
this player wins 26 games out of 50 games when it played against random player.
Othello is a kind of computer board game. You play on a square 8x8 gridded board, with one player white, the other is black. The key rule of this game is to surround your opponent's pieces, and then all of his pieces that are between two of yours become yours, and the one who has more pieces in the end of the game wins the game.
Genetic programming(GP) is a variant of genetic algorithms that evolves computer programs represented as tree structures. It is a kind of evolutionary computation in which the individuals in the evolving population are computer programs. The fitness of a given individual is evaluated by executing the program on the training data. In this Othello project, genetic programs are basically formulas that use statistics of the game board, such as the number of white pieces, the number of black pieces, etc., to calculate the next board position which calculates to the best score.
The Modified hypothesis
Some positions on the board are special, for example, the position that one
piece away from the corners, we can simply call it white_second_corners and
black_second_near_corners, I have incorporated these positions as new terminals
in this modified hypothesis. Thus the modified hypothesis includes the following
functions and terminals:

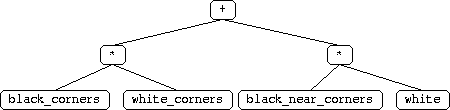
The best Trained player based on the above new hypothesis and the training configuration below is shown in figure 3.
PopulationSize = 50
NumberOfGenerations = 11
CrossoverProbability = 90
TerminationFitness = 50
GoodRuns = 5
Figure 3:
this player wins 26 games out of 50 games when it played against random player.
The best Trained Player based on new hypothesis and the training configuration
below is shown in figure 4.
PopulationSize = 20
NumberOfGenerations = 7
CrossoverProbability = 90
TerminationFitness = 50
GoodRuns = 5
Figure 4:

this player wins 25 games out of 50 games when it played against random player.
I made more experiments which training the players with different population size, different number of generations, and different crossover probabilities. The result is shown below as a table. The last item, Wins(/random), means the number of games wined by the best trained player when it played against random player.
| PopulationSize | NumberOfGenerations | CrossoverProbability | Wins(/random) |
| 20 | 7 | 90 | 25 |
| 50 | 7 | 90 | 26 |
| 100 | 7 | 90 | 27 |
| 150 | 7 | 90 | 28 |
| 200 | 7 | 90 | 28 |
| 200 | 31 | 90 | 31 |
| 200 | 51 | 90 | 36 |
| 200 | 71 | 90 | 38 |
| 200 | 51 | 80 | 34 |
| 200 | 51 | 70 | 28 |
| 200 | 51 | 60 | 24 |