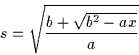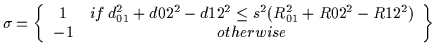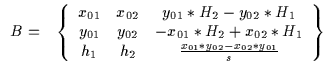![[*]](http://vismod.www.media.mit.edu/vismod/support/latex2html-98//cross_ref_motif.gif) and an exact solution which
involves 6 distances can be found to the problem of fitting to three 2D points
and an exact solution which
involves 6 distances can be found to the problem of fitting to three 2D points
It is important at this stage to consider perspective. In 3D rendering, perspective generally enhances the realism of a scene. Buildings and geometric objects appear to taper off or shrink as they move away from the user in distance. If, however, the size of the object in depth is relatively small, the perspective effect is negligible. The effect of perspective on face images is subtle to the human eye and it is thus possible to render 3D face data without such perspective computations. We shall utilize this simplification and approach the solution of fitting to three points using the Weak-Perspective-3-Points (WP3P) technique [2]. A brief summary of the computation of the solution to WP3P is presented here, but for an in-depth analysis of the derivation the reader should consult [2].
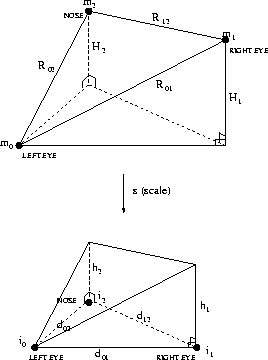
Observe Figure which depicts the desired, scaled orthographic
projection of the model upon the image plane. The intra-point distances in the
figure are
(R01, R02, R12) for the model and
(d01,d02,d12) for the image object. The overall scaling the model
needs to undergo to fit the image is defined as s. The vertical heights from
the image plane of the aligned model's two vertices are (H1,H2) before
scaling or (h1,h2) after scaling. The parameters in
Figure are computed using Equations ,
and :
The intermediate variables are defined in
Equations , , and and :
We then solve for the rotation matrix using the intermediate matrices
A and B using Equation and Equation :
where x01, x02, y01, y02 are 2D coordinates
relative to a coordinate system centered at the position of the left eye,
![]() :
:
| x01=i1x - i0x | (4.12) | ||
| x02=i2x - i0x | (4.13) | ||
| y01=i1y - i0y | (4.14) | ||
| y02=i2y - i0y | (4.15) |
The rotation matrix, R, can then be computed using Equation :
The translation vector, t, is computed simply by translating the centered
coordinate system to the position of ![]() .
The translation in the depth
dimension is irrelevant and can be omitted since scaling is directly
controlled by s (orthographic projection is not scaled by depth):
.
The translation in the depth
dimension is irrelevant and can be omitted since scaling is directly
controlled by s (orthographic projection is not scaled by depth):
| (4.17) |
Once the values of R and t have been determined, any 3D model point can be
transformed and the points
![]() will align with
the image points
will align with
the image points
![]() .
The transformation from
model point to image point is thus:
.
The transformation from
model point to image point is thus:
Of course, the iz value is only a relative measurement of the depth of the model point. It is useful, however, for keeping track of the relative depth of the model point with respect to other model points.
Note that this is a direct solution of the WP3P problem save for one
ambiguity: the ![]() value in the computation of (h1,h2) in
Equation . This ambiguity allows two possible alignments of
the model to the image points. The 3D face can either line up by facing
towards or away from the viewer. Of course, we know that the face is
projecting onto the image from behind the image plane and is facing the viewer
(or ``camera-man''). Thus we select either + or - in
Equation to assure that the 3D model is actually behind
the image plane and is facing towards the camera. This ambiguity is resolved
by computing the normal of the nose. In other words, a vector protruding from
the nose on the model is introduced and undergoes the transformation in
Equation . We begin by calculating
Equation with a '+'. We note the relative depth value of
the vector iz. If the vector is pointing away from the viewer (its tip is
farther from the image plane than its base or, equivalently, has a larger
iz value) then the model is pointing away from the camera and we repeat the
computation with a '-' in Equation .
value in the computation of (h1,h2) in
Equation . This ambiguity allows two possible alignments of
the model to the image points. The 3D face can either line up by facing
towards or away from the viewer. Of course, we know that the face is
projecting onto the image from behind the image plane and is facing the viewer
(or ``camera-man''). Thus we select either + or - in
Equation to assure that the 3D model is actually behind
the image plane and is facing towards the camera. This ambiguity is resolved
by computing the normal of the nose. In other words, a vector protruding from
the nose on the model is introduced and undergoes the transformation in
Equation . We begin by calculating
Equation with a '+'. We note the relative depth value of
the vector iz. If the vector is pointing away from the viewer (its tip is
farther from the image plane than its base or, equivalently, has a larger
iz value) then the model is pointing away from the camera and we repeat the
computation with a '-' in Equation .
The end result is a mapping from the 3D model to the image which lines up the eyes and the nose optimally.