![[*]](http://vismod.www.media.mit.edu/vismod/support/latex2html-98//cross_ref_motif.gif) :
:
We then introduce the concept of recognition certainty. Certainty involves
comparing the distance a face has from its correct match in the database to
the distance it has from other members in the database. Evidently, our
recognition output is more reliable (or has better certainty) if a face is
much closer to its match and than it is to other members of the database.
Consider face#0 from the database which is shown with its synthesized
mug-shot image in Figure . The eyes, nose and mouth have been
localized accurately at positions i0', i1', i2' and i3'. These
anchor points are used to generate a mug-shot version of face#0 using
Equation .
This face is a member of our database (face0) and so
d(probe,face0)=d(face0,face0)=0. However, if we perturb the values
i0', i1', i2' and i3' by a small amount, the resulting probe
image using Equation will be different and dmin will
no longer be 0. The distance of the probe face (probe) to the correct match
face#0 in the database is defined as
d(probe,face0). The distance to the
closest incorrect response is
![]() ,
as defined in
equation :
,
as defined in
equation :
In Equation we compute a margin of safety which is
positive when the probe resembles its correct match face#0 and negative when
the probe matches another element of the database, instead.
Since the probe is actually the result of the function N in
Equation , it has i0, i1, i2 and i3 as its
parameters as well. By the same token, the value of c in
Equation also has i0, i1, i2 and i3 as
parameters. Thus, it is more appropriate to write
c(i0x,i0y,i1x,i1y,i2x,i2y,i3x,i3y). However,
for compactness, we shall only refer to the certainty as c.
We shall now compute the sensitivity of the certainty (c) to variations in
the localization (i0, i1, i2 and i3) for the image Icorresponding to face#0. This is done by computing
![]() .
.
We vary the ![]() values which cause the localization of a feature point to
move around its original position. The anchor point's displacement caused by a
particularly large
values which cause the localization of a feature point to
move around its original position. The anchor point's displacement caused by a
particularly large ![]() is depicted in Figure . The
dimensions of this image are
is depicted in Figure . The
dimensions of this image are
![]() and the intra-ocular distance is
approximately 60 pixels. In the experiments, the
and the intra-ocular distance is
approximately 60 pixels. In the experiments, the ![]() values are varied
over a range of [-15,15] pixels each. We then synthesize a new mug-shot image
from the perturbed anchor points.
values are varied
over a range of [-15,15] pixels each. We then synthesize a new mug-shot image
from the perturbed anchor points.
Figure shows several synthesized images after perturbing
![]() and
and
![]() ,
with all other
,
with all other ![]() values fixed at 0.
Not surprisingly, the mug-shots that are synthesized appear slightly different
depending on the position of i0 (the locus of the left eye). Similarly,
Figure shows the approximations after the KL encoding of
the mug-shots in Figure . The approximations, too, are
affected, showing that the KL transformations is sensitive to errors in
localization. Finally, in Figure we show the value of c as
we vary
values fixed at 0.
Not surprisingly, the mug-shots that are synthesized appear slightly different
depending on the position of i0 (the locus of the left eye). Similarly,
Figure shows the approximations after the KL encoding of
the mug-shots in Figure . The approximations, too, are
affected, showing that the KL transformations is sensitive to errors in
localization. Finally, in Figure we show the value of c as
we vary
![]() and
and
![]() ,
with all other
,
with all other ![]() .
.
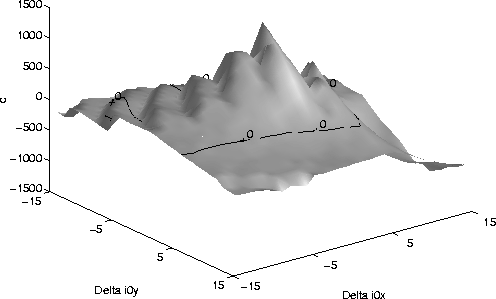
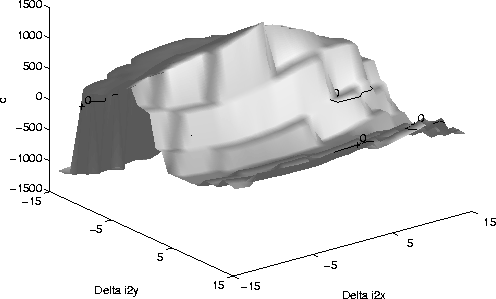
Figure shows the value of c for variations in the (x,y)position of the right eye anchor point. Similarly, Figure and
Figure show the same analysis for the nose point under two
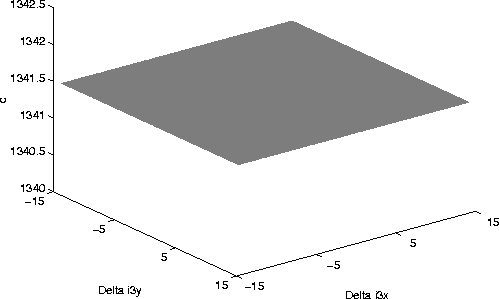
different views. Finally, Figure shows the effect of
perturbing the mouth point. This surface is quite different from the ones in
the previous experiments. In fact, the value of c stays constant and
positive indicating that the changes in the mouth position have brought no
change in the synthesized mug-shot and that the recognition performance is
unaffected by mouth localization errors. This is due to the insensitivity the
3D normalization procedure (defined in Chapter 4) has to the locus of the
mouth point.
The above plots show that the localization does not have to be perfect for
recognition to remain successful. In these graphs, as long as the value of cis positive, then the subject is identifiable. Even though these sensitivity
measurements were made by varying only two parameters, the 8 dimensional
sensitivity surface can be approximated by a weighted sum of the 4 individual
surfaces described above. Thus, an 8 dimensional sub-space exists which
defines the range of the 8 ![]() perturbations that will be tolerated
before recognition errors occur. In short, the anchor-point localizations may
be perturbed by several pixels before recognition degrades excessively.
perturbations that will be tolerated
before recognition errors occur. In short, the anchor-point localizations may
be perturbed by several pixels before recognition degrades excessively.
From the above plots, it is evident that the
![]() (the nose locus)
is the most sensitive anchor point since it causes the most drastic change in
c. Consequently, an effort should be made to change the normalization
algorithm to reduce the sensitivity of the recognition to this locus. On the
other hand, there is a large insensitivity to the location of the mouth. This
is due to the limited effect the mouth has in the normalization procedure. In
fact, the mouth only determines the vertical stretch or deformation that needs
to be applied to the 3D model. Thus, an effort should be made to use the
location of the mouth more actively in the normalization algorithm discussed
in Chapter 4. Recall that an error Emouth was present in the
normalization while the other 3 anchor points always aligned perfectly to the
eyes and nose in the image (using the WP3P). Thus the 3D normalization has an
alignment error concentrated upon the mouth-point which is the only point on
the 3D model which does not always line-up with its destination on the image.
If this error could be distributed equally among all four features points,
each point will be slightly misaligned and the total misalignment error would
be less. Consequently, the 3D model's alignment to the face in the image
would be more accurate, overall. Thus, we would attempt to minimize
Etotal as in Equation instead of minimizing Emouthwith
Eleft-eye=Eright-eye=Enose=0. The end result would be an
overall greater insensitivity and recognition robustness for the 8
localization parameters combined.
(the nose locus)
is the most sensitive anchor point since it causes the most drastic change in
c. Consequently, an effort should be made to change the normalization
algorithm to reduce the sensitivity of the recognition to this locus. On the
other hand, there is a large insensitivity to the location of the mouth. This
is due to the limited effect the mouth has in the normalization procedure. In
fact, the mouth only determines the vertical stretch or deformation that needs
to be applied to the 3D model. Thus, an effort should be made to use the
location of the mouth more actively in the normalization algorithm discussed
in Chapter 4. Recall that an error Emouth was present in the
normalization while the other 3 anchor points always aligned perfectly to the
eyes and nose in the image (using the WP3P). Thus the 3D normalization has an
alignment error concentrated upon the mouth-point which is the only point on
the 3D model which does not always line-up with its destination on the image.
If this error could be distributed equally among all four features points,
each point will be slightly misaligned and the total misalignment error would
be less. Consequently, the 3D model's alignment to the face in the image
would be more accurate, overall. Thus, we would attempt to minimize
Etotal as in Equation instead of minimizing Emouthwith
Eleft-eye=Eright-eye=Enose=0. The end result would be an
overall greater insensitivity and recognition robustness for the 8
localization parameters combined.
We have thus presented the system's structure as a whole. The localization and recognition tests evaluate its performance. For one training image, the system is competitive when compared to contemporary face recognition algorithms such as the one proposed by Lawrence[23]. Other current algorithms include [32] and [29] which report recognition rates of 98% and 92% respectively. However, these algorithms were tested on mostly frontal images (not the Achermann database or similar database). Finally, a sensitivity analysis depicts the dependence of the recognition module on the localization output. We see that the localization does not have to be exact for recognition to be successful. However, the sensitivity plots do show that recognition is not equally sensitive to perturbations in the localization of different anchor point. Thus, the normalization process needs to be adjusted to compensate for this discrepancy.
![\begin{figure}% latex2html id marker 4428
\center
\begin{tabular}[b]{cc}
\eps...
... with anchor points.
(b) Corresponding synthesized mug-shot image.}\end{figure}](img260.gif)
![\begin{figure}% latex2html id marker 4480
\center
\begin{tabular}[b]{cc}
\eps...
... with anchor points.
(b) Corresponding synthesized mug-shot image.}\end{figure}](img267.gif)