After a while, people acquired some new algorithms from the research on artificial intelligence, and applied them, neural network and genetic algorithm, for these domains. One of the important characteristics of these algorithms is potential to seek the complex part of the domain that is hard to find by the people's thought/imagination. Thus these were seemed as the strong tools for them.
Actually, neural network is used in our company (stock company) to find the prediction method of the move on the stock price around 1990, but it was not successfully finished. Because the neural network can find only one fixed model proved by the training set, the training set and the setting of the parameters becomes extremely important. In addition, because the stock market's dynamics are very quick and the model for this system may change in the short term, the more recent data should be given much weight to on the consideration of the market. On the other side, the old data should be lower estimated by the network, without loosing much of the general characteristics of the model of the domain. Generally neural network only studies to diminish errors from all training data and estimates them equally.
Neural network is based the learning system of brain for the training, thus one of the approach for the problem is just adding the "forgetting" process to the training of the neural network as human's brain. This means that while the newer data is used for positive training of the network, the older data is used for the negative one. The negative training means the method that makes larger the error proved by the data, on the other hand the positive training makes the error small. The older data is assumed to be no longer helpful data so that make the effect small.
The following sections state the detail of the algorithm and the applied result of the algorithm for stock price prediction. At first, this paper mentions the detail for neural network with "forgetting" algorithm. In this section, the weak point of the general Neural Network and one of the approach to prove this is indicated. In the next sections, the result that this algorithm is applied to the prediction of rise/fall of the stock price follows. At last section, the conclusion and ideas for improvement are indicated.
On the other hand, there also exists actual system whose model is always changing. For example, the real face recognition requires an alternation of the model because the face changes year by year. These models are based on some general models proved by the training data, but they are biased by particular data. If the data is time sequential, the recent model is generally biased by the recent data and the effect of the old data becomes smaller and smaller.
The modeling of stock market also has such characteristics. It is because there are some trends on the market that cannot find only from the whole market data. For example, the sudden change of economy appears only on the recent data. In addition, some new participants and technologies change the rule on the stock market; thus the modeling of the pricing is continuously changing and biased by recent data.
To find these biased models by Neural Network, this paper suggests the "forgetting" algorithm of Neural Network. Neural Network imitates the human brain so that the nodes (neurons) learns from certain examples. On the other side, one of the characteristics in thinking way of human being is "remember and use the later examples more than old ones and even forget the older ones." This means "train the network with new data as possible, on the other hand trash old data which already decrease the effect on the model."
This is the algorithm, "Learn-Forget Algorithm," of the training with this idea. The data D[i] is sequential data and keeps closer relation to the closer data . To derive the neural network for Xth Data D[X] is just algorithm Alg.1.
- Make initial neural network using the training data D[0]-D[n_i] and general training method of neural network.
- From i = n_i + 1 to X-1
- Repeat (E times)
- Traing neural network for using D[i] (learning rate=r)
- Training neural network for using D[i-d] (to forget) (learning rate=-r*f)
- Repeat (E times)
d:The number of data to forget
f:Learning rate for forgetting
E: Number of training
In Alg.1, procedure 1 makes the general Neural Network. The reason of this procedure is the generation of the base model. This model is changed by "Learn-Forget" part of the algorithm. Procedure 2.1 means the learning of newer example. Procedure 2.2 is "forgetting" of older example. This procedure makes larger the error proved by older example. Then the effect from the older data is assumed to be smaller than the newer data. The parameter d means the number of nodes which keeps in the neural network. Then the i-d th node will be trashed in the i th procedure. f, E is as shown on the explanation. Using this training algorithm, the neural network can have the adaptation to closer data (i.e. newer data if it is time sequential). Thus the model is assumed to fit the current situation.
- Data
Stock market price data that is used for this experiment is during Jan 1994 to April 1999. These data are provided by the Tokyo Stock Exchange. The number of the days when the market opened during this term is 1323. All data are market closing prices. The input for the neural network is rising/falling rate of closing price in 5 sequential days, 14 names, and their average, maximum, and minimum for each day. These 14 names are in the same classification of the industry, electric, and the election of these names adopts from Nikkei 225 Stock Market index. (Appendix A.)
The output is classification of rise/fall of the price of 14 names in 6th day, therefore the number of input/output set is 1318. The number of hidden nodes are 40 thus the neural network is 85x40x14.(Fig.1) Note that the neural network uses 1/(1+e^y) for the sigmoid function, then the range of the output becomes 0 to 1 and the rise for the output is represented as 0.9 and the fall as 0.1.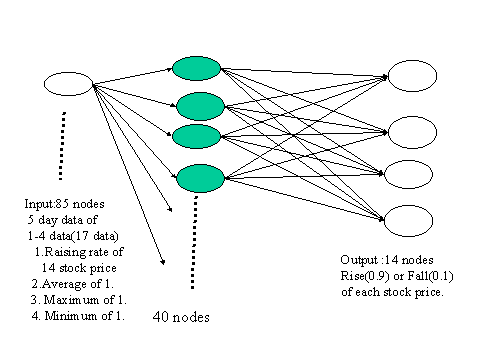
Fig.1 Neural Network of this experiment - Result
The result shows a little improvement from the result of original neural network; however, this improvement does not enough large to mention that the method is actually effective in practical. To estimate the accuracy in the classifying, these measures are used:
N=Average of the number of names correctly recognized. (MAX=14, MIN=0, 14 is better.)
A=Average of error in one output.(MAX=1, MIN=0, 0 is better.)Table. 1 indicates the result of original neural network. The network uses first 200 data of all data for as training data and the rest of the data (1118 data) as the test data. The learning rate r is 5 because from another experience which uses r<1, the convergence of the network seems very slow. From this result, the neural network fits to the training set, but this does not show the effective result for the test set.
Table 1. The result of general Neural NetworkN for training set A for training set N for test set A for test set 13.455 0.105 7.271 0.441 Table 2 shows the result using algorithm 1 with some parameters for the recognition of the test set. Note that as mentioned in the approach section and algorithm, the different neural network is prepared for each data, while the generation is sequentially available. In this case, forgetting rate F is fixed to 0.5. From these results, the improvement of Learn-Forget algorithm is less than 3.5%. Thus the improvement is observed, while it is extremely small. From these experiments, E=1 is better. Actually, from the result of another experiment of E=100 case, the neural network overfits to the one certain data then the most of the outputs from the neural network are almost 0 or 1. Then the result becomes rather wrong.
Table 2. The result of d=5, 30 case (f=0.5)E=> 1 2 3 4 5 f N A N A N A N A N A 5 7.495 0.437 7.379 0.436 7.350 0.441 7.297 0.443 7.308 0.444 30 7.525 0.436 7.446 0.442 7.423 0.446 7.446 0.442 7.308 0.444 Table 3 shows the result of f=5,10,30,50,and 100 case. In this case, E=1 and f=0.5 (fixed.) From the result of these experiments, around f=30 is better. But there are not big differences between these results in this experiment.
Table 3. The result of d=5,10,30,50,100 case (E=1, f=0.5)f 5 10 30 50 100 N 7.495 7.417 7.525 7.505 7.478 A 0.436 0.438 0.437 0.437 0.441 Table 4 shows the result of d=0, 0.5, 1, and 2 case. In this case, E=1 and d=30 (fixed.) d=0 means there are no forgetting in the algorithm, only adding backpropagation of new data. From these results, without forgetting previous data, there are a little improvement observed. With the forgetting algorithm, there is improvement on the correct number N of output while the error A becomes larger. Thus the forgetting algorithm is effective on N. From this experiment around f=1 is better. In addition, f>1, this means that "forgetting rather than learning," makes the neural network ineffective.
Table 4. The result of f=0, 0.5, 1, 2 case (E=1, d=30)f 0 0.5 1 2 N 7.353 7.525 7.528 7.262 A 0.431 0.436 0.448 0.477 Overall, from these experiments, the results do not show the big improvement from general Neural Network on the classifying problem on this domain. But on the other hand, these results show that this algorithm is still effective comparing with general Neural Network in the measures. In this experiment, with many variety of parameters the great improvement is not achieved. From the result of the expriment, the optimized parameter setting is E=1, d=30, and f=1 on measure N. (In practical, measure N is much imporatant.)
One of the improvement method that can be suggested now is the multi-layer-Forgetting algorithm. In Learn-Forget algorithm, the forgetting occurs only once. But real human forgets things gradually. So multi-layer-Forgetting algorithm breaks forgetting procedure into some procedure with the training rate divided by the number of the procedure. For example, the 30(day)-3layer forgetting keeps 3 forgetting procedures in every 10 (days) with 1/3 training rate. This simulates "gradual" forgetting.