to achieve optimized insertion.
- Rebuild the internal Structure of nonleafnodes.
- Implementing efficient way of insertion
- Change structure of nonleafnodes and as a result the way gctree inserts objects.
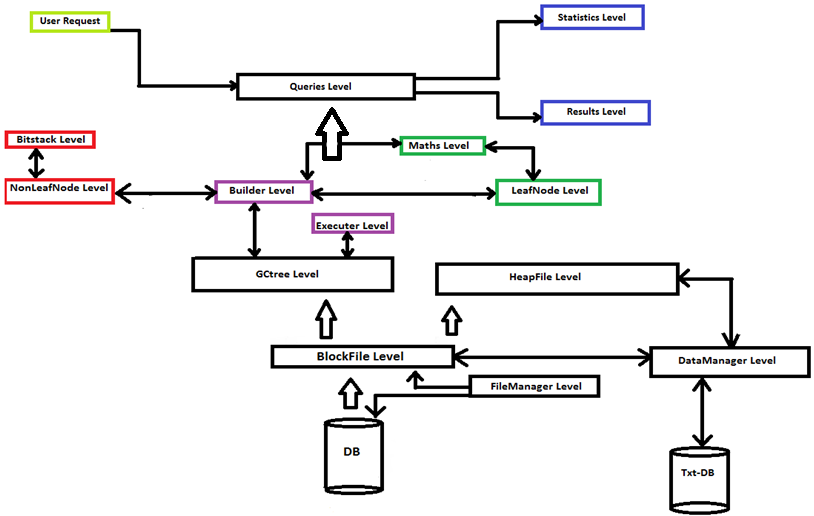
The difference between the older versions and this one is based on the way entries are getting inserted in nonleafnodes.
Lets visualise the way entries are getting inserted till now.
--------- ----------- --------- ---------
| Entry N | Entry N-1 |.....| Entry 2 | Entry 1 |
--------- ----------- --------- ---------
And now we insert entryK:
--------- ----------- --------- ---------
| Entry K | Entry N |.....| Entry 2 | Entry 1 |
--------- ----------- --------- ---------
In previous versions the entries were inserted at the start of the nonleafnode which caused continuous shifts of the rest entries. Lets say now that we have to insert a new entry entryK
In this version lets visualise the nonleafnode before insertion of entryK
----------- ----------- ----------- --------- ---------
|...EMPTY...| Entry N | Entry N-1 |.....| Entry 2 | Entry 1 |
----------- ----------- ----------- --------- ---------
And now we insert entryK:
----------- ----------- ----------- --------- ---------
|...EMPTY...| Entry K | Entry N |.....| Entry 2 | Entry 1 |
----------- ----------- ----------- --------- ---------
In previous versions the insertion of entry K would cause the shift of all the entries in nonleafnode so that it was possible to insert entry in correct(first) position. This change in the internal structure caused a happy effect.In case that there is no place for inserting a new entry,we have to call SplitNonLeaf. If the previous entry pointed outlier node then we have to insert the entry in a nonleafnode and point the overflow page.This happens by making the old nonleafnode an overflow page and creating a new nonleafnode where we insert the Eo and the Ec and make the newly allocated nonleafnode point to the old nonleafnode. Using this strategy lets us have insertions only to real parent and not to overflow pages.In previous versions we had to read all overflow pages to see if there is space to insert the new entry but now we keep in memory the real parent (nonleafnode) and perhaps the overflow nonleafnode and check the situations we face during insertions more efficiently.
- Efficient way of partioning entire domain
- Changing Initial Insert making it have two modes of building the root (The one i already have implement and another one to make insertion easier)
- Optimizing partition of a leafnode.When the partition cant find a cluster this means that in next insertion we will have to re-partition,by recalculating the new cells and compute in which cell each object lies.With the new strategy we are about to keep some history(lru),of the cells so that the next time we insert an object which would cause repartition will find the cells already calculated in memory. I will do this due to the observation that continuous repartition causes a big overhead during insertion..
to make compare easier.