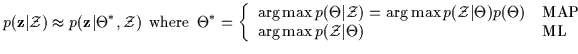In Bayesian inference, the probability density function of a vector
![]() is typically estimated from a training set of such vectors
is typically estimated from a training set of such vectors
![]() as shown in Equation 5.1 [5].
as shown in Equation 5.1 [5].
By integrating over ![]() ,
we are essentially integrating over all
the pdf models possible. This involves varying the families of pdfs
and all their parameters. However, often, this is impossible and
instead a family is selected and only its parametrization
,
we are essentially integrating over all
the pdf models possible. This involves varying the families of pdfs
and all their parameters. However, often, this is impossible and
instead a family is selected and only its parametrization ![]() is
varied. Each
is
varied. Each ![]() is a parametrization of the pdf of
is a parametrization of the pdf of ![]() and
is weighted by its likelihood given the training set. However,
computing the integral 5.1 is not always straightforward and Bayesian inference is
approximated via maximum a posteriori (MAP) or maximum likelihood (ML)
estimation as in Equation 5.2. The EM algorithm is
frequently utilized to perform these maximizations.
and
is weighted by its likelihood given the training set. However,
computing the integral 5.1 is not always straightforward and Bayesian inference is
approximated via maximum a posteriori (MAP) or maximum likelihood (ML)
estimation as in Equation 5.2. The EM algorithm is
frequently utilized to perform these maximizations.