This page contains part of our CAPTCHA images dataset which is collected during our experiment for the project, I Am Robot: (Deep) Learning to Break Semantic Image CAPTCHAs . The work was developed at Network Security Lab, Columbia University and presented and published at Euro S&P 2016 and Blackhat Asia 2016.
Collaborators: Suphannee Sivakorn, Jason Polakis and Angelos D. Keromytis
Copyright and License:
All code and documentation copyright the project collaborators and Network
Security Lab at Columbia University, New York, NY, USA. CAPTCHA images
copyright the CAPTCHA services associated. The project released under
MIT License.
Feel free to use our dataset:
Below is a list of works/projects related to very interesting CAPTCHA and deep-learning
research and have cited this dataset/paper as a data source. Thank you!
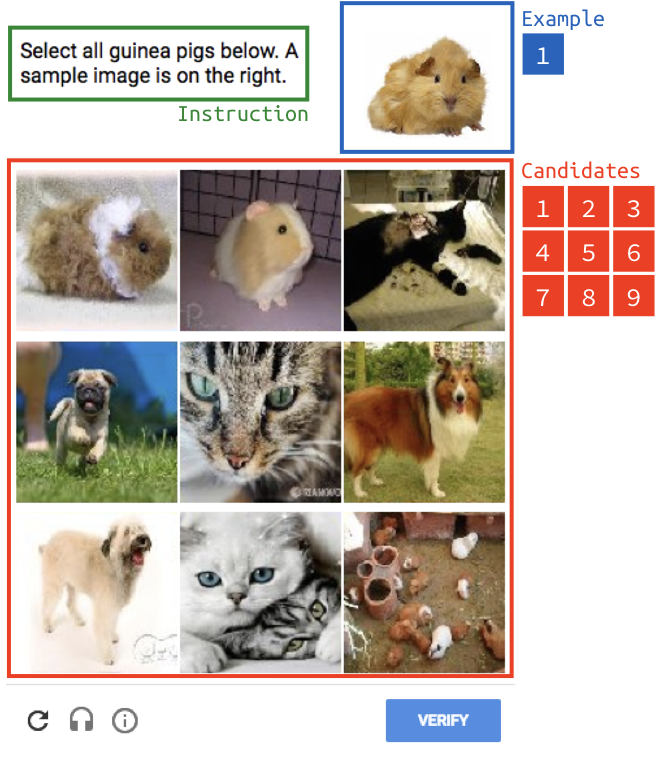
This dataset contains 700 CAPTCHA challenges (7,000 images) collected
from Google reCaptcha version
1.0 (early - mid 2015). One challenge contains 10 images i.e., one example image
and nine candidate images, and instruction text for human. Here is an example:
One folder is for one challenge set which contains:
In addition, we provide correct responses for these challenge sets, which is
located in file named "correct_responses.txt". These are responses that were
answered by human. Here is the format of the response:
The link to download is here: recapt_offline.tar.gz (513 MB).
This dataset contains 200 CAPTCHA challenges from
Facebook image CAPTCHA
during early - mid 2015. One challenge contains candidate 12 images and an
instruction. Here is an example:
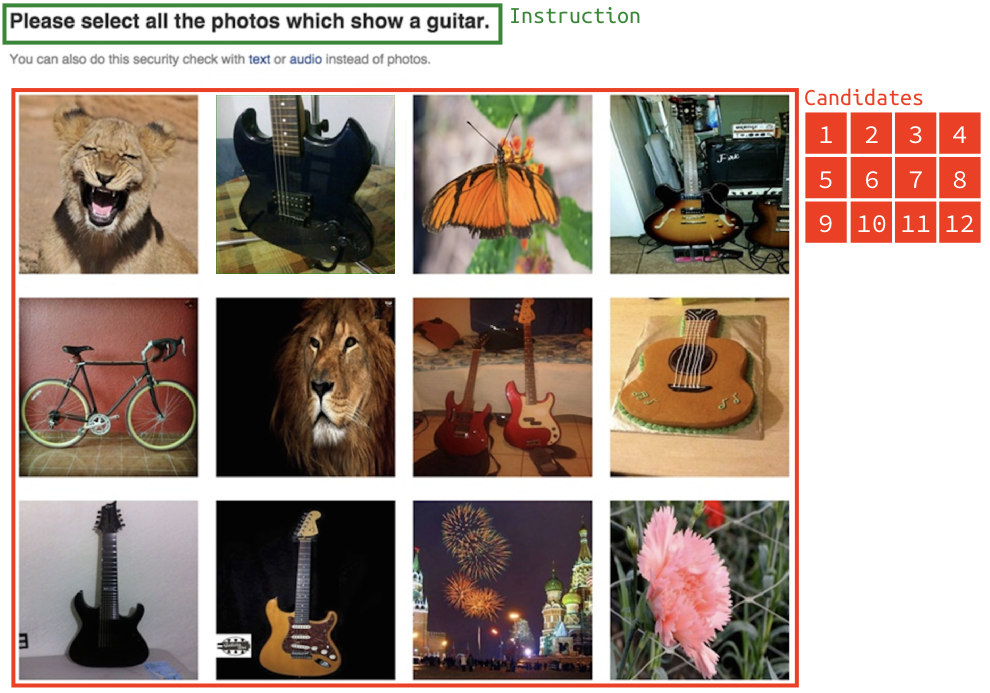
This dataset has the same format as Google reCaptcha Image Dataset.
The link to download is here: fb_offline.tar.gz (145 MB).
This dataset contains 3,000 images from Google reCaptcha version 1.0 same as above. However all images in this set are labeled by human accordingly to the reCAPTCHA available categories at that time. Since they are labeled, they are useful for training purpose. An image which does not belong to any category or unclear to be identified, is labeled as "unclear".
All files are saved in ".png" extension, and named as the following format: