 |
Pablo A. Duboue
Department of Computer Science
Columbia University
pablo@cs.columbia.edu
Kathleen R. McKeown
Department of Computer Science
Columbia University
kathy@cs.columbia.edu
In a standard generation pipeline [24], a content planner is responsible for the higher level document structuring and information selection. Any non-trivial multi-sentential/multi-paragraph generator will require a complex content planner, responsible for deciding, for instance, the distribution of the information among the different paragraphs, bulleted lists, and other textual elements. Information-rich inputs require a thorough filtering, resulting in a small amount of the available data being conveyed in the output. Furthermore, the task of building a content planner is normally recognized as tightly coupled with the semantics and idiosyncrasies of each particular domain.
The AI planning community is aware that machine learning techniques can bring a general solution to problems that require customization for every particular instantiation [19]. The automatic (or semi-automatic) construction of a complete content planner for unrestricted domains is a highly desirable goal. While there are general tools and techniques to deal with surface realization [7,15] and sentence planning [27], the inherent dependency on each domain makes the content planning problem difficult to deal with in a unified framework; it requires sophisticated planning methodologies, for example, DPOCL [30]. The main problem is that the space of possible planners is so large. For example, in the experiments reported here, it contains all the possible orderings of 82 units of information.
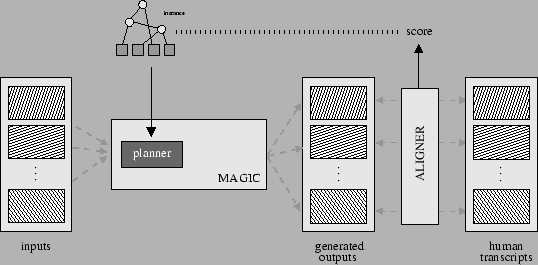
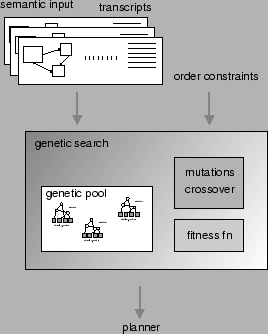
In this paper, we present a technique for learning the structure of tree-like planners, similar to the one manually built for our MAGIC system [16]. The overall architecture for our learning of content planners is shown in Figure 1. As input we utilize an aligned corpus of semantic inputs aligned with human-produced discourse. We also take advantage of the definition of the atomic operators (messages) from our existing system. We learn these tree-like planners by means of a genetic search process. The plan produced as output by such planners is a sequence of semantic structures, defined by the atomic operators. The learning technique is complementary to approaches proposed for generation in summarization [11], that utilize semantically annotated text to build content planners.
Our domain is the generation of post cardiac-surgery medical reports or briefings. MAGIC produces such a briefing given the output from inferences computed over raw data collected in the operating room [10]. Since we have a fully operational system, it serves as a development environment in which we can experiment with the automatic reproduction of the existing planner. Once the learning system has been fully developed, we can move to other domains and learn new planners. We will also eventually experiment with learning improved versions of the MAGIC planner through evaluation with health care providers.
The corpus we are using in our experiments consists of the data collected in the evaluation reported in [17]. Normal work-flow in the hospital requires a medical specialist to give briefings when the patient arrives in the Intensive Care Unit. In our past evaluation, 23 briefings were collected and transcribed and these were used, along with the admission note, another gold standard, to quantify the quality of MAGIC output (100% precision, 78% recall).
In our work, we align the briefings with the semantic input for the same patient; this input can be used to produce MAGIC output for this patient. In a later stage of the learning process we also align system output with the briefings. An example of the semantic input, system output and the briefing is given in Figure 6. Note that there are quite a few differences among them. In particular, the briefings (c) are normally occurring speech. Aside from being much more colorful than our system output, they also include a considerable amount of information not present in our semantic input. And there is also some information present in our system that is not being said by the doctors. This is because at the time the briefing is given, data such as the name of the patient is available in paper format to the target audience.
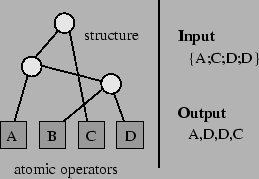
The planner currently used in the MAGIC system was developed with efficiency in mind, but it lacks flexibility and it is more appropriate for formal speech or text. It has a total of 274 operators; 192 are structure-defining (discourse or topic levels) and 82 are data defining (atomic level) operators1. An atomic operator may select, for example, the age of the patient, querying the semantic input for the presence of a given piece of information and instantiating of some semantic structures. Those semantic structures can be as complex as desired, referring to constants, and function invocations. It is also possible for an atomic operator to span several nodes in the output plan if its specified data is multi-valued. During the execution of the planner, the input is then checked for the existence of the datum specified by the operator. If there is data available, the corresponding semantic structures are inserted in the output. The internal nodes, on the other hand, form a tree representing the discourse plan; they provide a structural frame for the placement of the atomic operators. Thus, the execution of the planner involves a traversal of the tree while querying the input and instantiating the necessary nodes.
Our task is to learn a tree representing a planner that performs as well as the planner developed manually for MAGIC. We explore the large space of possible trees by means of evolutionary algorithms. While we use them to learn a content planner, they have also proven useful in the past for implementing content planners [18]. Note that both tasks are different in nature, as ours is done off-line, only once through the life-time of a system, while their use of the GA search will be performed on every execution of the system.
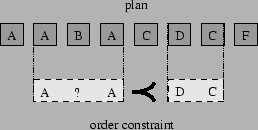
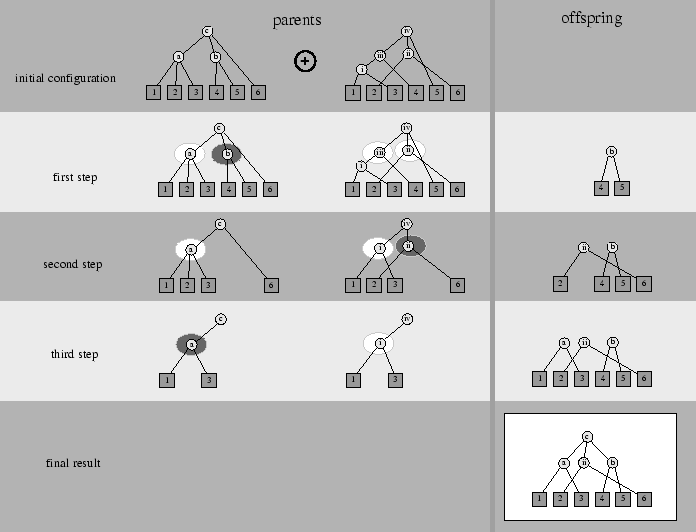
In a genetic search, a population of putative solutions, known as chromosomes, is kept. In our case, each chromosome is a tree representing a possible content planner. Figure 2 shows an example planner and how it realizes semantic input when data is missing (B) or duplicated (D). In each cycle, chromosomes are allowed to reproduce themselves, with well-fitted chromosomes reproducing more often. Normally two types of reproductive mechanisms are provided: mutations (that produces a new chromosome by modifying an old one) and cross-over (that produces a new chromosome by combining two existing ones, its `parents').
 |
Each chromosome has an associated fitness value, that
specifies how well or promising the chromosome looks. A main
contribution of our work is the use of two corpus-based fitness
functions, ![]() and
and ![]() . We use an approximate evaluation function,
. We use an approximate evaluation function,
![]() that allows us to efficiently determine whether order
constraints over plan operators are met in the current chromosome. We
use the constraints we acquired on this domain
[5],2 Figure 4). These constraints relate
sets of patterns by specifying strict restrictions on their relative
placements. Note that a chromosome that violates any of these
constraints ought to be considered invalid. However, instead of
discarding it completely, we follow Richardson and colleagues [26] and
provide a penalty function, in order to allow the useful information
contained in it to be preserved in future generations.
that allows us to efficiently determine whether order
constraints over plan operators are met in the current chromosome. We
use the constraints we acquired on this domain
[5],2 Figure 4). These constraints relate
sets of patterns by specifying strict restrictions on their relative
placements. Note that a chromosome that violates any of these
constraints ought to be considered invalid. However, instead of
discarding it completely, we follow Richardson and colleagues [26] and
provide a penalty function, in order to allow the useful information
contained in it to be preserved in future generations.
Once a tree has been evolved so that it conforms to all order
constraints, we switch to a computationally intensive fitness
function, ![]() . In this last stage, we use MAGIC to generate output
text using the current chromosome. We then compare that text against
the briefing produced by the physician for the same patient. We use
alignment to measure how close the two texts are. This procedure is
shown in Figure 5. The fitness is then the average
of the alignment scores produced for a set of semantic inputs. This
approach avoids some of the problems typically found with gold
standards. By averaging the fitness function over different semantic
inputs, it evaluates the system against different subjects (since each
briefing was produced by a different person) in one fell swoop. By
capturing similarity in a scalar value (the average itself), it avoids
penalizing the system for small discrepancies between system output
and gold standard.
. In this last stage, we use MAGIC to generate output
text using the current chromosome. We then compare that text against
the briefing produced by the physician for the same patient. We use
alignment to measure how close the two texts are. This procedure is
shown in Figure 5. The fitness is then the average
of the alignment scores produced for a set of semantic inputs. This
approach avoids some of the problems typically found with gold
standards. By averaging the fitness function over different semantic
inputs, it evaluates the system against different subjects (since each
briefing was produced by a different person) in one fell swoop. By
capturing similarity in a scalar value (the average itself), it avoids
penalizing the system for small discrepancies between system output
and gold standard.
For computing each pairwise alignment, we use a global
alignment3with affine gap penalty, the Needleman-Wunsch algorithm, as defined
by Durbin et al. [6]. These alignments do not allow
flipping (i.e., when aligning ![]() -
-![]() -
-![]() and
and ![]() -
-![]() -
-![]() they
will align both
they
will align both ![]() s but neither
s but neither ![]() nor
nor ![]() 4) and capture the notion of ordering more
appropriately for our needs. We adapted their algorithm by using the
information content5 of words, as measured in a 1M-token
corpus of related discourse, to estimate the goodness of substituting
one word by another.
4) and capture the notion of ordering more
appropriately for our needs. We adapted their algorithm by using the
information content5 of words, as measured in a 1M-token
corpus of related discourse, to estimate the goodness of substituting
one word by another.
An important point to note here is that both ![]() and
and ![]() are
data-dependent, as they analyze the goodness or badness of
output plans, i.e., sequences of instantiated atomic operators.
They require running the planner multiple times in order to do the
evaluation. We do this because, for one instance, as the planning
process may delete (because there is no data available) or duplicate
nodes (because of multi-valued data).
are
data-dependent, as they analyze the goodness or badness of
output plans, i.e., sequences of instantiated atomic operators.
They require running the planner multiple times in order to do the
evaluation. We do this because, for one instance, as the planning
process may delete (because there is no data available) or duplicate
nodes (because of multi-valued data).
An advantage of ![]() is that it can be tested on a much wider range
of semantic inputs than it is trained on6.
is that it can be tested on a much wider range
of semantic inputs than it is trained on6.
We define three mutation operators and one cross-over operation. The mutations include node insertion, which picks an internal node at random and moves a subset of its children to a newly created subnode, and node deletion, which randomly picks an internal node different from the root and removes it by making its parent absorb its children. Both operators are order-preserving. To include order variations, a shuffle mutation is provided that randomly picks an internal node and randomizes the order of its children. The cross-over operation is sketched in Figure 3. We choose an uniform cross-over instead of a single or double point one following Syswerda [29].
 |
The framework described in the paper was implemented as follows: We employed a population of 2000 chromosomes, discarding 25% of the worse-fitted ones in each cycle. The vacant places were filled with 40% chromosomes generated by mutation and 60% by cross-over. The mutation operator was applied with a 40% probability of performing a node insertion or deletion and 60% chance of choosing a shuffle mutation. The population was started from a chromosome with one root node connected to a random ordering of the 82 operators and then nodes were inserted and shuffled 40 times.7
The search algorithm was executed by 20 generations in 8d 14h (total CPU time, using about 20 machines in parallel to compute the verbalizations8). The best chromosome obtained was compared with the current planner in an intrinsic evaluation, described below.
Given the size of both planners, an automatic evaluation process was needed. We use a metric that captures the structural similarities between the two planners. In our metric, we recorded for each pair of atomic operators, the list of internal nodes that dominates both of them. This information was used to build a matrix of counts with the size of such lists (for example, in the original planner ``age-node'' and ``name-node'' are both dominated by ``demographics-node'', ``overview-node'' and ``discourse-node''; therefore, their entry in the table is the size of that list, i.e., 3). Given the fact that both the MAGIC planner and our learned planners have the same set of atomic operators, it is possible to score their similarity by subtracting the associated matrices and then computing the average of the absolute values of this difference matrix. Lower values will indicate closer similarity, with a perfect match receiving the value of 0. Applying this metric to the MAGIC planner and our best planner we obtained the score 1.16. We compare this score against 2000 random planners from the initial population of the genetic search. Taking the average of their scores we obtain 3.08.
Finally, if we compare our learned planner against the random ones we obtain 2.92. We clearly improve over this baseline. An example of the learned planner is seen in Figure 6 (d).
|
In recent years, there has been a surge of interest in empirical
methods applied to natural language generation [4]. Some work
on content planning also deals with constructing plans from
semantically annotated input. Kan and McKeown [11] use an
![]() -gram model for ordering constraints. The approach is complementary
and suitable for scenarios where semantic annotation is an inexpensive
task, such as in the automatic summarization tasks presented in that
paper. Also working on order constraints for summarization,
Barzilay et al. [1] collect a corpus of ordering preferences
among subjects and use them to estimate a preferred ordering.
-gram model for ordering constraints. The approach is complementary
and suitable for scenarios where semantic annotation is an inexpensive
task, such as in the automatic summarization tasks presented in that
paper. Also working on order constraints for summarization,
Barzilay et al. [1] collect a corpus of ordering preferences
among subjects and use them to estimate a preferred ordering.
Evolutionary algorithms were also employed be Mellish et al. [18] for content planning purposes. While their intention was to push stochastic search as a feasible method for implementing a content planner and we pursue the automatic construction of the planner itself, both systems produce a tree as output. Our system, however, uses a corpus-based fitness function, while they use a rhetorically-motivated heuristic function with hand-tuned parameters.
Our approach is similar to techniques employed in evolutionary algorithms to implement general purpose planners,such as SYNERGY [21]; or to induce grammars [28]. In general, all these approaches are deeply tied to Genetic Programming [13], that deals with the issue of how to let a computer program itself.
Our two-level fitness-function employs a lower-order function for the initial approximation of solutions in a process similar to the one taken by Haupt [9] in a very different domain. This technique is appropriate for dealing with expensive fitness functions.
Finally, our approach with respect to human-produced discourse as gold standard is similar to Papinini et al. [23] as it avoids adhering to the particularities of one specific person or discourse.
The task of learning a general content planner such as Moore and Paris [20] is well beyond the state of the art. We have identified reduced content planning tasks that are feasible for learning. In learning for traditional AI planning, e.g., learning of planning operators [8], the focus is on reduced planning environments. The kind of discourse targeted by our current techniques has been identified in the past as rich in domain communication knowledge [12]. We identify such discourse as non-trivial scenarios in which investigation of learning in content planners is feasible.
In searching for an appropriate solution, a function that enables the computer tell from one solution to another is always needed. A second contribution of this paper falls in our proposed fitness function, motivated by generation issues behind the content planning in generation. By means of a powerful 2-level fitness function we obtain a 66% improvement over a random baseline (the one we started from) in just 20 generations.
The problem with costly functions is always execution time. By using
![]() , the constraint-based fitness function, we speed up the process,
computing only 55K regenerations from a total of 187.5K.
Our proposed cross-over and mutation operators are also well-suited
for the task and are the result of our analysis of the generation
domain.
, the constraint-based fitness function, we speed up the process,
computing only 55K regenerations from a total of 187.5K.
Our proposed cross-over and mutation operators are also well-suited
for the task and are the result of our analysis of the generation
domain.
Moreover, our technique achieves results without the need of extensive semantic annotation nor large sized input.
We are interested in extending this work by migrating it to other domains. We also plan to investigate the quality of the obtained planners head to head with our existing system. We want to see if it is possible to improve the existing planner (extensive evaluation with human subjects is required), as the newly obtained output resembles more normally occurring discourse in the domain.
Aside from the structure discovery, techniques are required for automatically detecting and building messages [25]. This task has been reported as extremely costly in the past [14]. We believe there are good chances of combining techniques such as [5] and [2] to semi-automate its creation process.