict, and also word fragments such as false), and 1,804 spelling mistakes which required hand correction. Using Praat, we segmented all speech into inter-pausal units (IPU). The minimal pause length between IPUs used was 50ms. We identified IPU boundaries as silences identified by the aligner as it aligned the spoken words. By parsing the aligned transcription files, we used the word boundaries to infer silence and speech labels, and then extracted IPUs. We then converted the time-stamped points at which the subjects labeled their utterances, during the interviews, as true or false to intervals; the underlying assumption here was that each key press labels the preceding speech up to the previous true/false label as the subjects were instructed to do. For each IPU, we checked which interval it overlapped with and labeled it as true or false. For IPUs that overlapped two contradicting labels, we checked to see if the subjects mistakenly pressed the wrong key during the interview (they were instructed to correct any mistakes by quickly pressing the correct key). If the conflicting key presses were less than 10ms apart, we assumed that was an error and used the second key press as the correct label. In other cases, we chose the label that had the longer coverage of the IPU. For the classification experiments we conducted, IPUs that had conflicting labels were not included (only approximately 5% had conflicting labels). In total, we used 145,621 IPUs in our classification experiments.
|