The Columbia Games Corpus
The Columbia Games Corpus is a collection of 12 spontaneous task-oriented dyadic conversations elicited from native speakers of Standard American English (SAE), originally designed for a study of the intonational realization of given (old, previously-mentioned) vs. new information [Prince92]. Thirteen subjects (six female, seven male) participated in the study in October 2004. Eleven of the subjects participated in two sessions on different days, each time with a different partner.
Design of the Corpus
Subjects were paid to play a series of computer games requiring verbal communication between partners to achieve a joint goal of identifying and moving images on the screen. Participants sat facing each other in a soundproof booth with a curtain hanging between them, so that all communication would be by voice. Each subject was recorded on a separate channel to a DAT recorder using a Crown head-mounted close-talking microphone. All games were played on separate laptops whose screens were not visible to the other player. All keystrokes were captured and have been synchronized with the speech recordings and with the items appearing on the screen at the time.
The games involved tasks of increasing complexity in terms of the coordination necessary between the partners. For each game, a different set of objects appeared on each player's screen; successful completion of the game required players to describe and discuss the objects; they received points for each successfully completed subtask. In some games (Cards), players saw cards with one to three objects on them; the objects were chosen so that at least one possible description was largely sonorant (e.g. loom, M&M, mailman), for ease of subsequent intonational analysis. Objects were of two sizes (small or large) and various colors. In other games (Objects), only the objects themselves appeared on the screen. In each session, subjects were asked to play three versions of two different Cards Games and three versions of an Objects Game; these are described below. The order in which objects appeared on the screen was manipulated so that the same object reappeared at different intervals during the game, and the number of given objects on the screen at any time was varied systematically. Subjects were told that their goal was to accumulate as many points over the entire session as possible, since they would be paid additional money for each point they earned. Subjects spoke with one another quite spontaneously throughout the tasks. Sample screens for the various game types are shown in the following figure.
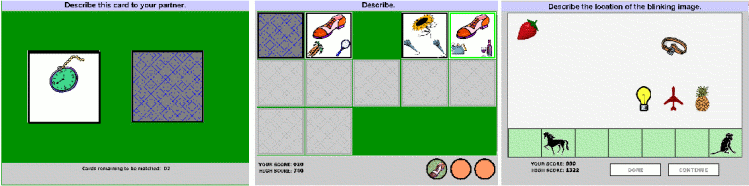
In the first type of Cards game, each player's screen displayed a pile of 9 to 12 cards. Player 1 was asked to describe the top card on her pile, while Player 2 was asked to search through his pile to find the same card, clicking a button to indicate success. This process was repeated until all cards in Player 1's deck were matched. In the second type of Cards game, each player saw a board of 15 cards on the screen, all initially face down. As the game began, the first card on one player's (the Describer's) board was automatically turned face up. The Describer was told to describe this card to the other player (the Searcher), who was to find a similar card from the cards on his board. If the Searcher could find a card depicting one or more of the objects described by the Describer, the players could decide whether to declare a match and thus receive points proportional to the numbers of objects matched on the cards. At most three cards were visible to each player at any time, with earlier cards being automatically turned face down. Players switched roles after each card was described and the process continued until all cards had been described. Subjects were given additional opportunities to earn points, based on other characteristics of the matched cards, to make the game more interesting and to encourage discussion.
In the final game type (Objects games), each player's laptop displayed a gameboard with 5-7 objects. Both players saw the same set of objects at the same position on the screen, except for one (the target). For the Describer, the target appeared in a random location among other objects on the screen. For the Follower, the target appeared at the bottom of the screen. The Describer was instructed to describe the position of the target on her screen so that the Follower could move his representation to the same location on his own. After players negotiated their best location match, they were awarded 1-100 points based on how well the Follower's target location matched the Describer's. The game proceeded through 14 tasks, with Describer and Follower alternating roles with each new task.
Annotation
Twelve sessions, totalling 9h 45m of dialogue were recorded, of which 5h 15m correspond to the Cards games and 4h 30m to the Objects games. On average, the first Cards game took 2m 3s, the second, 5m 58s, and the Objects game, 7m 12s, averaging roughly 46m of dialogue per session. Each session was downsampled to 16K. All files in the corpus were orthographically transcribed and words were aligned by hand by trained annotators in a ToBI [Silverman92, Beckman94, Jun05] orthographic tier using Praat to manipulate waveforms. Certain non-word vocalizations, including laughs, coughs and breaths, were marked in a ToBI miscellaneous tier, together with speech disfluencies and self repairs. The corpus contains 2240 unique words, with 73,800 words in total. Roughly two-thirds of the corpus has been intonationally transcribed using the ToBI conventions — the Objects games from all 12 sessions, and the Cards games from 4 sessions.
The corpus has also been labeled for additional phenomena, including cue (discourse) and non-cue (literal) use of some discourse markers, turn-taking behavior, and the form and function of questions:
- All lexical items potentially indicating agreement, (e.g. alright, gotcha, huh, mm-hm, okay, right, uh-huh, yeah, yep, yes, yup) have been labeled by three annotators, who separately determined whether each item was used to indicate acknowledgment/agreement, to mark the beginning or ending of a discourse segment, to indicate both acknowledgement/agreement and discourse segmentation, to backchannel, to stall in order to keep the floor, to check the interlocutor's state, to signal the completion of a task, or as a literal modifier.
- Turn exchanges in the Objects games have been manually classified into seven categories, following [Beattie82]. These were: smooth switches, overlaps, butting-ins, interruptions with and without overlap, and backchannels with and without overlap. There are approximately 2100 speaker turns in the Objects games and 1700 in the Cards games. All manuals for these annotations are available below.
References
[Beattie82] G. Beattie, Turn-taking and Interruption in Political interviews: Margaret Thatcher and Jim Callaghan Compared and Contrasted. Semiotica, 39(1):93-114, 1982.
[Beckman94] M. E. Beckman and J. Hirschberg, The ToBI Annotation Conventions. Ohio State University, 1994.
[Jun05] S. Jun. Prosodic Typology. Oxford University Press, 2005.
[Prince92] E. F. Prince, The {ZPG} Letter: Subjects, Definiteness, and Information-Status. In S. Thompson and W. Mann, editors, Discourse Description: Diverse Analyses of a Fund Raising Text, pages 295-325. John Benjamins B. V., Philadelphia, 1992.
[Silverman92] K. Silverman, M. Beckman, J. Pierrehumbert, M. Ostendorf, C. Wightman, P. Price and J. Hirschberg, ToBI: A Standard Scheme for Labeling Prosody. In Proceedings of ICSLP-92, pages 867-879, Banff, October 1992.
Annotation Manuals
- » Orthographic Transcription
- » Orthographic Alignment
- » ToBI Labeling Guidelines
- » Single Affirmative Cue Words
- » Turn Taking (PDF file)
- » Questions:
- • Identification
- • Form
- • Function