

|
|
|
|
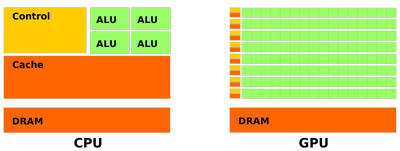
This course is an introduction to GPU computing - the practice (and art) of programming the massively parallel processors that are now ubiquitous in workstations and laptops - for more general tasks beyond the rendering context for which they were originally developed. In the process we will learn the details of GPU architecture and programming models, a significant number of parallel algorithms, techniques, and patterns, and how to maximize performance in the heterogeneous computing environment. We will do this through examples and assignments in various frameworks/APIs including CUDA C/C++, OpenCL, MPI, and Thrust, among others. This is a practical course - we will be compiling from the very first class - and encourage you to bring cross-disciplinary problems as potential projects. |
| Michael Reed
|
[ m-reed@cs.columbia.edu
| Home Page ] |
| phone:
|
917-811-1527
|
| office hours: |
after class Thursday, or by
appointment |
| mail: |
Department of Computer Science Columbia University 500 W. 120th Street, M.C. 0401 New York, New York 10027 |
| C and/or C++ as well as intro classes in algorithms and systems. Although not required, having taken domain-specific courses (Computer Graphics, Animation, Computer Vision, etc.) will allow you to easily consider applications of the material presented in this course. Students without these qualifications, who still wish to participate, should speak to the instructor. |
Programming Massively Parallel Processors, 2nd edition by Kirk and Hwu
note: this book is freely available through CLIO
Additional
material will be provided by the instructor.
| Course notes, lectures, assignments and other material will be put on the class wiki. If you are registered for this course, you should request a membership in that Wiki, or email me directly, as a significant amount of discussion will take place there. We will also be using CourseWorks for homework submission and grade distribution. |
There will be five 'regular' programming assignments and one final project; most can be written in C or C++ within the framework provided. Late assignments lose 10% each day they are late. They can be a maximum of 5 days late, after which they receive no credit. On Collaboration: Discussion of algorithms is encouraged, as well as the sharing of drawings and other representations of problems and the like. What is not permitted is the sharing or acquisition of code in any form. Any material from an outside source must be explicitly acknowledged |
Class# / Date |
Title & Selected Topics |
| 1 | introduction, administrivia, course & assignment overview, why GPUs?
“hello_world.cu” - development environment, getting started |
| 2 | GPU hardware, programming in CUDA I: basics, debugging, timing |
| 3 | programming in CUDA II : synchronization, parallel patterns I: map/reduce |
| 4 | programming in CUDA III : memory & efficiency,
performance considerations |
| 5 | parallel patterns II: scan & its applications, in-class coding demo/lab |
| 6 | parallel sorting & selection,
CPU/GPU coupled computation |
| 7 | parallel patterns III: convolution in-class coding demo/lab |
| 8 | quiz I, application example: n-body simulation |
| 9 | parallel graph search, floating point: accuracy and performance |
| 10 | guest speaker - TBA, programming in OpenCL I |
| 11 | programming in OpenCL II, arch/design of THRUST |
| 12 | introduction to MPI, in-class coding demo/ lab |
| 13 | quiz II, application example: TBA |
| 14 | final project showcase! |