W4721 - Advanced Intelligent Systems
Final Project
Filtering Noise from Audio Streams using a Neural Network Architecture
Ilya Gaysinskiy
isg8@columbia.edu
Introduction
Internet multimedia applications are quite popular nowadays, and these programs need to transmit large amounts of audio and video data over the network. With large corporations striving to provide high-bandwidth internet connections to the general public, the demand for such media-rich and bandwidth consuming applications is bound to rise.
Back-propagation neural networks prove to be useful in many classification tasks. Are they any help in making mainstream multimedia applications better, faster, more intelligent? That is what we wished to find out, by applying neural networks to the domain of internet telephony.
Problem
We have an internet telephony application called IPhone, which was written for a Computer Networks project in W4119 - Spring 1998. It allows people to engage in real-time voice chatting over the net. This program works pretty well in its respective domain. Unfortunately, IPhone transmits all of the sound data heard by the microphone, which includes all of the noise in the surrounding area. This leads to too much extra data being encoded and transmitted. Over a local network this leads to ~3 second lag in receiving the sound on the other end, and this will be even more over machines that are further apart.
Approach
Our idea for this project was to explore the suitability and usability of a backpropagation neural network in learning the difference between noise and voice. If there is a good performance on the part of the neural network in detecting excess background noice, we hoped to use it and filter it out noise from the sound transmission buffer. Achieving this would make IPhone more efficient and put less load on the network. We felt that this was a very worthy goal and also a very practical and useful improvement to the IPhone application, perhaps even making it commercially viable.
IPhone is a distributed Internet audio communication tool that allows people talk to each other in real time. It is written in Java and is potentially multi-platform. It has a distributed directory service backbone and allows people to login into their accounts no matter where they are. The packets transmitted during conversations are encrypted with RSA encryption algorithm.
One downside of the application is its lack of noise filtering. Everything coming to the microphone gets transmitted over the network to the other end. This may introduce some network lag especially on long network routes.
IPhone uses NetScript as its low level packet transmission tool. NetScript is an active network tool written at Columbia University. As it stands now Iphone sends over packets of 2048 bytes to the other and using NetScript boxes. Each packet is encrypted with RSA before it is sent over.
The neural network has been trained, with approximately 400 noise samples and the same number of voice clip samples. All of the training, validation and testing data were aquired from various audio sources: these include CNN live transmission on the WWW, foreign language learning cassettes (Russian) and general background noise from a microphone in our very own CLIC lab. The total number of sound files created for input are in the thousands, and we hand-checked each file to make sure that we were correctly labelling them as noise or voice. The outcome of this training and validation stage, and the related problems are discussed in the results section.
In order to utilize the neural network results, a separate process is spawned in the beginning of the conversation and IPhone keeps checking with the neural network in order to figure out whether to send each subsequent packet of sound it receives from the microphone. In order for the neural network to process a packet of sound, the 2048 bytes read from the microphone (in Sun AU format) is transferred into PGM format that the neural network understands. If the neural network decides that the packet contains only noise, IPhone does not send it over thus saving on network traffic and time delay for the following packets to be processed and sent over.
Results
The modified version of IPhone is available here.
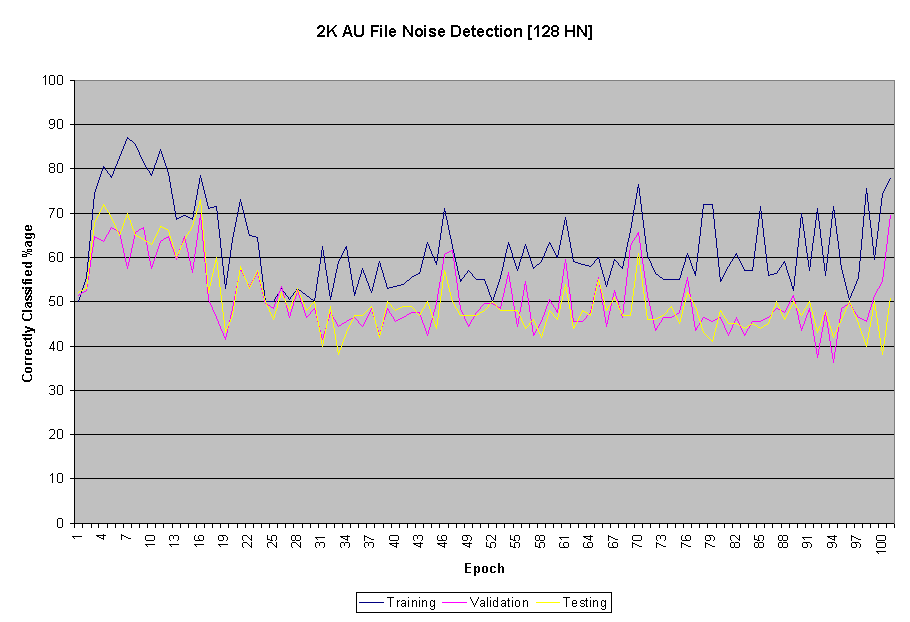
During training, the neural network classification accuracy fluctuated as is shown and described with the three graphs below. Local minima in the hypothesis space played a big role in this behaviour, but after repeated tries to use various momentums, learning rates, input representations and number of hidden nodes, the neural network behavior did not improve in a consistent way.
As part of the experiment various neural network parameters were tuned to produce the optimal network for our purposes. In the beginning, we ran into various problems. Having started with 32 hidden nodes we encountered a problem where the accuracy was not changing from 50%. Tuning momentum and learning rate did not result in any significant changes. We decided to increase the number of hidden layers and after experimenting with different number of them (some of the graphs are below) we reached an adequate network.
Above image: 128 hidden nodes, 0.3 momentum, 0.3 learning rate, CNN + language files. 200 training, 99 test, 100 validation.
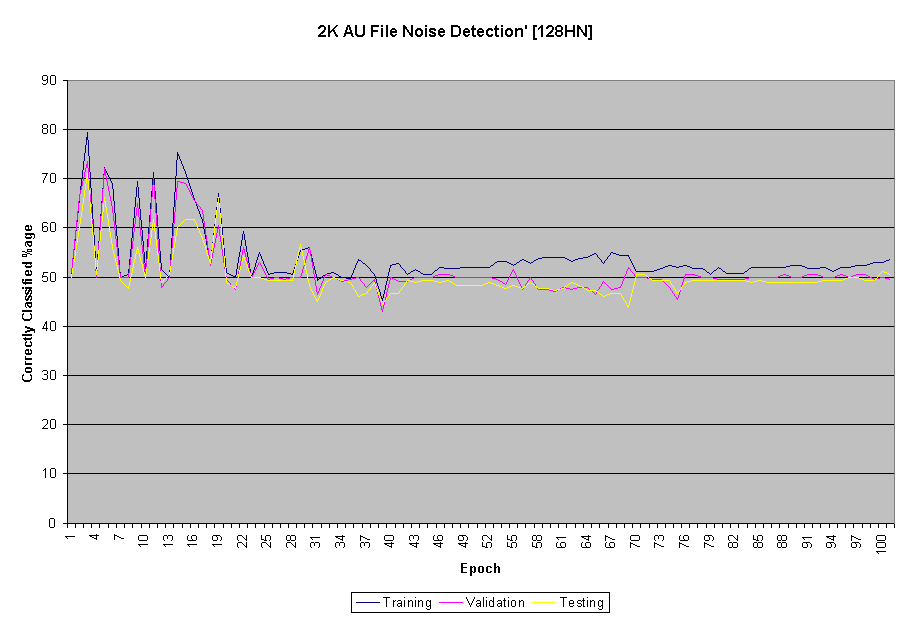
Above image: 128 hidden nodes, 0.3 momentum, 0.3 learning rate, Only language files. 400 training, 200 test, 180 validation.
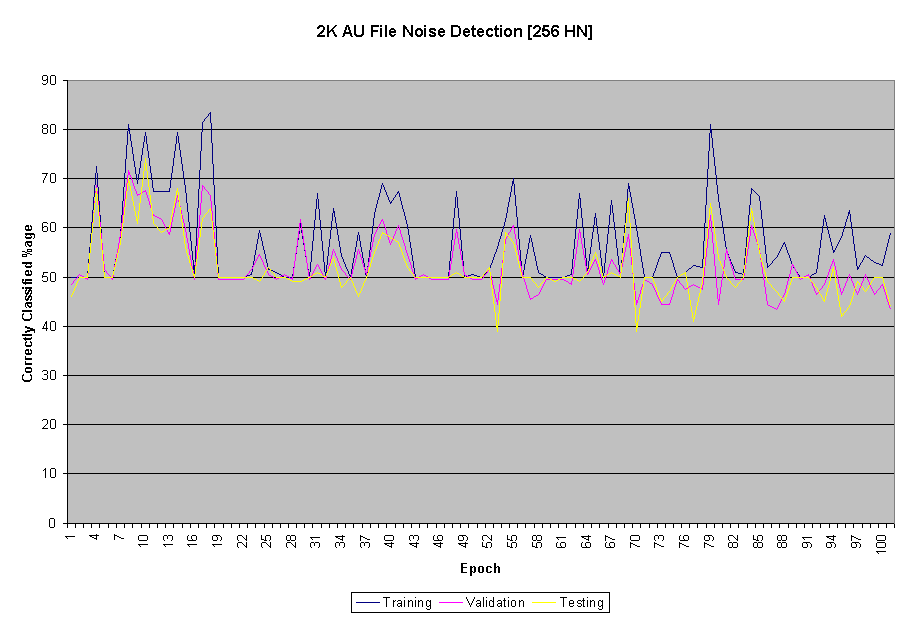
Above image: 256 hidden nodes, 0.3 momentum, 0.3 learning rate, CNN + language files. 200 training, 99 test, 100 validation.
Conclusion
Even though audio clip classification accuracy may not be that great with this simple neural network architecture, there was one advantage to tackling the domain of human speech: the fact that natural language (especially is the spoken case) is very redundant, and some misclassified voice packets that may be dropped are harldly missed. The understandability of the speaker on the ohter end is not decreased by very much.
This project was an interesting learning experience for us. It is obvious that simple backpropagation neural networks will not suffice for multimedia tasks, expecially due to the large size of input that media files generate. This may be alleviated by more complex neural nets, with multiple hidden layers. But this cannot be stated with any guarantees, because neural network behavior is difficult to predict a priori.
Presentation Slides
Slide 1 | Slide 2 | Slide 3 | Slide 4
___EOF___
{kind=link}
{kind=link}
{kind=link}
{kind=link}