The most distinctive feature of Naive Bayes classifier is that it has no explicit search through the space of possible hypotheses. Instead, the hypothesis is formed by counting the frequency of various data combinations within the training examples. Because of this distinctive feature, Naive Bayes classifier is an attractive candidate for screening resumes.
In recruiting firms and major companies, it is common practice to match incoming resumes with keywords for job openings available. Resumes with high frequencies of certain keywords are kept and pass through to different departments for evaluation, while resumes with low frequencies of matching keywords are discarded.
In our final project, we decided to investigate the application of Naive Bayes classifier to matching resume to job postings. Instead of developing our own Naive Bayes, we made use of the Naive Bayes classifier, Rainbow/Libbow software package, developed by Prof. Tom Mitchell at Carnegie Mellon University.
As a stand-alone system, it can index text documents and apply Naive Bayes learning algorithm to classify the indexed text documents.
In our project, we used the Rainbow/Libbow Package as stand-alone classifier. We did not add in addition code.
Instead of using newsgroup, we used jobs postings. We collected 10 different kinds of job postings, each containing 100 text documents, from the America Job Bank. The job postings in our dataset are as followings:
The text documents from the job postings were used as training examples. As testing examples, we collected 87 resumes:
| Job Postings | Number of Corresponding Resumes |
|---|---|
| Accounting | 8 |
| Computer Programming | 8 |
| Database Administration | 10 |
| Economics | 10 |
| Health Care | 10 |
| Human Resources | 8 |
| Sales | 10 |
| Software Engineering | 8 |
| System Analysis | 8 |
| User Support Analysis | 7 |
In the data collection phase, we made use of Netscape Navigator and the web search engine Yahoo. Together, they provided us with a list of job banks that have job postings readily available to the public. Out of convenience, we picked America Job Bank to collect our job postings dataset. (The America Job Bank was on the top of the list returned by the search.)
Unfortunately, most job banks do not have publicly available resume postings. In order to get at least a decent size testing dataset, we used the web search engine Alta Vista. We ran a query on Resume. It returned a decent size search result, but most of the resumes returned are in computer related field.
Fortunately, one of the search listings point us to Job Digest which has publicly available job seekers resume. However, some of the resumes posted in Job Digest were not entirely suitable for our experiment. Again, the majority of the suitable resume posted at Job Digest were computer related. In order to prevent unbalance in our dataset, we limit the number of resumes collected in each field to 7 to 10 resumes. After all the data were in place, we started the second phase, the training phase.
During the training phase, we simply used the command:
$ rainbow --data-dir=our_directory
--index our_job_posting_directories
as described in the
Gentle Introduction to Rainbow of the
Rainbow/Libbow package to index all of our job posting text documents.
Seeing that most of the job postings used abbreviations, we were
curious to see what effect stemming (a method which represents each word by
its root, removing suffixes which might differentiate two words which
have the same meaning) might have on our experiment result. We
decided to set up another experiment set using the command:
$ rainbow --use-stemming
--data-dir=our_directory
--index our_job_posting_directories
to have the software perform stemming during the lexing and indexing
of our job postings. After our Naive Bayes classifier was trained,
we started our testing.
In the testing phase, we ran the query:
$ rainbow --query=one_of_our_resumes
on all of the 87 resumes we collected, one at a time. We ran the
command on both the "stemmed" classifiers and the "no-stem" classifiers.
The query command used the job postings as the training set, and the resume as the testing set. In other words, the classifiers were matching the resume to its most likely category based on job postings.
In order to have some basis to evaluate the performance of the
classifiers on resume and job postings matching, we ran the following
command:
$ rainbow --data-dir=our_directory
--test-percentage=33 --test=10 > output_file
on all 10 categories of job postings we collected. We ran the
command on both the "stemmed" classifiers and the "no-stemmed"
classifiers.
The command randomly picked 67% of the indexed job postings as training and used the remaining 33% as testing. And the command repeated this training and testing pattern for a total of 10 times.
This command essentially give us a metrics to estimate how precise the job postings are in each category. We theorized that the more precise the job postings were in a category, the higher the likelihood of a correct match by our classifiers.
rainbow --query=one_of_our_resumes
are as follows:
| Category Number | Category Name | Category Numbers | Total Number of Resumes | Accuracy within group | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||||
| 0 | Accounting | 3 | 1 | 4 | - | - | - | - | - | - | - | 8 | 37.5% |
| 1 | Human Resources | - | 7 | 1 | - | - | - | - | - | - | - | 8 | 87.5% |
| 2 | Economics | 1 | 1 | 6 | - | - | - | - | 1 | - | 1 | 10 | 60.0% |
| 3 | Health Care | - | - | 2 | 7 | - | - | - | 1 | - | - | 10 | 70.0% |
| 4 | User Support Analysis | - | - | 1 | - | 2 | - | 2 | 1 | 1 | - | 7 | 28.57% |
| 5 | System Analysis | - | - | - | - | 5 | 0 | 1 | 1 | - | 1 | 8 | 0.0% |
| 6 | Software Engineering | - | - | 2 | - | - | - | 3 | - | 2 | 1 | 8 | 37.50% |
| 7 | Sales | 1 | - | 2 | - | - | - | 1 | 4 | - | 2 | 10 | 40.0% |
| 8 | Database Administration | - | - | 2 | - | 1 | - | 4 | - | 3 | - | 10 | 40.0% |
| 9 | Computer Programming | - | - | - | - | - | 2 | - | - | - | 6 | 8 | 75.00% |
| TOTAL | - | - | - | - | - | - | - | - | - | - | - | 87 | Total: 47.61% |
The table indicates how the "stemmed" classifies match each resume to each category of job postings. For instance, for the category of job posting in Accounting, it has the category number of 0, and the classifiers has identified three resumes in this category to Accounting, 1 to Human Resources, and 4 to Economics.
The summarized results of the command
rainbow --data-dir=our_directory --test-percentage=33 --test=10 >
output_file
is as follows:
| Category Number | Category Name | Accuracy(%) at each Run | Average Accuracy(%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||
| 0 | Accounting | 91.18% | 97.06% | 91.18% | 88.24% | 84.85% | 97.06% | 85.29% | 85.29% | 73.53% | 88.24% | 88.1% |
| 1 | Human Resources | 85.29% | 84.38% | 71.43% | 82.86% | 94.29% | 91.43% | 88.57% | 88.57% | 85.71% | 87.10% | 85.90% |
| 2 | Economics | 79.41% | 90.62% | 79.31% | 75.76% | 82.35% | 85.29% | 79.41% | 85.29% | 93.10% | 90.91% | 84.10% |
| 3 | Health Care | 91.18% | 83.33% | 88.24% | 83.87% | 97.06% | 94.12% | 88.24% | 94.12% | 86.21% | 88.24% | 89.40% |
| 4 | User Support Analysis | 76.47% | 64.71% | 64.71% | 85.29% | 64.71% | 56.00% | 64.71% | 90.32% | 73.53% | 78.79% | 86.90% |
| 5 | System Analysis | 55.56% | 55.88% | 52.94% | 47.06% | 48.48% | 70.59% | 73.53% | 72.00% | 55.88% | 71.43% | 60.33% |
| 6 | Software Engineering | 70.59% | 70.97% | 76.47% | 66.67% | 73.33% | 64.71% | 62.50% | 67.65% | 82.35% | 70.59% | 70.50% |
| 7 | Sales | 81.82% | 80.00% | 82.86% | 74.29% | 68.57% | 82.86% | 90.32% | 77.14% | 81.82% | 65.71% | 78.50% |
| 8 | Database Administration | 72.73% | 67.65% | 93.10% | 96.67% | 81.25% | 82.35% | 78.57% | 70.59% | 94.12% | 79.41% | 81.60% |
| 9 | Computer Programming | 69.70% | 52.94% | 65.62% | 70.97% | 40.00% | 67.74% | 76.47% | 67.65% | 58.82% | 64.71% | 63.42% |
The table indicates the result of each test trial. For each trial, 66% of the job posting text documents were used for training, and 33% of them were used for testing.
In the table, it shows that for the job posting category of
Accounting, the "stemmed" classifier got 91.18% of the
test cases correct.
rainbow --query=one_of_our_resumes
are as follows:
| Category Number | Category Name | Category Numbers | Total Number of Resumes | Accuracy within the group | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||||
| 0 | Accounting | 2 | 1 | 5 | - | - | - | - | - | - | - | 8 | 25.00% |
| 1 | Human Resources | - | 5 | 2 | 1 | - | - | - | - | - | - | 8 | 62.5% |
| 2 | Economics | 2 | 1 | 7 | - | - | - | - | - | - | - | 10 | 70.0% |
| 3 | Health Care | - | - | 2 | 8 | - | - | - | - | - | - | 10 | 80.0% |
| 4 | User Support Analysis | - | - | - | 1 | 4 | 1 | - | 1 | - | - | 7 | 57.14% |
| 5 | System Analysis | - | - | 1 | - | 5 | 0 | - | - | 2 | - | 8 | 0.0% |
| 6 | Software Engineering | - | - | - | - | - | 1 | 2 | - | 5 | - | 8 | 25.00% |
| 7 | Sales | - | 1 | 5 | - | - | - | - | 4 | - | - | 10 | 40.00% |
| 8 | Database Administration | - | - | - | - | 1 | 1 | 3 | - | 5 | - | 10 | 50.00% |
| 9 | Computer Programming | - | - | - | - | - | - | - | - | 1 | 8 | 9 | 88.88% |
| TOTAL | - | - | - | - | - | - | - | - | - | - | - | 87 | Total: 51.72% |
The table indicates how the "stemmed" classifies match each resume to each category of job postings. For instance, for the category of job posting in Accounting, it has the category number of 0, and the classifiers has identified 2 resumes in this category to Accounting, 1 to Human Resources, and 5 to Economics.
The summarized results of the command
rainbow --data-dir=our_directory
--test-percentage=33 --test=10 > output_file
is as follows:
| Category Number | Category Name | Accuracy(%) at each Run | Average Accuracy(%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||
| 0 | Accounting | 88.24% | 91.18% | 92.31% | 85.29% | 94.12% | 96.97% | 94.12% | 96.97% | 91.18% | 100.00% | 93.038% |
| 1 | Human Resources | 70.59% | 80.00% | 91.18% | 82.35% | 91.18% | 79.41% | 88.24% | 88.24% | 82.35% | 76.47% | 83.001% |
| 2 | Economics | 85.71% | 79.41% | 79.41% | 74.19% | 85.29% | 91.18% | 77.78% | 82.35% | 75.86% | 79.41% | 81.05% |
| 3 | Health Care | 87.88% | 79.41% | 82.35% | 87.50% | 94.12% | 96.88% | 91.18% | 88.24% | 91.18% | 88.24% | 88.69% |
| 4 | User Support Analysis | 77.42% | 82.35% | 73.53% | 83.87% | 79.41% | 85.29% | 76.47% | 66.67% | 68.75% | 73.53% | 76.70% |
| 5 | System Analysis | 70.59% | 50.00% | 61.76% | 67.65% | 48.39% | 61.76% | 65.62% | 70.59% | 54.84% | 79.41% | 63.06% |
| 6 | Software Engineering | 85.29% | 67.65% | 85.29% | 79.41% | 70.59% | 67.65% | 72.73% | 71.43% | 70.59% | 68.75% | 73.90% |
| 7 | Sales | 74.29% | 68.57% | 82.86% | 76.47% | 82.76% | 75.00% | 74.29% | 84.38% | 74.29% | 93.10% | 84.80% |
| 8 | Database Administration | 73.53% | 83.33% | 77.42% | 63.64% | 78.12% | 72.73% | 70.59% | 85.29% | 87.88% | 67.65% | 84.50% |
| 9 | Computer Programming | 51.52% | 38.71% | 50.00% | 57.58% | 47.06% | 61.76% | 54.55% | 44.12% | 52.94% | 52.94% | 51.10% |
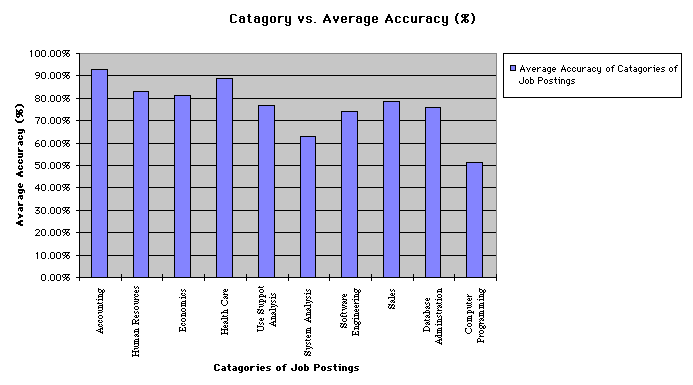
The graph shows the relationship between category vs. average accuracy of the "no-stemmed" classifier when we were trying to see how ambiguous the job postings are.
The job postings we picked can be divided into two major sub-categories:
Looking at the graph, we notice that all the job postings in computer related categories have the lowest 5 average accuracies.
At closer examination of the actual job postings in these 5 categories (User Support Analysis, System Analysis, Software Engineering, Database Administration, Computer Programming), we notice that it was hard to distinguish among the different sub-categories within this field, for humans and machines alike.
The keywords employers used in these categories tend to be similar. For instance, keywords such as C, C++, Windows, WindowsNT, COBOL, software, client/server, develop, application and many others are common among job postings in all 5 sub-categories within the computer related field.
On the other hand, keywords used by job postings in non-computer related fields tend to be more unique within its own category. For instance, in Economics, the common keywords are Marketing, Finance, management, etc., while in Health Care, the common keywords are medical, technician, opthalmology, and others.
Without prior knowledge, for both humans and machines, it was much easier to tell job postings from Health Care and Economics apart than it was to tell job postings from System Analysis and Software Engineering apart.
As noted earlier, we created two different classifiers: "stemmed", and "no-stemmed" classifiers. The "stemmed" case didn't behave better than the "non-stemmed" case.
The major reason, we believe, is that most of the job postings use abbreviations. In such cases, stemming does not help.
Moreover, there appears to have quite a few misspelling in these job postings, computer-related and non-computer-related fields alike. This makes correct classification difficult.
Because of the ambiguity within the job postings themselves, it was no surprise to us that our resume matching results were not as good as we had expected.
Most resumes we collected were fairly precise. On the other hand, the job postings tend to be vague.
The main reason is that Naive Bayes classifier does not do explicit search. It relies on the frequency of the keywords. If keywords are not properly represented, Naive Bayes classifier cannot properly produce the correct result.