Bus Recognition and Prediction
Blaine A. Bell
Jared D. MacDonald
CS4721 - Advanced Intellegent Systems
May 13, 1999
Introduction
Our system introduces a novel domain for the traditional neural network. The new domain is real-time bus recognition and schedule prediction. It grew out of a practical desire to create a system that would attempt to predict when the next bus would arrive based on previous arrival times. Previous arrival times would be recorded using images captured from a real-time video feed from a camera pointed at the bus stop (which is conveniently located outside a team member's apartment and viewable from his window). The system would determine vis-a-vis the images when the bus had arrived, record the arrival time as one instance, and return to its normal state when the bus departed. After collecting a series of these instances, the future schedule can be guessed based on the previous information collected.
The utility of such a system is fairly obvious, if the system is accurate: ideally, it would provide some sort of feedback to the user that the bus is going to arrive in a certain number of minutes. The accuracy of the system depends on two critical factors: one, the ability to recognize a bus in varying positions, light and shadow configurations, etc.; and two, the actual presence of a pattern, however complex, of the bus's arrival times.
Hence our approach was to compose the system of two parts: one, a bus recognizer; and two, a schedule prediction mechanism: an image neural network running on one end, and a temporal neural network running simultaneously at the other end. The results were as successful as could have been expected. There an infinite number of factors that influence the bus schedule, (i.e. bus schedule, traffic light schedule, reckless cab drivers, handicapped passengers, etc.). Even though these factors are not directly measured by the system, the neural networks provide a close enough approximation to advise someone when to leave their apartment so that they will not need to wait in the cold, snowy weather.
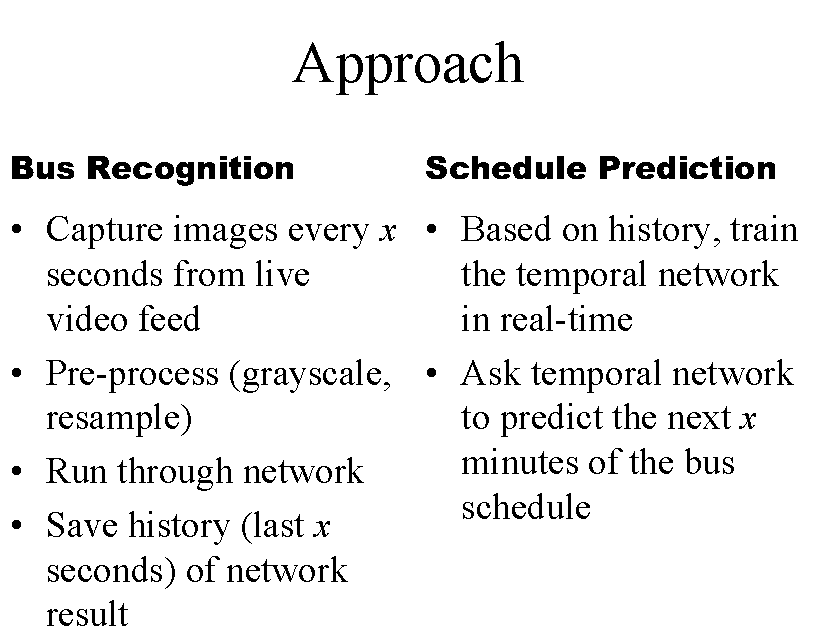
Approach
Part I: Bus Recognition
Bus recognition was matter of reworking the face-recognition neural network code, which required very little to be changed. All training was performed off-line, and two types of testing were performed, one off-line and one on-line.
To train the network initially, we created a program to capture images at a certain interval from the video feed and save each to a file whose name was the date and time, followed by an 'N' signifying that we don't yet know whether the image has a bus in it or not. We wrote a utility to load up these images and allow manually marking them, in batches or individually, as having a bus or not (this meant changing the 'N' in the filename to a '1' or a '0').
These images, which the camera's image utilities saved as color BMPs, were then resampled to 30x30 black-and-white PGMs and distributed into training and test lists, and the network was trained. Because the testing list was still taken from the same batch of images, the real testing process came when the resultant network was plugged into the video feed and asked to determine, in real-time, whether the bus was present.
The network was retrained four times during the course of our experiment, each time as the result of an inability to recognize a class of images. For example, initially we recorded a series of images from Sunday afternoon with certain lighting. The network, therefore, was trained with total success to recognize that class of images.
Part II: Schedule Prediction
Schedule prediction begins when the network is able to recognize the bus in a live-video feed, and the program could record over time the output of the network. The output over time is recorded and displayed as a graph of the output node (range 0 to 1) that shifts to the left with each new image.
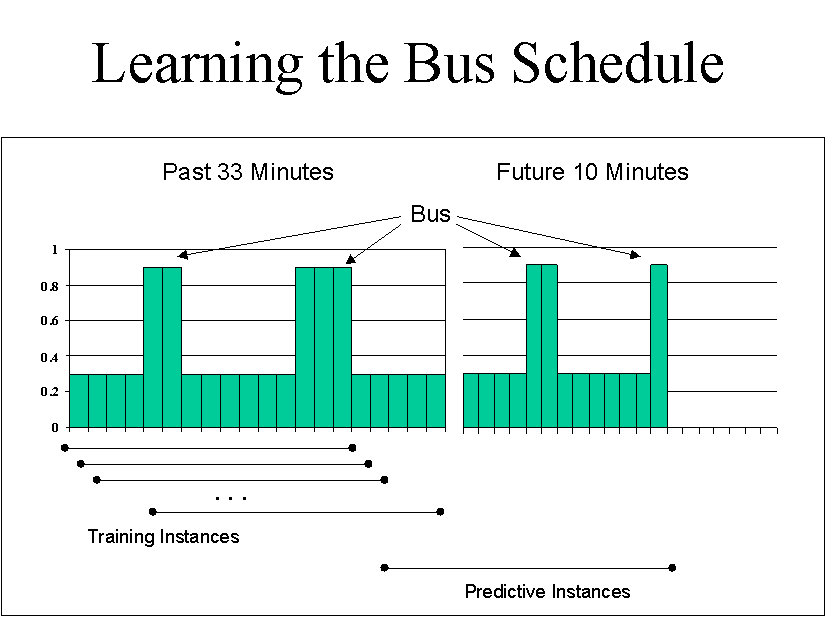
The idea behind a temporal network is, given a number of values at times t(0), t(1), …, t(n), determine what the value will be at time t(n + 1). In our system, the temporal network begins to make inferences after a specified amount of time, namely, n time units. In our implementation, a time unit was five seconds. Since the live video feed was not measured at completely consistent intervals, a conversion needed to be calculated. It is possible that multiple images could be captured in a 5-second interval, and it is possible that no image is captured inside the interval. In these cases, it is necessary to convert the data so that each 5-second interval has a value that accurately represents the output of the bus recognizer without changing it. If there are multiple values, they are simply averaged. If there are 5-second intervals (sometimes many in a row) that are empty, we simply interpolate the two values from intervals that are closest to the one being set. This was done for the sake of simplicity.
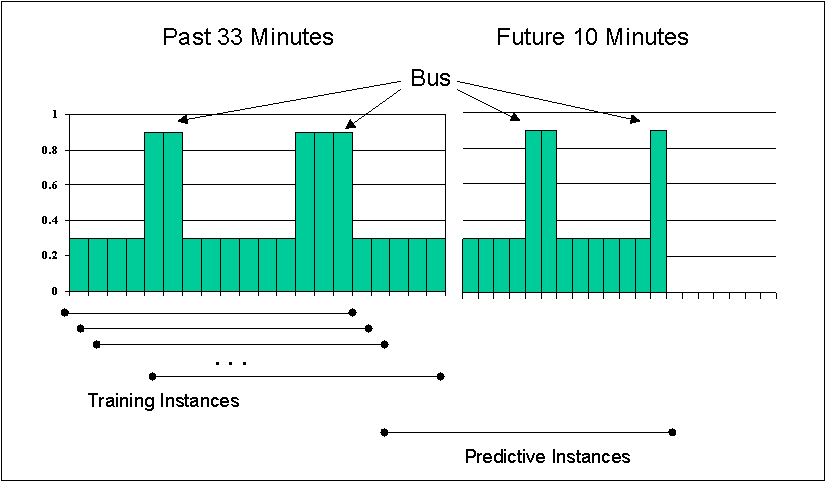
fig. 4
For predicting the bus schedule, it was necessary to be able to predict a certain temporal interval, namely the next temporal interval in the future (figure 4). This interval could consist of more than just one time unit. In our system, we wanted to predict the next ten minutes of the schedule. In this case, instead of merely predicting time t(n + 1), we are predicting a number of times t(n + 1) through t(n + x).
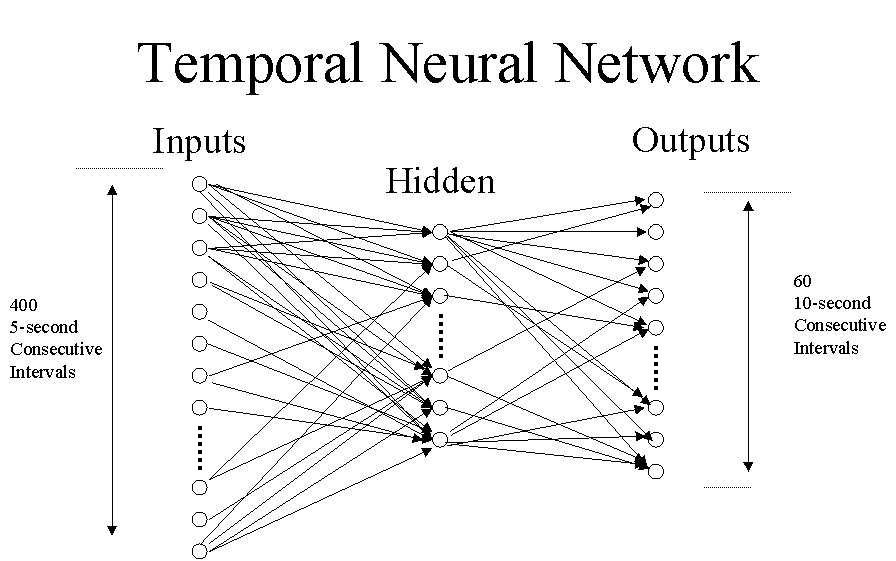
In our case, the input size to the neural network was 200 input nodes of five-second intervals each (16 minutes, 40 seconds). The output size was manipulated between an output size of 10 nodes of 1 minute each and 60 nodes of 10 seconds each (10 minutes). In order to train the temporal network, it is necessary to have history information of at least the sum of the inputs and output nodes (16 min, 40 sec + 10 min = 26min 40 sec). Therefore, this history information can be feed to the network as training examples. For our system, we kept a previous history of 400 time intervals (33 minutes, 20 seconds). Any log that is older than 33 minutes and 20 seconds is deleted. Also, for each new image, the network is trained for each window of data is 26min, 40 sec. For example, if there are 400 time intervals that are captured, (our system has been on for 33min, etc) then when an additional image is captured, we train our network for 400-200-120=80 times. This is because there are 80 possible intervals that are different within the complete 400 time intervals. For each training example, the inputs are set to the oldest history values in an interval and the targets are set to the history values directly after the values set for the inputs.
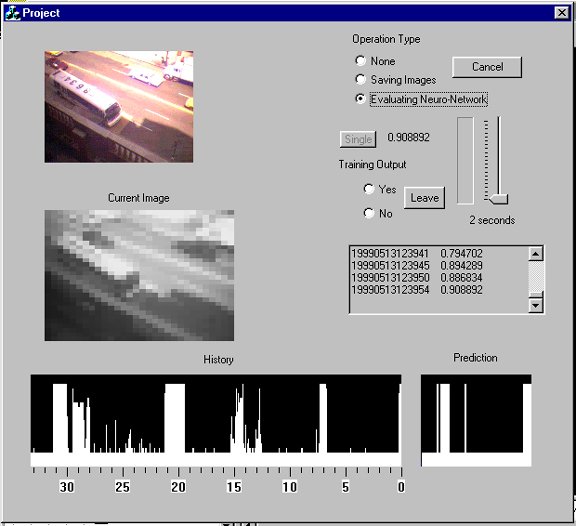
After the new image is captured and the temporal network is trained, the network can then be evaluated. This is done by using the most recent history as input. The network is used to calculate the output, which is used as the projected schedule. The history is shown on the bottom left hand of the user interface while the projected schedule is on the bottom right.
Results
Before we discuss the big-picture results, namely, the system’s success at predicting the next bus, we should first discuss the results of the smaller steps.
Bus Recognition
Bus recognition was the first hurdle. We initially attempted a high resolution (175x150), black and white version of the images. With these, however, the neural network showed bizarre results: for example, the system’s output node would either be always off or on, regardless of the input image. We are not quite sure why this is the case, but we believe that since there are so many more pixels, the neural network would require many more training cases than for previous, small image systems. Also, given that there are many more input pixels, the required number of hidden nodes would increase exponentially. We did not have time nor the resources to attempt these hypotheses.
We decided to reduce all the images to 30x30, since this was almost the size of the images in the face-recognition example. This produced successful results immediately, as the success rate of the network on both the training and test cases approached nearly 100 percent (fig. 5). This was roughly the case with every iteration of the network, with every new set of images.
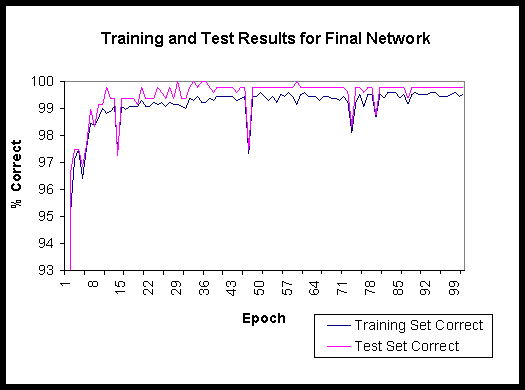
Fig. 5
When applying the network to the live video feed, the results were very interesting. At times it produced very consistent results, like it showed during the test cases during training. However, the images were captured during different times of the day and different days.
The first problem we had was that the first set of images were captured on a Sunday. Normally, you would not think that this would cause any problem because the bus schedule doesn’t have an effect on recognizing a bus. However, the bus stop is located directly in front of a parking zone that cars are only allowed to park in on Sundays. Furthermore, on Sundays, there are people that are in the process of moving into and out of Blaine’s building. This sometimes causes trucks and vans to park half way inside the bus zone (illegally). This makes the bus drivers stop further back and further towards the center of the street. So when these images were used to train the network that was used on Monday, the results were not as good as we thought they would be. The reason for this was that the bus would, on average, stop in places in which we did not have any training images.
Another variable besides bus location was sun and shadow position. Given that the bus parks along a sidewalk that borders tall buildings, the position of the sun has a dramatic effect on what the images look like. The bus stop can be entirely lit, in partial shade or entirely shaded depending on the time of day.
However, the network seems robust enough such that whenever we captured a series of images of the bus’s new location or new conditions, and retrained the network, it would then perform well for that scenario, recognizing the bus in the video feed. The real challenge, therefore, is having the network recognize the presence of the bus given lighting conditions or a bus location that it has not yet seen.
The network seemed to be very sensitive to movement. If the camera was moved, or replaced in a position that was not exactly what it was before, the results fluctuated. Although this was a problem at first, measures were taken to allow us to move the camera back to the original place.
The actual statistics for bus recognition are as follows:
|
Accuracy |
Iteration 1 |
Iteration 2 |
|
% of false positives ([images without a bus recorded as having a bus] / [total neg. images]) |
8.426 |
2.723 |
|
% of false negatives ([images with a bus recorded as not having a bus] / [total pos. images] ) |
23.145 |
4.263 |
Schedule Prediction
Because of the initial difficulties in getting bus recognition to work properly, schedule prediction could not be tested until the last minute of the project. Our initial results, however, were promising. By watching the network predict the next 10 minutes, we saw that it was definitely learning the frequency of the previous instances. Also, it demonstrated the ability to move the bus arrival time closer to the present as the last bus arrival moved further in the past. In other words, the predicted instance of the next bus would move with time to the left at the same rate as the actual instances of buses moved.
We were not able to calculate concrete results of the schedule prediction. In order to do this it would be necessary to calculate the difference between our predictions and what actually happened. However, this would only answer whether the network was "exactly" right for a given prediction. Although we believe that it is an adequate predictor, we do not believe that these results would be promising. Instead, we would need to calculate "how" close was each prediction by measuring the distance between the prediction that a bus would come and when it actually did. This is more complicated because of the multiple predictions at each time point, and therefore not completed for this project. However, from watching the program for a certain amount of time, we believe that these results would be good.
Conclusions
This project is a good example of how neural networks can be practical in every day life. We have explored the processes in which to make these applications available. But most importantly, the results of our project were successful. Since there were so many variables in the equations to figure out our problem, we did not care about the majority of them. We let the neural network handle them. Although our results by themselves prove to be promising, what is more promising is that we have learned that there are so many improvements that can be made. These improvements consist of pre-processing the images so that it could be easier for the bus recognizer to do its job. The major problem with the development of this system is that one component relies on the other. The Scheduler cannot be developed without an accurate bus recognizer. At early stages of the project we thought about writing some vision code to account for the bus recognizer so we can develop the scheduler.
Although we realize that this system has enormous potential in other domains, this system does not have a practical use in the future. This is because (hopefully) the bus company (MTA) will track the buses with either GPS or radio waves to find out where the positions are. These positions will be used to calculate approximate arrivals at each bus stop. This potential system will eliminate the use of our system. However, this future system could still be improved by addressing the accuracy of the "approximate" arrivals of each bus, i.e. how long it takes to get from one place to another. These values will need external variables such as the traffic light plan and other car's plans. This data might not be available. Therefore, we suggest that the answer to unknown data (whatever it might be) is Neural Networks. The evolution of systems like this in the future could implement Neural Networks as a basis, and once more information is found, phase the networks out to concentrate on other "unknown" data. There will always be unknown things in this world, therefore, there will be a need for Neural Networks.
More importantly, we provide the user with an accurate depiction of what happened in the past, along with the prediction the computer "thinks" is going to happen. We let the user decide when he or she thinks the bus is going to come. This what makes the system versitle enough to use, that it does not hurt the situation of the humans, it can only help by making life easier.