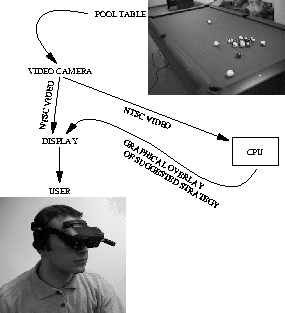
The wearable computer is the intended platform for the system and it
includes a head-mounted display, head-mounted video camera and central
processing unit. The layout and dataflow are depicted in
Figure ![]() .
.
The head-mounted camera is aligned with the user's head and the primary positions of the eyes (straight ahead). Thus, active control or foveation of the camera on the target (i.e. the pool table) is not necessary since the user's head direction will automatically direct the camera to areas of interest in the scene. This style of imaging is unique to wearable computers and head-mounted cameras and greatly reduces the task of a vision system.
Other input is not required since the system relies only on live video information for input. In addition, it is best if the user is not encumbered with any irrelevant input or output paraphernalia. The billiards game requires the use of both hands so any typed input would be unacceptable. In fact, any extra user-interaction beyond the usual play action is likely to be intrusive. Consequently, the algorithm must run autonomously. The system needs to act like an agent in the background and needs to be intelligent enough to make do with the input it has and to offer useful output. Essentially, the only real interaction from the user is from the natural steering and alignment of the head mounted camera.

Figure: The Head Mounted Video Unit
The display is head-mounted as well, and a video image of the camera's
input is continuously projected into each eye. Two CRTs are driven by
one video camera who's focal length is adjusted to avoid severe
angular modification of the user's expected visual field. The
head-mounted unit is shown in Figure ![]() . This
display creates an immersive environment since the user's perspective
is now identical to that of the vision algorithm. In addition, the user's
view is constrained in the same way as that of the vision algorithm. In
other words, eye movement is limited and the user will unconsciously
steer the video camera with head motion to achieve a satisfactory
video image projection on the display. This maintains a good quality
image for the vision algorithm. The use of the camera display as a
virtual ``third eye'' avoids alignment discrepancies between the
vision algorithm and the user's view point. Thus, any graphical
overlays that are produced as a result of video processing can be
directly projected to the user's eye display [6]. Although
the change of perspective induced by looking through a ``third eye''
(the camera) is unusual for first timers, we have found that users can
adapt quite quickly if the camera is only slightly offset from the
eyes [14]. We are currently investigating more advanced
display techniques which combine the graphical overlays directly onto
the user's natural binocular field. This is done using 3D estimation
techniques where a full 3D model of the world is recovered so that we
can reproject different views of it, customized to each eye's point of
view.
. This
display creates an immersive environment since the user's perspective
is now identical to that of the vision algorithm. In addition, the user's
view is constrained in the same way as that of the vision algorithm. In
other words, eye movement is limited and the user will unconsciously
steer the video camera with head motion to achieve a satisfactory
video image projection on the display. This maintains a good quality
image for the vision algorithm. The use of the camera display as a
virtual ``third eye'' avoids alignment discrepancies between the
vision algorithm and the user's view point. Thus, any graphical
overlays that are produced as a result of video processing can be
directly projected to the user's eye display [6]. Although
the change of perspective induced by looking through a ``third eye''
(the camera) is unusual for first timers, we have found that users can
adapt quite quickly if the camera is only slightly offset from the
eyes [14]. We are currently investigating more advanced
display techniques which combine the graphical overlays directly onto
the user's natural binocular field. This is done using 3D estimation
techniques where a full 3D model of the world is recovered so that we
can reproject different views of it, customized to each eye's point of
view.
The CPU can be a local computer fully contained in the wearable device or it may be a remote computer (or network of computers) which receives a transmitted version of the video signal and sends graphical information back to the user's display. However, since massive computational resources are assumed to be unavailable both locally and remotely, the algorithm must remain efficient enough to operate quickly on standard hardware. Initial development of the algorithm has been made on a 170 Mhz SGI R5000 Indy, the destination platform (a local wearable CPU) is a 150 Mhz Intel Pentium architecture with a 56001 DSP co-processor on the video digitizer board. These two systems have similar performance levels which we shall use to bound the complexity of the vision algorithm.