Generating Videos with Scene Dynamics
Carl Vondrick
MIT
Hamed Pirsiavash
University of Maryland Baltimore County
Antonio Torralba
MIT
NIPS 2016
Abstract
We capitalize on large amounts of unlabeled video in order to learn a model of scene dynamics for both video recognition tasks (e.g. action classification) and video generation tasks (e.g. future prediction). We propose a generative adversarial network for video with a spatio-temporal convolutional architecture that untangles the scene's foreground from the background. Experiments suggest this model can generate tiny videos up to a second at full frame rate better than simple baselines, and we show its utility at predicting plausible futures of static images. Moreover, experiments and visualizations show the model internally learns useful features for recognizing actions with minimal supervision, suggesting scene dynamics are a promising signal for representation learning. We believe generative video models can impact many applications in video understanding and simulation.
Video Generations
Below are some selected videos that are generated by our model. These videos are not real; they are hallucinated by a generative video model. While they are not photo-realistic, the motions are fairly reasonable for the scene category they are trained on.
Conditional Video Generations
We can also use the model to add animations to static images by training it to generate the future. Of course, the future is
uncertain, so the model
rarely generates the "correct" future, but we think the prediction has some plausibility.
More Results
For more results, check out the links below. Warning: The pages are fairly large (100 MB), so please browse on a computer and not a phone, and wait for the GIFs to download completely.
Video Representation Learning
Learning models that generate videos may also be a promising way to learn
representations. For example, we can train generators on a large repository of unlabeled videos, then fine-tune the discriminator on a small
labeled dataset in order to recognize some actions with minimal
supervision. We report accuracy on UCF101 and compare to other unsupervised learning methods for videos:
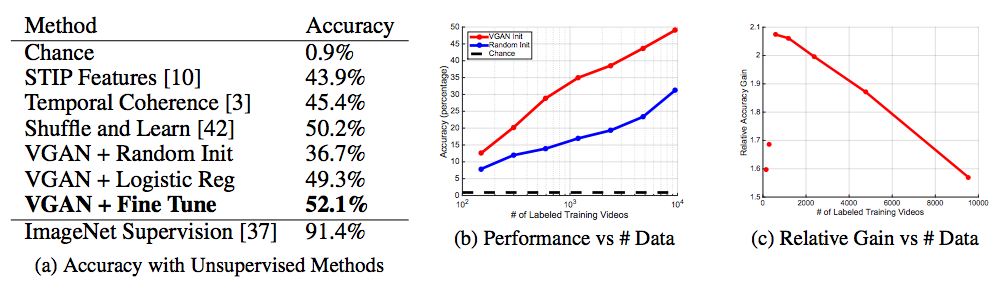
We can also visualize what emerges in the representation for predicting the
future. While not all units are semantic, we found there are a few hidden units that
fire on objects which are sources of motions, such as people or train
tracks. Since generating the future requires understanding moving objects, the network
may learn to recognize these objects internally, even though it is not
supervised to do so.
Hidden unit for "people"

Hidden unit for "train tracks"

The images above highlight regions where a particular convolutional hidden unit fires.
Brief Technical Overview
Our approach builds on generative image models that leverage adversarial learning, which we apply to
video. The basic idea behind the approach is to compete two deep networks against
each other. One network ("the generator") tries to generate a synthetic video, and another
network ("the discriminator") tries to discriminate synthetic versus real videos. The
generator is trained to fool the discriminator.
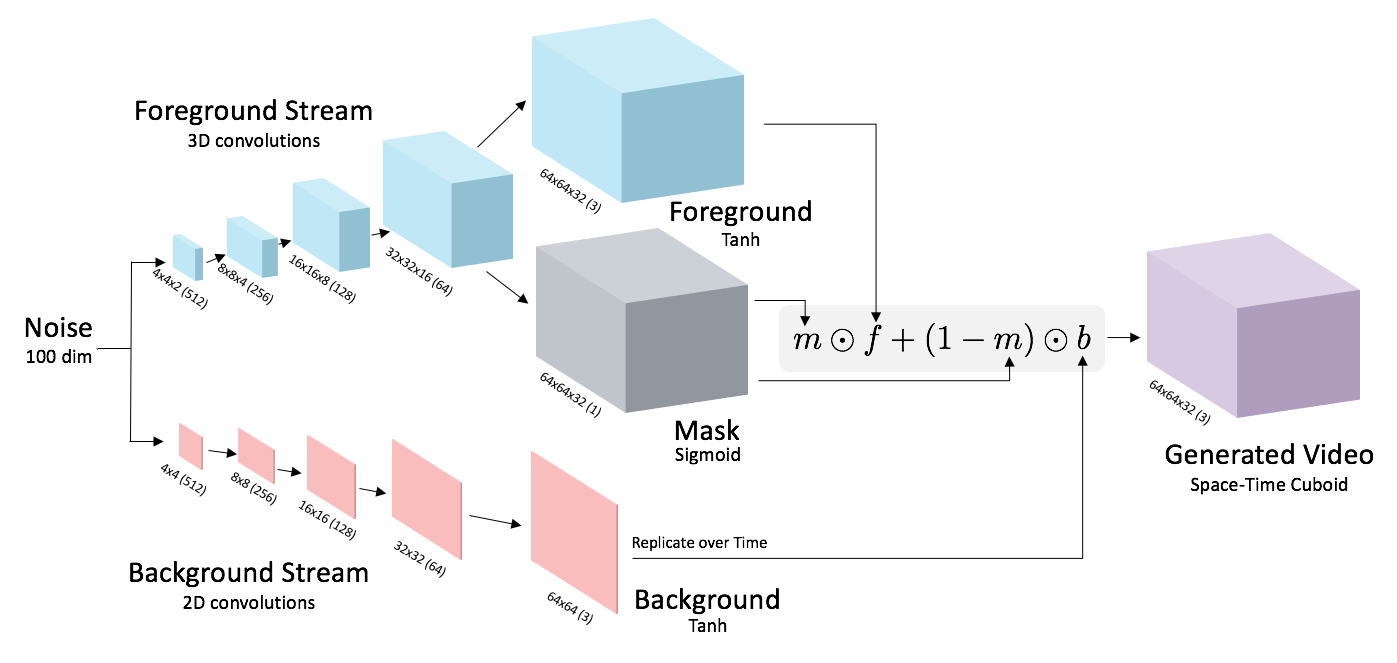
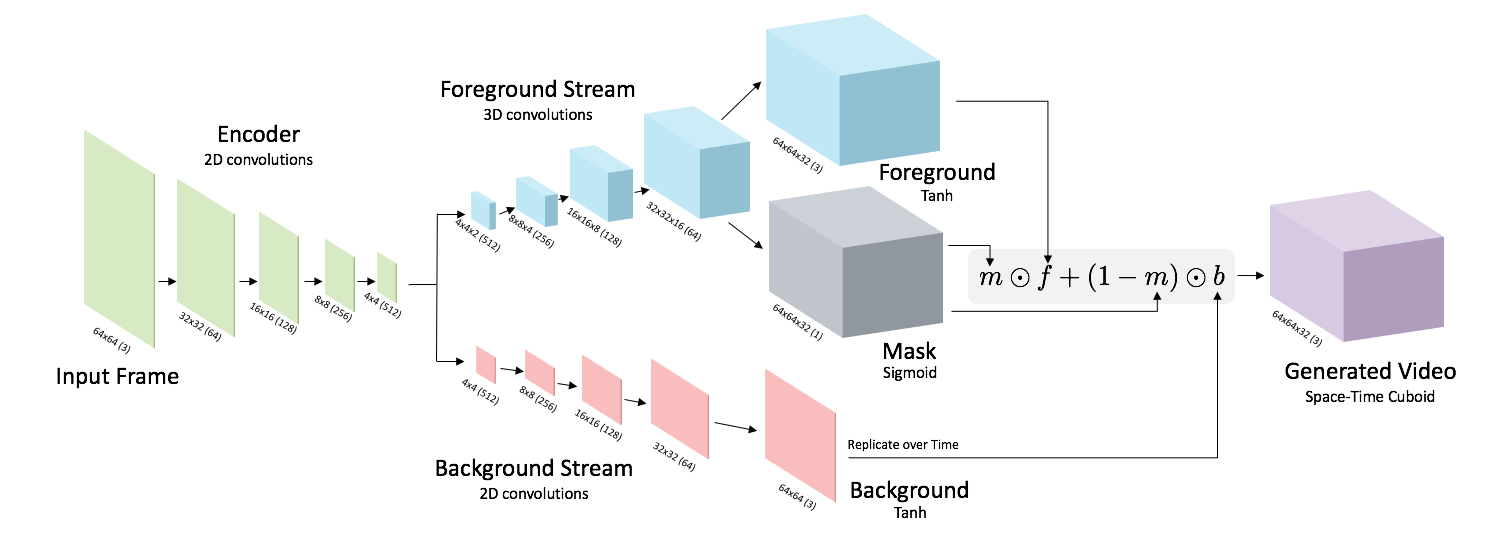
For the generator, we use a deep convolutional network that inputs
low-dimensional random noise and outputs a video. To model video, we use spatiotemporal up-convolutions (2D for space, 1D for time).
The generator also models the background separately from the foreground. The
network produces a static background (which is replicated over time) and a moving foreground that is combined using
a mask. We illustrate this below:
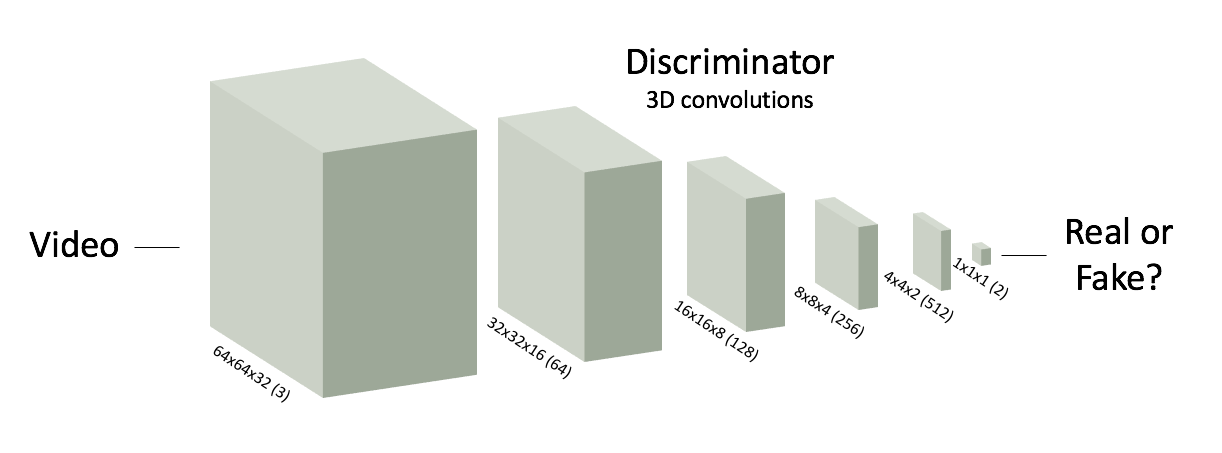
We simultaneously train a discriminator network to distinguish real videos from fake videos. We
use a deep spatiotemporal convolutional network for the discriminator, visualized here.
We downloaded two years of videos from Flickr, which we stabilize,
automatically filter by scene category, and use for training.
To predict the future, one can attach an encoder to the generator, visualized here.
Notes on Failures & Limitations
Adversarial learning is tricky to get right, and our model has several limitations we wish to point out.
- The generations are usually distinguishable from real videos. They are
also fairly low resolution: 64x64 for 32 frames.
- Evaluation of generative models is hard. We used a psychophysical 2AFC
test on Mechanical Turk asking workers "Which video is more realistic?" We
think this evaluation is okay, but it is important for the community to settle
on robust automatic evaluation metrics.
- For better generations, we automatically filtered videos by
scene category and trained a separate model per category. We used the PlacesCNN on the first few frames
to get scene categories.
- The future extrapolations do not always match the first frame very well, which may happen
because the bottleneck is too strong.
Related Works
This project builds upon many great ideas, which we encourage you to check out. They have very cool results!
Adversarial Learning
Generative Models of Video
Please send us any references we may have accidentally missed.

Code
The code is available on Github implemented in Torch7 and open source. You can also download pretrained models (1 GB zip file).
Data
We are making the stabilized video frames available for others to use. You may download it all or in parts. Each tarball contains JPEG files which in turn contain 32 frames vertically concatenated, corresponding to roughly a second of video. The videos have been stabilized by SIFT+RANSAC.
The total dataset is 9 TB, which consists of 35 million clips. This is over one year of video.
By Scene:
All Videos:
Or you can download pre-processed and stabilized frames directly:
File Listings:
Videos from "Videos1" are part of the Yahoo Flickr Creative Commons Dataset. Videos from "Videos2" are downloaded by querying Flickr for common tags and English words. There should be no overlap.
If you use this data in your research project, please cite the Yahoo dataset and our paper.
Acknowledgements
We thank Yusuf Aytar for dataset discussions. We thank MIT TIG, especially Garrett Wollman, for troubleshooting issues on storing the 26 terabytes of video. We are grateful for the Torch7 community for answering many questions. NVidia donated GPUs used for this research. This work was partially supported by NSF grant #1524817 to AT, START program at UMBC to HP, and the Google PhD fellowship to CV.













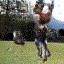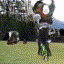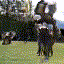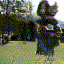
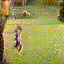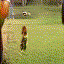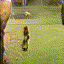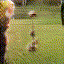































































{kind=link}
{kind=link}