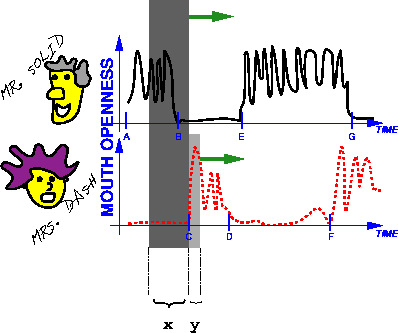
Action-Reaction Learning (ARL) involves temporal analysis of a (usually multi-dimensional) data stream. Figure 2.3 displays such a stream (or time series). Let us assume that the stream is being generated by a vision algorithm which measures the openness of the mouth [43]. Two such algorithms are being run simultaneously on two different people. One person generates the dashed line and the other generates the solid line.
Now, imagine that these two individuals are engaged in a conversation. Let us also name them Mr. Solid (the fellow generating the solid line) and Mrs. Dash (the lady generating the dashed line). Initially (interval A-B on the time axis), Mr. Solid is talking while Mrs. Dash remains silent. He has an oscillatory mouth signal while she has a very low value on the openness of the mouth. Then, Mr. Solid says something shocking and pauses (B-C). Mrs. Dash then responds with a discrete 'oh, I see' (C-D). She too then pauses (D-E) and waits to see if Mr. Solid has more to say. He takes the initiative and continues to speak (E). However, Mr. Solid continues talking non-stop for just too long (E-G). So, Mrs. Dash feels the need to interrupt (F) with a counter-argument and simply starts talking. Mr. Solid notes that she has taken the floor and stops to hear her out.
What Action-Reaction Learning seeks to do is discover the coupling
between the past interaction and the next immediate reaction of the
participants. For example, the system may learn a model of the
behaviour of Mrs. Dash so that it can predict and imitate her
idiosyncrasies. The process begins by sliding a window over the
temporal interaction as in Figure 2.3. The window looks at a
small piece of the interaction and the immediate reaction of
Mrs. Dash. This window over the time series forms the short term or
iconic memory of the interaction and it is highlighted with a dark
rectangular patch. The consequent reaction of Mrs. Dash and Mr. Solid
is highlighted with the lighter and smaller rectangular strip. The
first strip will be treated as an input ![]() and the second strip
will be the subsequent behavioural output of both Mr. Solid and
Mrs. Dash (
and the second strip
will be the subsequent behavioural output of both Mr. Solid and
Mrs. Dash (![]() ). To predict and imitate what either Mr. Solid
or Mrs. Dash will do next, a system system must estimate the future
mouth parameters of both (stored in
). To predict and imitate what either Mr. Solid
or Mrs. Dash will do next, a system system must estimate the future
mouth parameters of both (stored in ![]() ). As the windows slide
across a training interaction between the humans, many such
). As the windows slide
across a training interaction between the humans, many such
![]() pairs are generated and presented as training data to the
system. The task of the learning algorithm is to learn from these
pairs and form a model relating
pairs are generated and presented as training data to the
system. The task of the learning algorithm is to learn from these
pairs and form a model relating ![]() and
and ![]() .
It can then
generate a predicted
.
It can then
generate a predicted ![]() sequence whenever it observes a past
sequence whenever it observes a past
![]() sequence. This allows it to compute and play out the future
actions of one of the users (i.e. Mrs. Dash) when only the past
interaction of the participants is visible.
sequence. This allows it to compute and play out the future
actions of one of the users (i.e. Mrs. Dash) when only the past
interaction of the participants is visible.
Thus, the learning algorithm should discover some mouth openness
behavioural properties. For example, Mrs. Dash usually remains quiet
(closed mouth) while Mr. Solid is talking. However, after Solid has
talked and then stopped briefly, Mrs. Dash should respond with some
oscillatory signal. In addition, if Mr. Solid has been talking
continuously for a significant amount of time, it is more likely that
Mrs. Dash will interrupt assertively. A simple learning algorithm
could be used to detect similar ![]() data in another situation and
then predict the appropriate
data in another situation and
then predict the appropriate ![]() response that seems to agree
with the system's past learning experiences.
response that seems to agree
with the system's past learning experiences.
Note now that we are dealing with a somewhat supervised learning
system because the data has been split into input ![]() and output
and output
![]() .
The system is given a target goal: to predict
.
The system is given a target goal: to predict ![]() from
from ![]() .
However, this process is done automatically without
any manual data engineering. One only specifies a-priori a constant
width for the sliding window that forms
.
However, this process is done automatically without
any manual data engineering. One only specifies a-priori a constant
width for the sliding window that forms ![]() and the width of the
window of
and the width of the
window of ![]() (usually, the width will be 1 frame for
(usually, the width will be 1 frame for ![]() to conservatively forecast only a small step into the future). The
system then operates in an unsupervised manner as it slides these
windows across the data stream. Essentially, the learning uncovers a
mapping between past and future to later generate its best
possible prediction.
to conservatively forecast only a small step into the future). The
system then operates in an unsupervised manner as it slides these
windows across the data stream. Essentially, the learning uncovers a
mapping between past and future to later generate its best
possible prediction.