Generating the Future with Adversarial Transformers
Carl Vondrick, Antonio Torralba
To appear in CVPR 2017
We learn models to generate the immediate future in video. This problem has two main challenges. Firstly, since the future is uncertain, models should be multi-modal, which can be difficult to learn. Secondly, since the future is similar to the past, models store low-level details, which complicates learning of high-level semantics. We propose a framework to tackle both of these challenges. We present a model that generates the future by transforming pixels in the past. Our approach explicitly disentangles the model’s memory from the prediction, which helps the model learn desirable invariances. Experiments suggest that this model can generate short videos of plausible futures. We believe predictive models have many applications in robotics, health-care, and video understanding.
Example Predictions
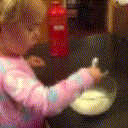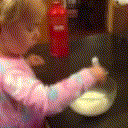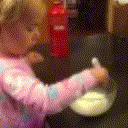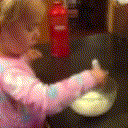
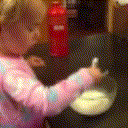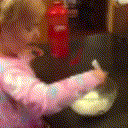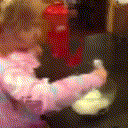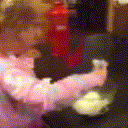
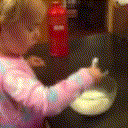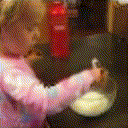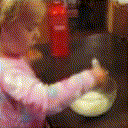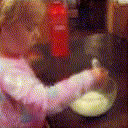
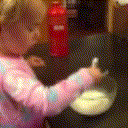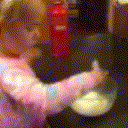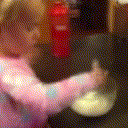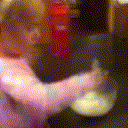
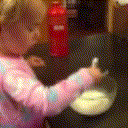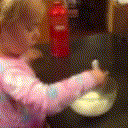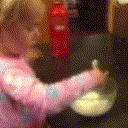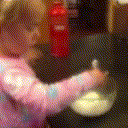
Below are some predictions on the held-out testing set. The input is 4 frames, and the model generates the next 12 frames (16 frames total).
- Input is the real video that is input to the model (only 4 frames).
- Adv+Trans is Adversarial with Transformations (our full method)
- Adv+Int is Adversarial with Predicting Intensities
- Reg+Trans is Regression with Transformations
- Reg+Int is Regression with Predicting Intensities
Generally, Adv+Trans generates the most motion that is sharp. Reg+Trans can generate motion, but it is often blurry.
| Input | Adv+Trans (us) | Adv+Int | Reg+Trans | Reg+Int |
|---|---|---|---|---|
 |
 |
 |
 |
 |
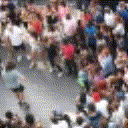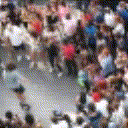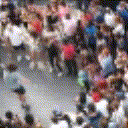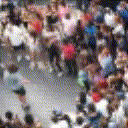 |
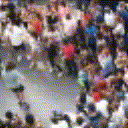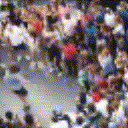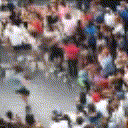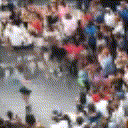 |
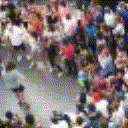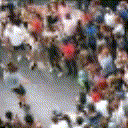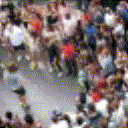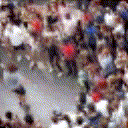 |
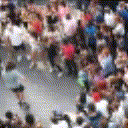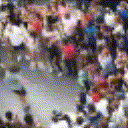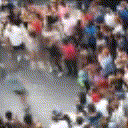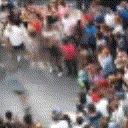 |
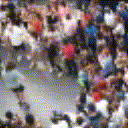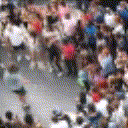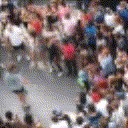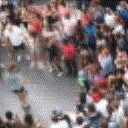 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
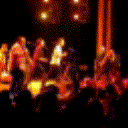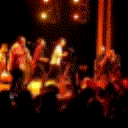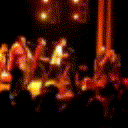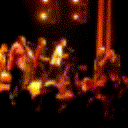 |
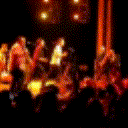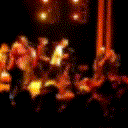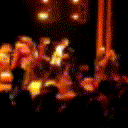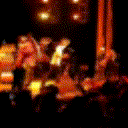 |
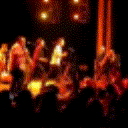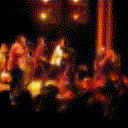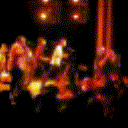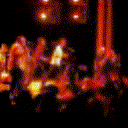 |
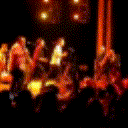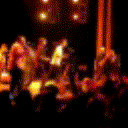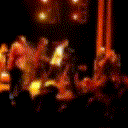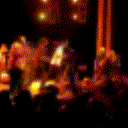 |
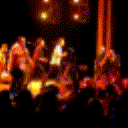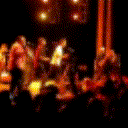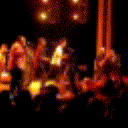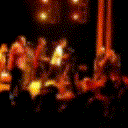 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Transformation Visualization
Below are some predictions on the held-out testing set while visualizing the internal transformation parameters. Colors indicate the average direction that the transformation is pointing to.
| Input | Adv+Trans (us) |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |