Preparing Data for Training an HTS Voice
This tutorial assumes that you have
HTS and all its dependencies
installed, and that you have successfully run the demo training
scripts. This site does not provide comprehensive info on
installation as this is included in the HTS README. However, some
notes on installation and various errors you might encounter can be
found here.
These are instructions for preparing new data to train a voice using
the HTS 2.3 speaker-independent demo. For information about
speaker-adaptively training a voice and other variants, please see
the variants page.
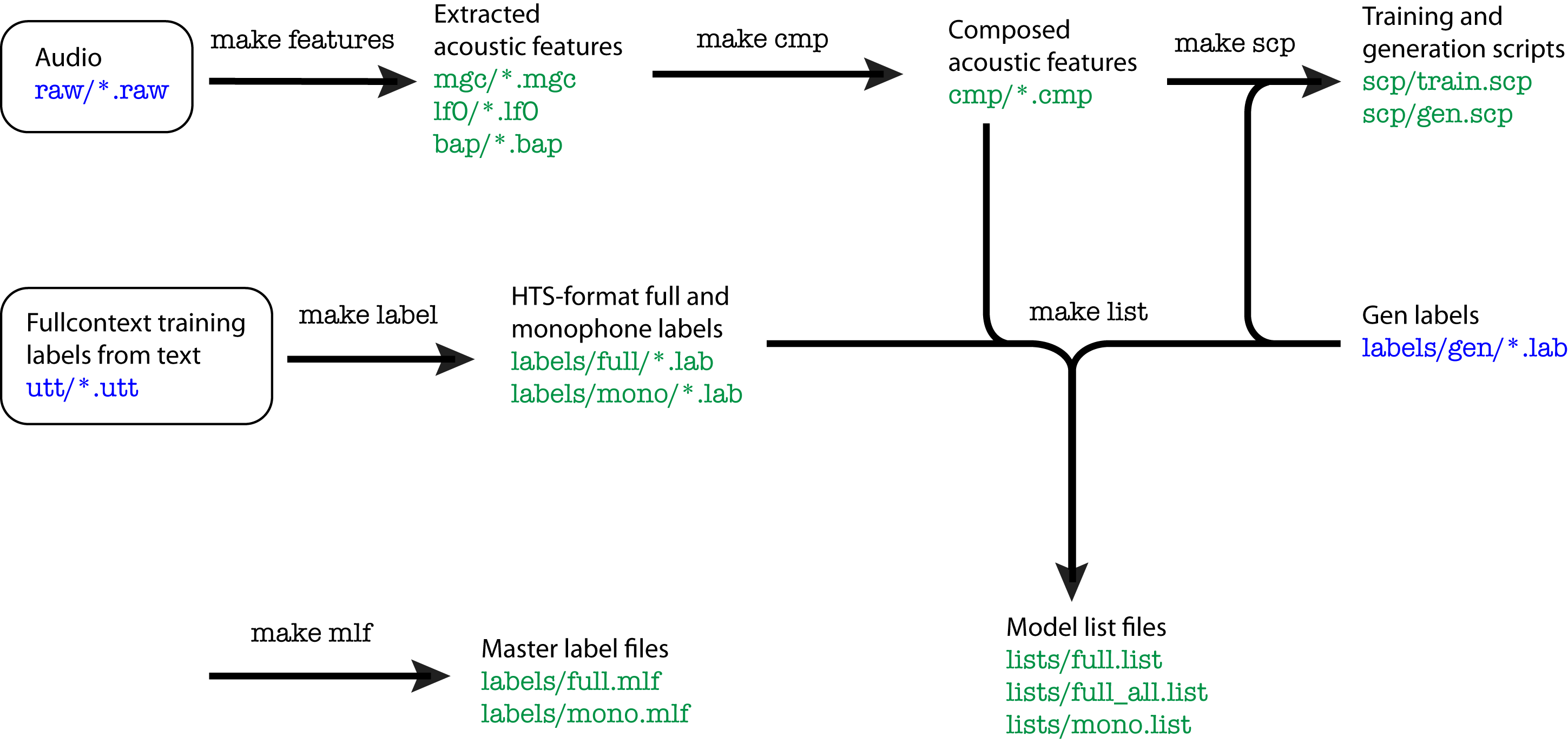
In the diagram above, the blue items are files you must provide before
running the HTS data preparation steps, and the green items are the
output created by each step.
Note that .raw and .utt files are not required by the actual training
demo scripts, so if you have your own way of creating acoustic
features or HTS-format .lab files, you can just drop those in.
0. Background: Acoustic and Linguistic Features
There are two main kinds of data that we use to train TTS voices -
these are acoustic and linguistic, which typically start out as the
audio recordings of speech and their text transcripts, respectively.
The model we are learning is a regression that maps text (typically
transformed into a richer linguistic representation) to its acoustic
realization, which is how we can synthesize new utterances.
The acoustic features get extracted from the raw audio signal
(raw in the diagram above, in the step make
features); these include lf0 (log f0, a
representation of pitch) and mgc (mel generalized cepstral
features, which represent the spectral properties of the audio).
The linguistic features are produced out of the text
transcripts, and typically require additional resources such as
pronunciation dictionaries for the language. The part of a TTS system
that transforms plain text into a linguistic representation is called
a frontend. We are using Festival for our frontend tools. HTS does
not include frontend processing, and it assumes that you are giving it
the text data in its already-processed form. .utt files are
the linguistic representation of the text that Festival outputs, and
the HTS scripts convert that format into the HTS .lab format,
which 'flattens' the structured Festival representation into a list of
phonemes in the utterance along with their contextual information.
Have a look at lab_format.pdf (which is
part of the HTS documentation) for
information about the .lab format and the kind of information
it includes.
1. Directory Setup
To start, copy the empty template to a directory with a name of your
choosing, e.g. yourvoicename. You will then fill in the
template with your data.
cp -r /proj/tts/hts-2.3/template_si_htsengine /path/to/yourvoicename
cd yourvoicename
Then, under scripts/Config.pm, fill in $prjdir to
contain the path to your voice directory.
2. Prerequisites for HTS Data Setup
You will need each of the following to start with, before you can
proceed with the HTS data preparation scripts:
Raw audio (.raw)
Fullcontext training labels (.utt)
Generation labels for synthesis (.lab)
It is expected that you already have these before proceeding with the
next steps. Click on each one to learn more about how to create
these.
Place your .raw files in yourvoicename/data/raw.
Place your .utt files in yourvoicename/data/utts.
Place your gen labels in yourvoicename/data/labels/gen.
3. make data steps
In yourvoicename/data you will see a Makefile. We will step
through the steps in this Makefile to set up the data in HTS format.
All of these steps should be run from the directory yourvoicename/data.
3.0 Changes to the Makefile
Please make the following changes in your Makefile:
- LOWERF0 and UPPERF0: Set to appropriate values
for your dataset. A standard generic value is 75-600, but you will get better voice
quality if you tune these values to your speaker. See this page
for more information on tuning f0 extraction ranges.
- You will see this in various
places: /proj/tts/PATHTOYOURVOICEDIR/...
Make sure to replace these with the actual path to your voice directory.
3.1 make features
This step extracts various acoustic features from the raw audio. It
creates the following files:
- mgc: spectral features (mel generalized cepstral)
- lf0: log f0
- bap: if you are using STRAIGHT
You can run:
make features
3.2 make cmp
This step composes the various different acoustic features extracted
in the previous step into one combined .cmp file per utterance. Run:
make cmp
3.3 make lab
This step "flattens" the structured .utt file format into the
HTS .lab format. This step
creates labels/full/*.lab, the fullcontext labels, and labels/mono/*.lab,
which are monophone labels for each utterance. Run:
make lab
The fullcontext labels (full) contain phonemes in context as
determined by the fronted. The monophone labels (mono) are
just the phoneme sequence. Both formats have the start and end times
of each phoneme, in ten-millionths of a second, so to get times in
seconds, add a decimal point before 7 digits from the end.
3.4 make mlf
These files are "Master Label Files," which can contain all of the
information in the .lab files in one file, or can contain pointers to
the individual .lab files. We will be creating .mlf files that are
pointers to the .lab files. Run:
make mlf
3.5 make list
This step creates full.list, full_all.list,
and mono.list, which are lists of all of the unique
labels. full.list contains all of the fullcontext labels in
the training data, and full_all.list contains all of the
training labels plus all of the gen labels. Run:
make list
** Note that make list as-is in the demo scripts relies on
the cmp files already being there -- it checks that there is
both a cmp and a lab file there before adding the
labels to the list. However, it does not use any of the information
actually in the cmp file, beyond checking that it exists.
3.6 make scp
This step creates training and generation script
files, train.scp and gen.scp. This is just a list
of the files you want to use to train the voice, and a list of files
from which you want to synthesize examples. Run:
make scp
If you ever want to train on just a subset of utterances, you only
have to modify train.scp.
4. Questions File
Make sure you are using a questions file appropriate to the data you
are using. The default one in the template is for English. We have
also created a questions file for Turkish, as well as ones for custom
frontend features. Read more about questions
files here.
Errors and Solutions
- make mgc
- /proj/speech/tools/SPTK-3.6/installation/bin/x2x: 8:
Syntax error: "(" unexpected
That's because you're trying to use a 64bit-compiled version of
SPTK on a 32bit machine, or vice versa. Recompile SPTK using the
machine on which you're running.
- make lf0
- shift: can't shift that many
There is a mismatch between the speaker list and the speaker f0
range list, i.e. you have more speakers than ranges listed, or the
other way around. Fix the lists, then re-run.
- Unable to open mixer /dev/mixer
This may happen on machines that are servers as opposed to
desktops. This is safely ignored.
- make label
- WARNING
No default voice found in
("/proj/speech/tools/festival64/festival/lib/voices/")
These are safely ignored. You can also install festvox-kallpc16k
if you don't want to see these.
- [: 7: labels/mono/h1r/cu_us_bdc_h1r_0001.lab: unexpected
operator
(with missing scp files under data/scp)
In data/Makefile under scp: you need to make
sure those paths are pointing to the right place.
- make list
- [: 7: labels/mono/h1r/cu_us_bdc_h1r_0001.lab: unexpected
operator
You are missing some .lab files, make sure they are there and
being looked for in the right place.
- sort: cannot read: tmp: No such file or directory
You are missing some .cmp files, make sure they are there and
being looked for in the right place.
- make scp
- /bin/sh: 3: [: labels/mono/f3a/f3a_0001.lab: unexpected
operator
Check the paths in each of the three parts! This happens when
there is a typo in a path.
Next:
Continue on to voice training.
Notes for Columbia Speech Lab Students:
We typically keep the data separate from the voice training, since we
train many voices from the same data. Data lives
in /proj/tts/data, which contain basically the data
subdirectory for voices. Voices themselves live
in /proj/tts/voices, and the data itself is symbolically
linked into each voice's data directory to avoid copying it
multiple times. For more information about what gets copied,
symlinked, or changed for each voice, see
the voice training page notes for Speech
Lab students.