COMS 4771 Fall 2025
This is the website for the course entitled “Machine Learning” for the Fall 2025 semester.
Basic course information
- Lecture times: Tue/Thu 1:10pm–2:25pm (Section 1), 2:40pm–3:55pm (Section 2)
- Lecture venue: 451 Computer Science Building
- Instructor: Daniel Hsu
- Teaching assistants: Ashley Seo, Case Schemmer, Eric Shao, Grace Yoon, Keir Dorchen, Sejal Mittal, Swapneel Bhatt
- Links: Courseworks, Ed Discussion, Gradescope, Help, Office Hours, Schedule, Syllabus
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Course schedule
Each (on-line) “quiz” can be found on Gradescope after 4pm on the day it is assigned. The quizzes are not timed, but they must be submitted by the deadline (11:59pm of the due date).
As announced in lecture, you do not have to submit the other homework assignments (HW0, HW1, etc.).
If you want the version of the slides with one slide per page, remove “-handout” from the URL.
Syllabus
Jump to: Description, Learning goals, Prerequisites, Topics, Requirements, Disability services, Academic rules of conduct
Description
COMS 4771 is a graduate-level introduction to machine learning. The course introduces basic statistical principles and algorithmic paradigms of supervised machine learning.
- COMS 4771 is a “first course” in machine learning. It is intended for students without any background in or prior experience with machine learning or artificial intelligence.
- COMS 4771 is not a “theory course”. For a course on the theoretical foundations of learning, consider COMS 4252 or COMS 4773.
Learning goals
- Familiarity with, and ability to reason about, core machine learning problems and methods
- Ability to adapt machine learning methods for use in some specific applications
Course prerequisites
List of prerequisites
There are several prerequisites for this course.
- You must be well-versed in multivariate calculus, linear algebra, and basic probability, all at the undergraduate level.
- Calculus: MATH UN1201, MATH UN1202, MATH UN1205, APMA E2000 or equivalent
- Linear algebra: COMS W3251, APMA E3101, APMA E2101, MATH UN2010 or equivalent
- Probability: STAT UN1201, STAT GU4001, STAT GU4203, IEOR 3658 or equivalent
- You must be comfortable with using (and writing programs in) Python to process and analyze data, and be familiar with basic algorithmic design and analysis.
- Data structures: COMS W2132, COMS W3134, COMS W3136, COMS W3137 or equivalent
- You must have mathematical maturity.
- Some classes that help build mathematical maturity: COMS W3261, CSOR W4231 or equivalent
Note: The list of prerequisites on Vergil and SIS is incorrect. In particular, COMS 3770 is not a substitute for any of the prerequisites listed above.
Rationale
Machine learning is a confluence of ideas from many disciplines, including computer science, optimization, physics, and statistics. However, the common language of machine learning is rooted in the mathematical subjects of calculus, linear algebra, and probability. This language is used both to describe basic methods of machine learning, as well as to describe their underlying principles.
While many basic machine learning methods have been implemented in software packages, adapting these methods to new applications may require knowledge of their inner workings, and the ability to read, write, and reason about programs.
Despite the common language used in machine learning, the descriptions of the core methods, problems, and principles in textbooks, software manuals, research articles, and lecture slides/notes are quite varied and possibly even contradictory. Machine learning is a relatively young field and is constantly changing. Mathematical maturity is essential to make sense of this “wild west”.
Resources on prerequisites
Review notes for some of the prerequisites are available here.
Additional online resources for some course prerequisites are as follows.
- Multivariable calculus
- Linear algebra
- Probability
- Programming in Python with NumPy
If you find this material unfamiliar, you should not take COMS 4771.
Course topics
The anticipated list of topics is as follows. The topics may not correspond one-to-one to lectures.
- Statistical framework for supervised machine learning
- Basic prediction theory
- Evaluation criteria (e.g., risk, calibration, bias)
- Algorithmic paradigms for supervised machine learning
- Memorization and space partitioning
- Deriving algorithms based on statistical models
- Numerical optimization
- Some modeling techniques
- Statistical models
- Feature maps, kernels, neural networks
- Regularization
Course requirements
You are expected to attend lectures, complete reading and homework assignments, and complete in-class exams.
Reading assignments
Lectures will be mostly self-contained; required reading assignments will be posted alongside the course schedule. Pointers to optional reading from (some of) the following texts will also be given.
- A Course in Machine Learning (CML) by Daumé
- Pattern Classification (PC) by Duda, Hart, and Stork
- Patterns, Predictions, and Actions (PPA) by Hardt and Recht
- Mathematics for Machine Learning (MML) by Deisenroth, Faisal, and Ong
- The Elements of Statistical Learning (ESL) by Hastie, Tibshirani, and Friedman
- Boosting: Foundations and Algorithms (BFA) by Schapire and Freund
All of these texts are available online, possibly through Columbia University Libraries.
Homework assignments
Homework will be assigned throughout the semester. The purpose of these assignments is to help you learn the course material through practice and active engagement. (I suspect many students learn more effectively this way than via “passive learning” alone.)
The types of homework assignments may include: short online multiple-choice/short answer quizzes (on Gradescope), word problems, algorithm implementation and experimentation, data analysis.
Model solutions for most of the assignments will be provided so that students can evaluate their own solutions. Specific feedback from the course staff may be provided during office hours, or upon submission of solutions to Gradescope.
In-class exams
The three in-class exams will take place during the lecture on the following dates.
- September 30, 2025
- October 30, 2025
- December 4, 2025
You must take all exams during the lecture times for the section in which you are registered.
The kinds of questions on the exams may be similar those from the homework assignments, but naturally adjusted (e.g., scaled down) for the format of a time-constrained in-class exam. You will not be asked to write any large amount of Python code, but you could be asked to write some short pseudocode or answer questions about small snippets of code.
The material covered by each exam is cumulative but emphasizes the material since the last exam.
Grading
Your final grade is based on the scores you earned for the in-class exams and homework assignments. Let Ei denote your score (out of 100) for in-class exam #i (for i ∈ {1, 2, 3}), and let H denote your total score (out of 100) for the homework assignments. Then your overall score (out of 100) is 0.36 × (E1 + E2 + E3) − 0.18 × min{E1, E2, E3} + 0.1 × H. (Your lowest in-class exam score is counted half as much as each of the others.)
As required by the university, your overall score will be discretized to determine your final letter grade (one of A+, A, A−, B+, B, B−, C+, C, C−, D, F). The discretization process will take into account the distribution of overall scores across all students in the class (i.e., the final grade is “curved”).
Make-up policy
There are no “make-up” homework assignments or exams available. Do not enroll in the course if you do not expect to be able to take the in-exams at the scheduled times.
If you miss the deadline for submitting a homework assignment due to a medical or family emergency, or a religious activity, then fill out the following form (as soon as possible) and it will be excused: https://forms.gle/WJXGQqDUNoQ3Zmtv7.
If you miss an exam due to a medical or family emergency, you may have the following options (subject to the rules of your degree program). You may be granted an “incomplete” for the course; the “incomplete” grade is removed after you complete a comparable exam in a future offering of this course (to be arranged with the pertinent instructors). Or, you may “withdraw” from the course, in which case you will receive a “W” grade instead of a standard letter grade for the course. Please consult with an academic advising staff member to determine which (if any) of these options are available to you.
Disability services
If you require accommodations or support services from Disability Services, please make necessary arrangements in accordance with their policies within the first two weeks of the semester.
Academic rules of conduct
You must adhere to the Academic Honesty policy of the Computer Science Department, as well as the course-specific policies described below.
All exams must be completed individually. Collaboration or discussion between students on exams is not permitted. Use of abaci, electronic calculators, phones, the internet, laptop computers, desktop computers, tablets, “smart” watches, AI tools, AR/VR goggles, etc. during exams is not permitted. Use of any items explicitly declared by the instructor to be unauthorized during exams is not permitted.
You are welcome to discuss homework with other students in the class, but any homework you submit must be your own and written-up by yourself in your own words. Any use of AI tools on homework must be explicitly declared.
Violation of any portion of these policies will result in a penalty to be assessed at the instructor’s discretion (e.g., a zero grade for the assignment in question, a failing letter grade for the course), even for a first offense.
Getting help
Contacting the course staff
Please post a message on Ed Discussion to contact the course staff. You may mark the message as “private” if appropriate. Do not email the TAs directly.
Asking questions
You are encouraged to use office hours and message board to discuss and ask questions about course material and reading assignments, and to ask for high-level clarification on and possible approaches to homework problems.
If you need to ask a detailed question specific to your solution on a homework problem, please do so on the message board and mark the post as “private” so only the instructors can see it. This helps other students who may wish to avoid “spoilers”.
Questions, of course, are also welcome during lecture. If something is not clear to you during lecture, there is a chance it may also not be clear to other students. So please raise your hand to ask for clarification during lecture. Some questions may need to be handled “off-line”; we will do our best to handle these questions in office hours or on message board.
If you have a regrade request for an exam, please see the policies here.
Office hours
Office hour schedule
- Daniel: Tue 4–6pm (conference room in Mudd 4th floor DSI suite, or 426 Mudd)
- TA office hours are, by default, held in the TA room on the first floor of Mudd.
- Please watch for announcements on Ed Discussion for changes to the office hours schedule.
- It is recommended to reload the page to get the latest version of the office hour schedule from Google Calendar.
Where is the TA room?
As you exit the elevators on the first floor of Mudd, the couches will be in front of you. Turn right and you will come to a corridor: turn right again. The TA room is the first door on the left.
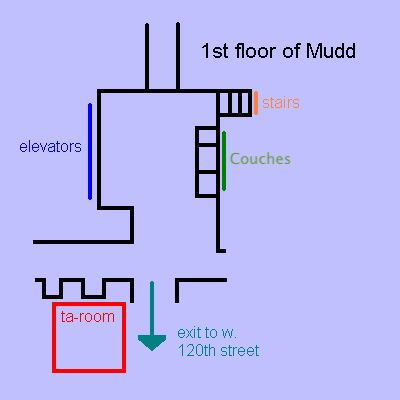
(The above information and image were adapted from an archive copy of https://ia.cs.columbia.edu/tamap.shtml.)
Enrollment
Please see the CS Course Registration Policy. I am not managing the waitlists myself (even though it may appear as “Instructor Managed” on Vergil), and I will not be able to respond to questions about the waitlist or enrollment issues.
- If you enroll in the course after the start of the semester, it is your responsibility to “catch up” with any course activites (e.g., lectures, assignments) that you may have missed prior to your enrollment. It will not be possible to provide special accommodations to late enrollers.
- There are two sections of COMS 4771 in Fall 2025. They differ only in the lecture times; the instruction/material is the same in both sections. However, you must take all in-class exams during the lecture times for the section in which you are registered. Do not enroll in the course if you cannot take the in-class exams at these times.
If you are interested in auditing the course, you are welcome to sit in on the lectures as long as there are many open seats and you do not prevent a registered student from being able to sit. However, I will not add you to Courseworks, etc.