The problem of text categorization is to classify documents into a fixed number of classes. How to classify documents, that is, how to assign documents to a class, and how precise it is, still remains as one of the current research topics. There are two kinds of algorithms have been frequently used for this purpose. First one is based on the algorithm about the relevace feedback method which is introduced by Rocchio[Rocchio, 1971], the other one is based on Naive Bayes algorithm.
Naive Bayes algorithm can be used very successfully in text categorization task. It basically uses probabilistic models to estimate the likelihood that a given document is in a class. This probability estimate is actually used for decision making purpose. This algorithm is based on the bag-of-words representation developed in information retrieval. This is an attribute-value representation where those documents are represented by the words occuring in it without paying attention to their ordering.
The naive Bayes classifier, which is using highly practical Bayesian learning method, is said to be quite successful when applied to learning tasks to classify natural language text documants, and in some domains its performance has been shown to be compatible to that of neural network and decision tree learning. In our final project, we did some interesting experiments using alternative mesaures of evaluation, for example, how precise is it for each newsgroup? Which newgroups get highest/lowest precision? etc., just in order to figure out in what level, how precise it is when classifying text documents. In the second part of our project, we provided a Webpage Classifier based on Andrew McCallum's rainbow system. The performance is also measured and analized.
First, we will index the documents, this is the training phase:
$ ./rainbow --index 20_newsgroups/*
With the documents indexed, we can now do some testing runs. For our run, we use 67% of the indexdocuments as training documents, and 33% of the indexed documents for testing:
$ ./rainbow --test-percentage=33 --test=1 > rainbow_output
The --test-percentage=33 specifies that 33% of the indexed documents should be set aside for testing. These documents are randomly chosen from the poll of indexed documents and information from these documents is not part of the model used to classify documents (on this run). The --test=1 option indicates that you wish to perform one testing run.
Once the above run is complete, a file named rainbow_output contains all the result information. It includes the classification for each individual document and also the confidence rating for each classification. To get summary results for the testing runs, we run this file through the rainbow-stats program:
$ rainbow-stats < rainbow_output >rainbow_stat
This gives us the result which tells us the overall accuracy for each run, along with the details for the testing documents from each of the category from which testing documents were used. Note that the resulting accuracy might be different as the training/test document split is made at random.
Rainbow offers plenty of options which can be used for our experiment. Without specifying any other options, Rainbow will use a stoplist to remove uninformative words (such as 'a', 'the', etc.). To have Rainbow not use this stoplist, we use the -s or --no-stoplist option.
In order to increase the accuracy of the learning algorithm, we use stemming option, a method which represents each word by its root, removing suffixes which might differentiate two words which have the same meaning. Rainbow has code to perform stemming during the lexing and indexing of the documents. This can be turned on by using the -S or --use-stemming option with the execution of Rainbow.
a) Hold-out Set
We can tell Rainbow to test the classification performance on a hold-out
set. For example, a portion of the data that will not be used for traing
the classifier. This should give much more trustworthy results than tesing
on the training data itself. Test the performance on a hold-out set consisting
of different percentage of the data, and use the remaining part of the
data for training, we can get different percentage of Average_percentage_accuracy.
The following experiment are done on mini_newsgroups data set, with
one test run.
(./rainbow -method=naivebayes --no-stoplist --skip-header --prune-vocab-by-occur-count=1
)
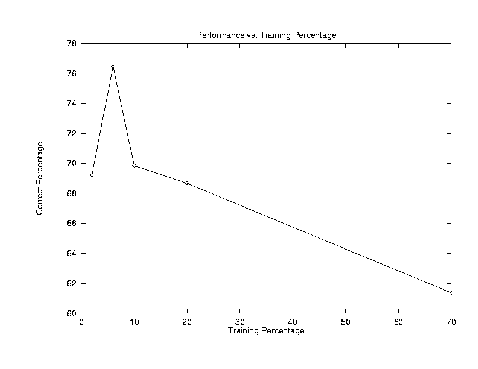
Training set : 2% Correct: 27 out of 39 (69.23 percent accuracy)
Training set : 6% Correct: 91 out of 119 (76.47 percent accuracy)
Training set : 10% Correct: 139 out of 199 (69.85 percent accuracy)
Training set : 20% Correct: 274 out of 399 (68.67 percent accuracy)
Training set : 70% Correct: 858 out of 1398 (61.37 percent accuracy)
For some reason, we got relatively lower performance. We suppose maybe this is because our training set and test set are relatively small. Our data set for this particular experiment is mini_newsgroups data set which is much smaller than the other one, 20_newgroups, which contains more than twenty thousand news articles.
b) K-fold Cross-Validation:
With k-fold cross-validation technique, we can use a different random
partitioning of the data for k different times. The constant k can be specified
by --test=k. We use k=10 for each data point, perform 10 test/ train splits
of the indexed documents, and output the classifications of all test documents
each time.
The following experiment are done on the newsgroups data set, with ten test runs, without skipping header part of each documant.
Trial 0 -- Correct: 5810 out of 6588 (88.19 percent accuracy)
Trial 1 -- Correct: 5770 out of 6588 (87.58 percent accuracy)
Trial 2 -- Correct: 5787 out of 6588 (87.84 percent accuracy)
Trial 3 -- Correct: 5809 out of 6588 (88.18 percent accuracy)
Trial 4 -- Correct: 5806 out of 6588 (88.13 percent accuracy)
Trial 5 -- Correct: 5797 out of 6588 (87.99 percent accuracy)
Trial 6 -- Correct: 5782 out of 6588 (87.77 percent accuracy)
Trial 7 -- Correct: 5815 out of 6588 (88.27 percent accuracy)
Trial 8 -- Correct: 5788 out of 6588 (87.86 percent accuracy)
Trial 9 -- Correct: 5791 out of 6588 (87.90 percent accuracy)
Average_percentage_accuracy_and_stderr 87.97 0.07
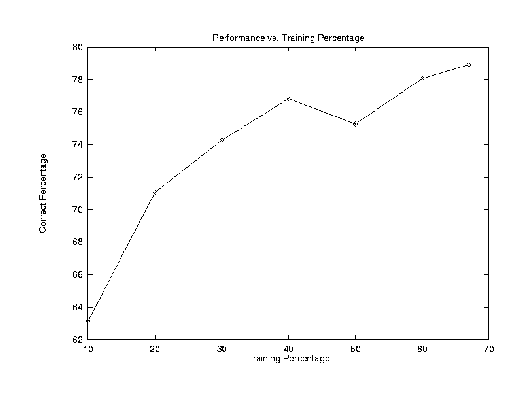
Now, skipping header information in documants, for example, skip subject,
title, etc. lines in the newsgroup articles. test-percentage=10 -- Correct:
1683 out of 1986 (84.74 percent accuracy)
test-percentage=20 -- Correct: 3375 out of 3980 (84.80 percent accuracy)
test-percentage=33 -- Correct: 5526 out of 6578 (84.01 percent accuracy)
test-percentage=40 -- Correct: 6711 out of 7967 (84.23 percent accuracy)
test-percentage=60 -- Correct: 9685 out of 11951 (81.04 percent accuracy)
test-percentage=80 -- Correct: 2926 out of 4230 (69.17 percent accuracy)
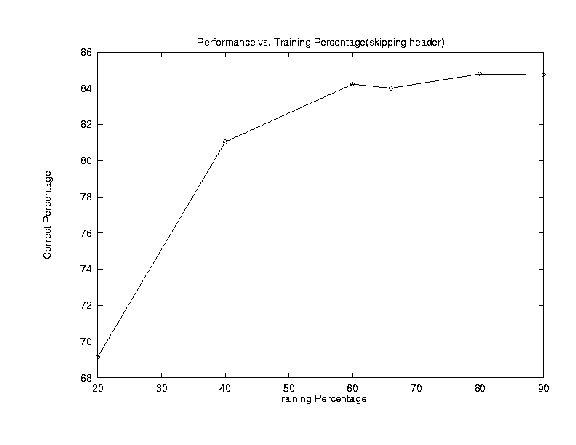
Analysis: As we see can from above graph, when training percentage increases, we get better performance. For example, when training set only takes 20% of the whole data set, the accuracy is 69.17%; but when training set takes 40% of the total data set, then the accuracy we got jumps to 81.04%. This indicates that training over the insufficient data set will get lower performance, especially when it evaluated over much larger unseen new data set.
Evaluating the performance only over the training set may not fairly judge the real performance over the whole domain, the hypothesis obtained over a bunch of training set may overlearned the training examples, and may not perform well when measured over unseen test cases. Thus evaluating over the training set itself is not enough, we need new data which are unseen during training. Cross-Validation does this job.
As professor mentioned, we don't think improving accuracy should necessarily
be the goal for this assignment, however, we consider alternative mesaures
of evaluation, that is, how precise is it for each newsgroup? Which
newsgroups get highest/lowest precision, and why? Though this WHY question
is hard to answer, we do did some experiments and tried to figure out the
reason.
Through some analysis on the classification accuracy of each newsgroup, we found that talk.religion.misc newsgroup has the lowest precision(aroud 57% accuracy), and soc.religion.christian newsgroup got the highest precision among 20 newsgroups's more than 20000 articles, 99% accuracy. We think this is probably because talk.religion.misc newsgroup does not typically focus on some relatively specific topics, they may talk about many more other field of interest. On the other hand, soc.religion.christian newsgroup mainly focus on the topic regarding the religion derived from
Jesus Christ, based on the Bible as sacred scripture, something like that.
The accuracy for higher level distinction, for instance, just comp vs rec, is very high.
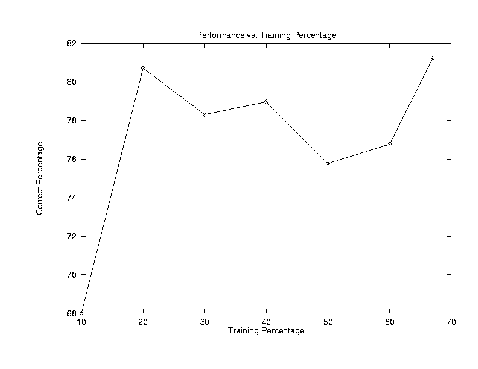
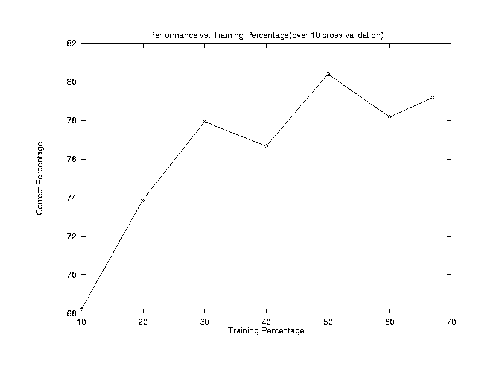
Correct: 104 out of 128 (81.25 percent accuracy) - Confusion details, row is actual, column is predicted classname 0 1 2 3 :total :correct percentage 0 student 22 6 6 1 : 35 62.86% 1 dept 2 27 1 1 : 31 87.10% 2 extra 6 . 23 . : 29 79.31% 3 faculty . . 1 32 : 33 96.97% Average_percentage_accuracy_and_stderr 81.25 0.00Performance Vs. Training Percentage:
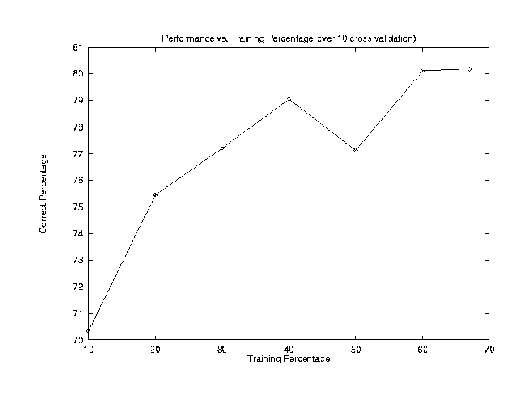
Correct: 99 out of 128 (77.34 percent accuracy) - Confusion details, row is actual, column is predicted classname 0 1 2 3 :total :correct percentage 0 student 17 6 1 10 : 34 50.00% 1 dept 1 29 1 1 : 32 90.62% 2 faculty . . 32 . : 32 100.00% 3 extra 6 3 . 21 : 30 70.00% Average_percentage_accuracy_and_stderr 77.34 0.00Performance Vs. Training Percentage:
0.32514 research 0.28718 professor 0.18282 ph 0.18221 department 0.14243 publications 0.13559 engineering 0.13130 physics 0.12831 interests 0.12162 faculty 0.12149 systems 0.11985 mudd 0.11280 courses 0.11198 fax 0.10975 selected 0.10606 programs 0.10315 phys 0.10299 feedback 0.08793 table 0.08780 cellpadding 0.08084 telephone