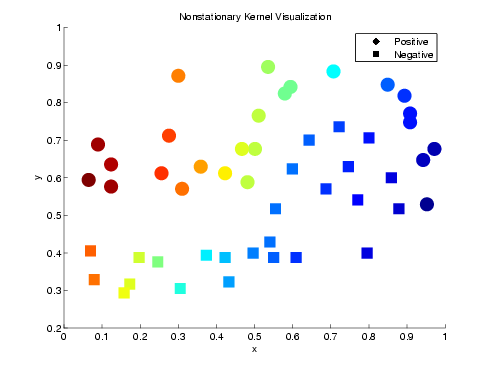
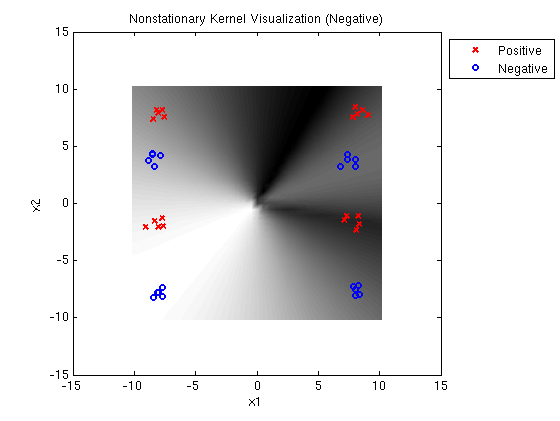
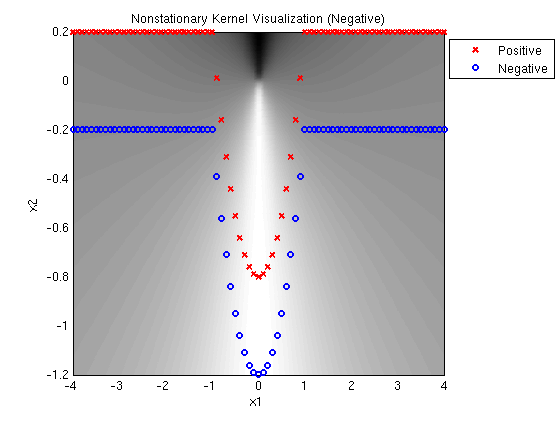
This visualization uses synthetic data to illustrate the idea of nonstationary kernel selection. We chose 162 examples at regular intervals along a function that is part linear and part quadratic. Positive examples are translated 0.2 along the vertical axis and negative examples are translated in the oppostite direction.
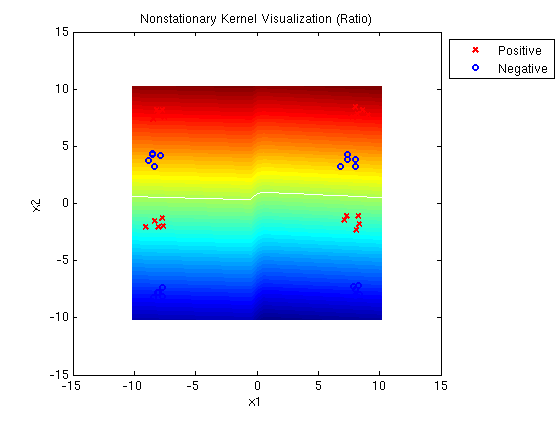
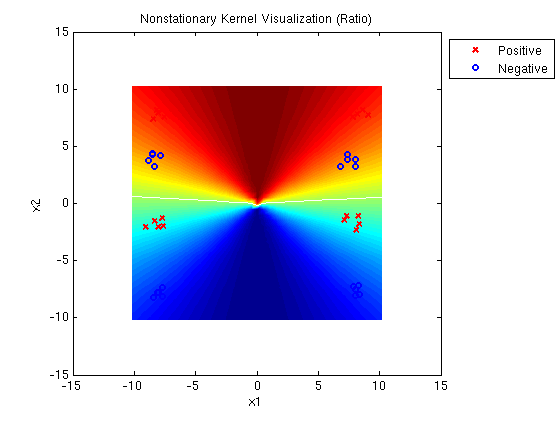
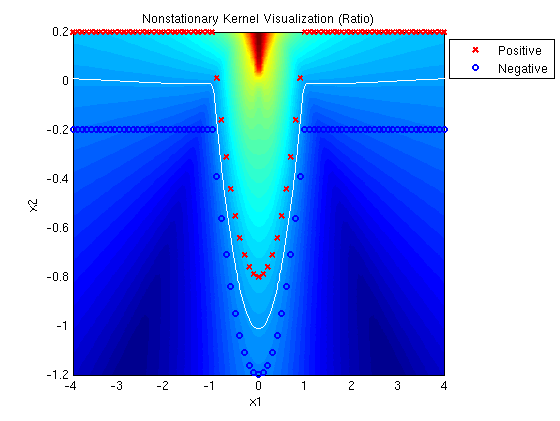
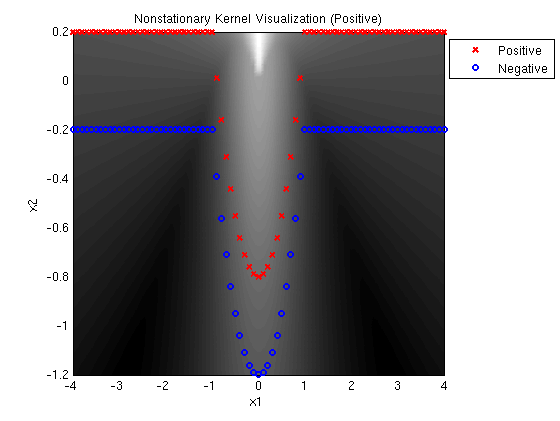
A MED mixture of Gaussians with one linear and one quadratic kernel
determines the following decision surface, which clearly
illustrates the linear and quadratic components. Note that the
solution has large margin and cannot be accomplished with a linear
combination of a linear and quadratic kernel.
The convergence of MED from a random initialization can be seen in
this AVI movie.
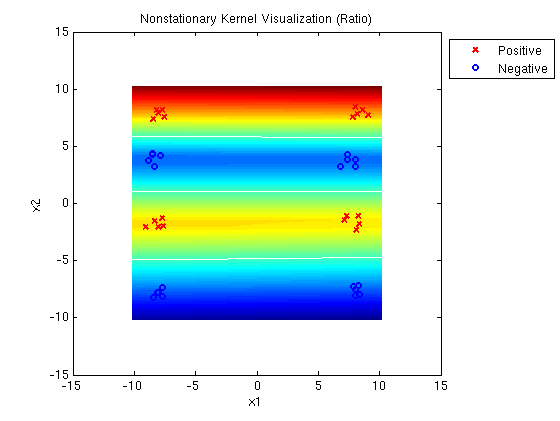
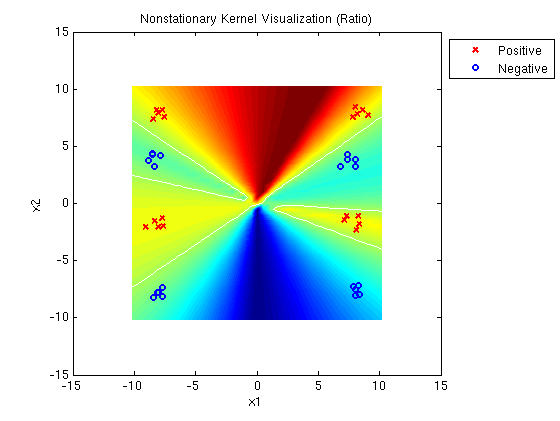
Linear-Quadratic MED ratio:
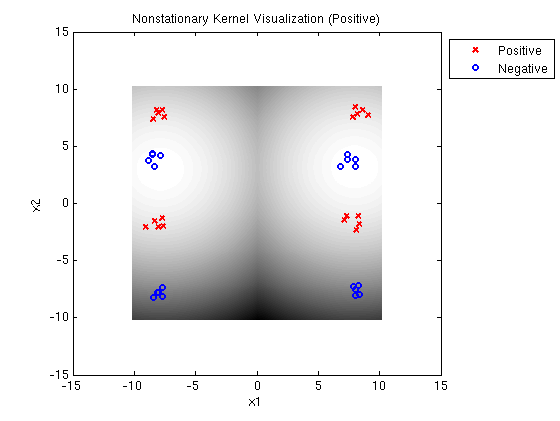
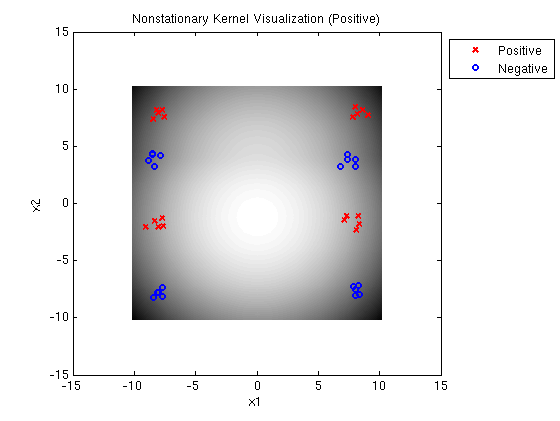
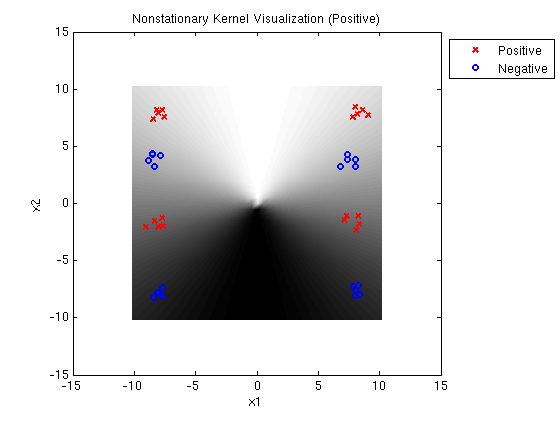
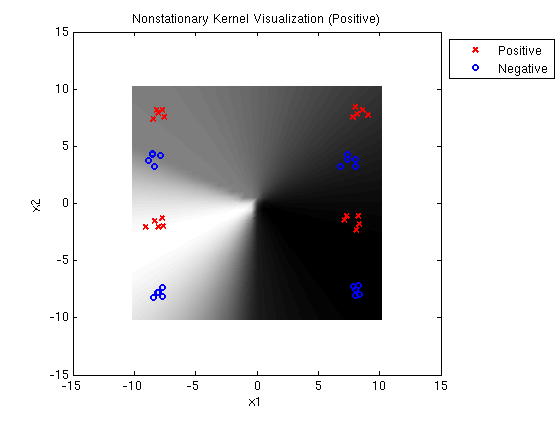
Linear-Quadratic MED positive:
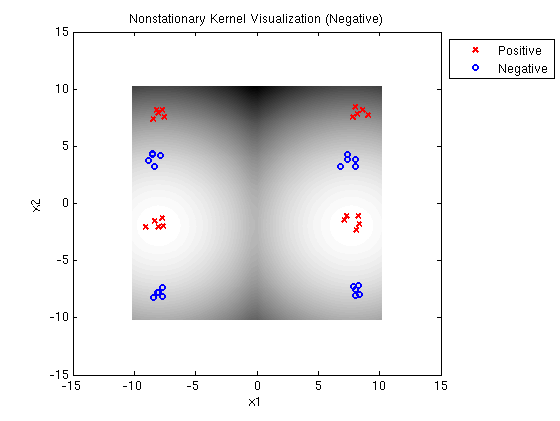
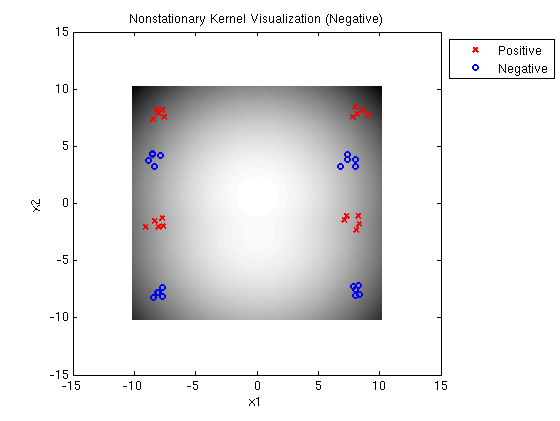
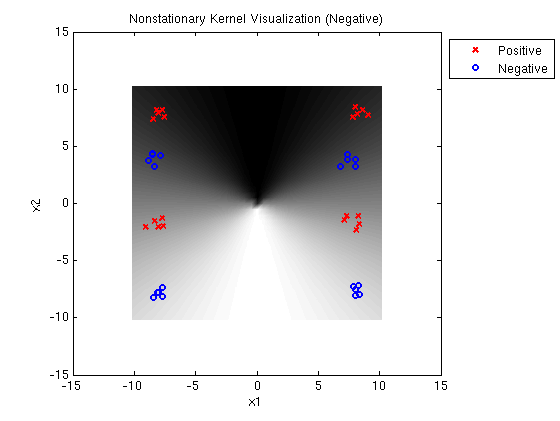
Linear-Quadratic MED negative:
Following is a plot of data that were generated from a linear and a
quadratic kernel with added noise. Circles represent positive
examples. Squares represent
negative examples. Shading indicates mixing between the linear and
quadtratic kernels at each input example when the technique is
applied for classification. (Red indicates linear kernel; Blue
indicates quadratic kernel.)