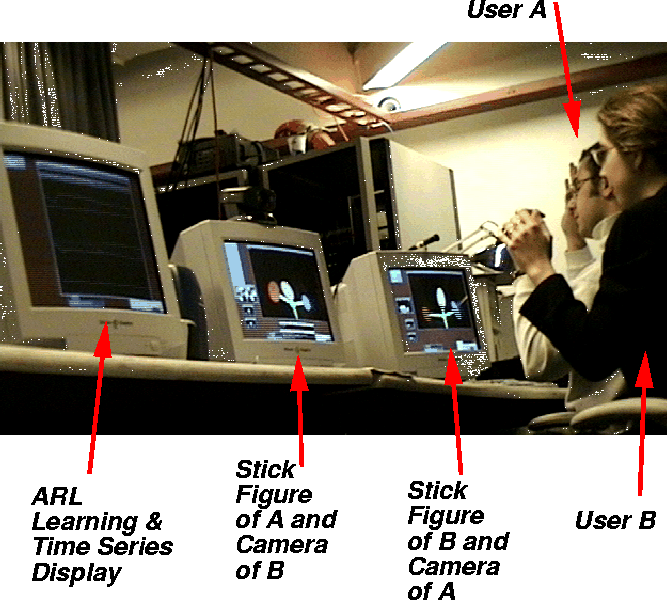
Figure 3.4 depicts the training environment. Here, two users are being observed by the system via two video cameras. Additionally, both users can see virtual representations of each other as blob and stick figures. Since this is a distributed RPC system, any number of users can be engaged in this type of interaction. Each user opens a display and a vision system and can select and view any of the other participants connected to the Action-Reaction Learning module. We will not discuss the multi-user case and will focus on single or 2-person cases exclusively. However, the perceptual framework (and the learning framework) is generalizable to large group interactions as well. In addition, in a third nearby display, the Action Reaction Learning system is running and plotting trajectories describing the gestures of both users in real-time.
In the testing environment, one of the two users will leave and disable his perceptual system. This will trigger the ARL system to start simulating his behaviour and interpolating the missing component of the perceptual space that he was previously triggering. This process should be transparent to the remaining user who should still feel (to a certain degree) that she is virtually interacting with the other human. Of course, only one video camera and one display is necessary at this point.