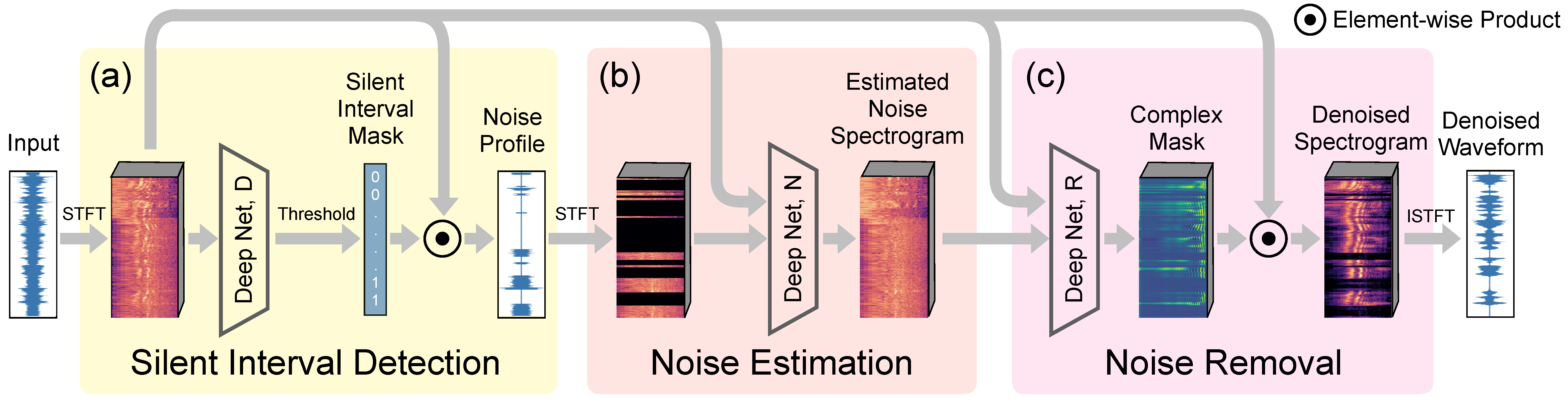
We introduce a deep learning model for speech denoising, a long-standing challenge in audio analysis arising in numerous applications. Our approach is based on a key observation about human speech: there is often a short pause between each sentence or word. In a recorded speech signal, those pauses introduce a series of time periods during which only noise is present. We leverage these incidental silent intervals to learn a model for automatic speech denoising given only mono-channel audio. Detected silent intervals over time expose not just pure noise but its time-varying features, allowing the model to learn noise dynamics and suppress it from the speech signal. Experiments on multiple datasets confirm the pivotal role of silent interval detection for speech denoising, and our method outperforms several state-of-the-art denoising methods, including those that accept only audio input (like ours) and those that denoise based on audiovisual input (and hence require more information). We also show that our method enjoys excellent generalization properties, such as denoising spoken languages not seen during training.
We thank the anonymous reviewers and referees for their constructive comments and helpful suggestions. This work was supported in part by the National Science Foundation (1717178, 1816041, 1910839, 1925157) and SoftBank Group.
We first show the comparison results on AudioSet dataset, DEMAND dataset and real-world audio recordings. When demonstrating with real-world recordings, we also include scenarios in which audiovisual denoising would fail because of the lack of frontal faces in video footage as well as scenarios in which multiple speakers present. Both are common in daily life. We then present examples of our denoising results in other languages, which are all resulted from our model trained solely in English. Lastly, we show two clips from the song "The Sound of Silence", as an echo of our title, to further demonstrate our model's ability to reduce non-stationary noise like music.
Here we show denoising results on synthetic input signals. The input signals are generated using audio clips in AVSPEECH as foreground speech and in AudioSet as background noise. With seven different input SNRs (from -10dB to 10dB), we compare the denoising results of our model with other methods.
Please note that here the Ours-GTSI method uses ground-truth silent interval labels. It is by no means a practical approach. Rather, it is meant to show the best possible (upper-bound) denoising quality when the silent intervals are perfectly predicted.
Here we provide comparison results similar to the previous section. Instead of using AudioSet data as background noise, here we use DEMAND, another dataset used in previous denoising works, as the source of background noise. All other setups are the same as in the previous section.
Here we provide denoising results on real-world recordings, in comparison to other methods. These examples are recorded in video with a single person from the front-facing view. Only the (mono-channel) audio signals in the recordings are provided to the denoising methods except for VSE, which requires audiovisual input (i.e., video footage is also provided as input).
Here we present more denoising results on real-world recordings. Unlike those presented above, the examples here all have human faces either blocked (e.g., by facial masks during the COVID-19 pandemic) or excluded from the camera's field of view. As a result, the audiovisual method (i.e., VSE) becomes not applicable, and our experiments show that VSE fails in these cases. We therefore exclude it from the compared methods.
Here we show denoising results on real-world recordings in which multiple people speak. Our method is able to suppress background noise while retaining the voices of all speakers.
Here we show our denoising results on speeches in other languages. The silent interval detection results are also presented. In these examples, our model is trained with speeches only in English, the same as that used in previous examples. No additional training is conducted.
Lastly, listen to "The Sound of Silence" processed by our method that listens to the sounds of silence!