
Figure 3-1.
Communicative intent:show how to turn the dial and also indicate where the dial is
located
In order to generate automatically 3D illustrations that fulfill a specified communicative intent we formalize a system of visual communication. Effective communication requires the use of a language. Our system, thus, is designed to use a visual language comprised of primitives and rules of usage. Our language is based on the notion of the separation of design and style, and our system is based on our characterization of the illustration process as a process of trial and error.
We begin this chapter with broad overviews of the system architecture, the visual language it is designed to use, and the basis for our methodology. We then briefly describe the domains in which we have worked. Our in-depth description of the system begins with a section on the input to the system. This is followed by a section on the process itself, describing each component and the different types of rules. Next, we describe the output of the system, which is a complex object representing the illustration. We then describe how objects are represented in the knowledge-base and what types of information are used by an intent-based system.
Figure 3-1.
Communicative intent:show how to turn the dial and also indicate where the dial is
located
Figure 3-1 shows an illustration generated using our methods. This illustration has been designed by IBIS (Intent-Based Illustration System) to depict how a dial is turned on an army radio. Throughout this chapter we will refer to this illustration when describing the various aspects of the system, so that by the end of the chapter we will have explained how this illustration is generated.
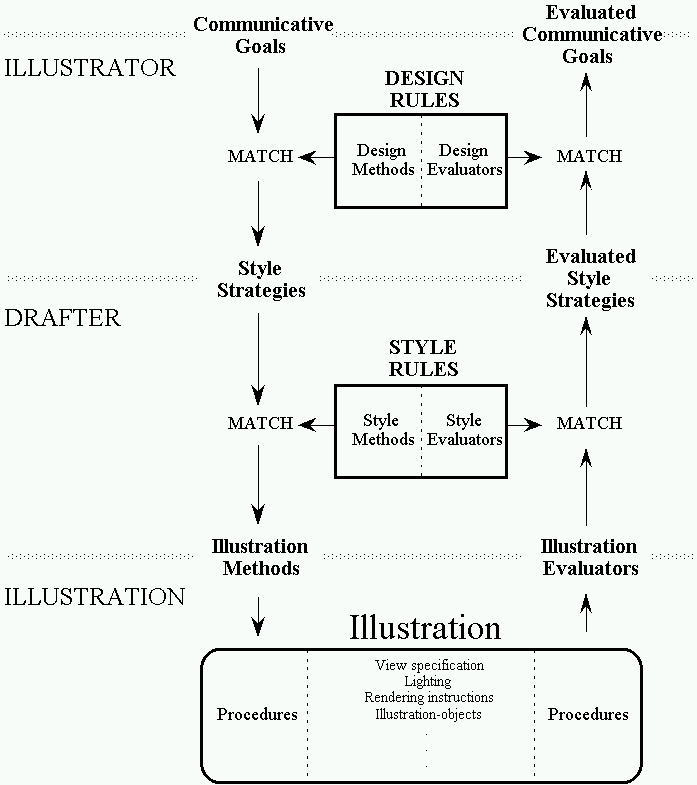 Figure 3-2. Illustration Process.
Figure 3-2. Illustration Process.
Figure 3-2 shows the architecture of our system. The illustration task is represented on three different levels handled by three separate components. These three levels correspond to the three levels with which we represent the generated illustrations. Illustrators select the illustration’s designs, drafters select the illustration’s styles, and the illustration is a complex object that includes procedures to specify and examine the current state of computer graphic picture. Design and style rules are either methods, which describe how to accomplish a goal, or evaluators, which describe how to compute a goal’s rate of success.
The top, or highest, level is handled by an illustrator. An illustrator is assigned a set of communicative goals to achieve. Communicative goals represent the input communicative intent. The illustrator accomplishes two activities by applying the knowledge embodied in the design rule base. One activity is to achieve communicative goals by choosing design methods that assign a set of subgoals, or style strategies, to the drafter. The second activity is to evaluate how well communicative goals are accomplished and thus how successful the current designs are. The illustrator accomplishes this by applying design evaluators that compute the overall success rate for a communicative goal using the evaluated success rates of the individual style strategies reported by the drafter. The illustrator applies the evaluators associated with each design to detect conflicts and adopts different designs when goals fail.
The middle level is handled by a drafter. A drafter is assigned a set of style strategies to achieve. Style strategies represent the visual effects required by the designs chosen by the illustrator. The drafter accomplishes two activities by applying the knowledge embodied in the style rule base. One activity is to achieve style strategies by choosing style methods that assert a set of subgoals that result in illustration procedures being called. The second activity is to evaluate how well style strategies are accomplished and thus how successful the current styles are. The drafter accomplishes this by applying style evaluators that compute the overall success rate for a communicative goal using the values returned by illustration evaluators. The drafter applies the evaluators associated with each style to detect conflicts and adopts different styles when goals fail.
The bottom level is maintained by a component called an illustration. An illustration is an object that includes illustration procedures to both generate and examine a rendered computer graphic. The illustration maintains a representation of the relationship between the objects that appear in the illustration and objects in the world described in a knowledge-base. The illustration procedures are higher-level than the primitives typically associated with conventional graphics systems. For example, some illustration procedures test various properties of the objects as they will appear in the generated computer graphic.
Thus, our approach is based on the decomposition of the illustration task into subgoals. The style strategies specified by design rules are the subgoals for achieving communicative goals. The illustration procedures specified by style rules are the subgoals for achieving style strategies. A division of labor is reflected by the different levels of expertise associated with each component. Illustrators know about design, drafters know about style, and the illustration itself knows about its computer graphic pictures.
A language consists of primitives and rules for their usage. The visual language we have formulated consists of three classes of primitives that represent the illustration on three levels. It is designed to support our decomposition of the illustration process as a selection of designs and styles. Communicative goals represent the input communicative intent; style strategies represent the visual cues; and illustration procedures describe how to access the actual illustration. Two types of rules are used to map one level to the next. Design rules describe the relationship between communicative goals and style strategies; style rules describe the relationship between style strategies and illustration procedures. A communicative goal is achieved by a collection of visual effects that are represented as style strategies in a design rule. A style strategy is achieved by calling the illustration procedures specified in a style rule that set the values that define the computer graphic picture.
A picture that depicts a room from just inside the door is very different from a picture that depicts that same room from outside the closed door. The lowest-level specification of both pictures (the values that define a computer graphic that are set by the illustration procedures) could be identical with the exception of the one parameter that specifies the hither clipping plane. However, the three levels of representation for both pictures would vary greatly, reflecting more accurately the difference between the two pictures. For example, the communicative intent for one may be to show some aspect of the room, and for the other, it may be to show that the door is closed. The designs of both pictures would differ, having been selected to support these different intents. Consequently, the styles would also differ, having been selected to support the different designs.
The communicative intent of the illustration shown in Figure 3-1 is to depict how the channel-knob is changed from one setting to another by turning it as well as show where it is located. The design of the illustration specifies that the channel-knob be represented in such a way that it is visible, recognizable, and highlighted. The design also specifies that parts of the radio be shown to help locate the channel-knob and that an annotation object show how the channel-knob is turned. Each of these subgoals is represented as a style strategy. The styles of the illustration specify how each object is represented. For instance, the channel-knob is depicted with the labels that mark its settings. The styles also specify that the view specification maintain the channel-knob’s visibility and recognizability, that lighting be used to highlight the channel-knob, and that a special arrow be generated to show how the channel-knob is turned. Each of these subgoals is achieved by calling the illustration procedures that set the values of the computer graphic picture. For example, one such procedure assigns additional lighting to the channel-knob, another specifies that the arrow be rendered with an outline.
The appropriate input to an intent-based illustration system is a specified communicative intent and access to an object knowledge-base. To begin with, we consider the process of illustration as goal driven. Simply stated, the illustration system is provided with a specific communicative intent to achieve, which refers to a particular world modeled in a separate knowledge-base. This scenario is analogous to a work order sent to a human illustrator who is, for example, required to illustrate how roomy a car interior is. The person placing the work order is not responsible for determining all the objects that are necessary for the illustrator to complete his or her task; instead the illustrator is given access to a wide variety of sources, and from these eventually determines what and how the task will be completed. For example, a human illustrator could have access to the objects themselves, photograph and films of the objects, geometric models of the objects, texts describing the objects, different representations of the objects, and other manuals. The illustrator may already be familiar with the objects. It may be that the illustrator does not require access to all these sources of information for each or any of the illustrations he or she creates. For example, the illustrator may be illustrating only the exterior of the car and therefore does not need to refer to what is under the hood. On the other hand, if the illustrator decides to depict the car with the hood open, then that information is necessary. The illustrator may opt to communicate the roominess of the car using completely different objects. Again, what information is needed is determined during the design process, not beforehand.
This separation of the communicative intent from the knowledge-base also enables greater flexibility. The communicative intent does not specify either what particular objects will be included in the illustration or how each will be depicted; instead the communicative intent specifies what about the objects in the known world should be conveyed through the illustration. The way an illustration conveys these concepts is to depict them, or show them. In pictorial representations, the content is a function of the form. Given a world to depict, by choosing a view of that world and rendering styles, both the form and content are determined. Communicative goals specify what aspects of the world to convey, but the stylistic choices determine what objects are used to depict those aspects. Thus, semantics are prioritized during the decision process. No decision is made for any other reason than to achieve the desired semantic value.
We apply a generate-and-test approach to the design of illustrations. Although, in the long run, this is an implementation issue, it serves to emphasize a point made earlier. All constraints in an illustration are global. Every new decision threatens to violate the success of previously satisfied goals. Each time a new decision is made and the current state of the illustration is modified, tests must be performed in order to determine which, if any, goals are now violated. This is analogous to the human illustrator imagining or viewing the result of some modification to the illustration in order to evaluate its success. The human illustrator replans, erases, increases or decreases contrast of objects, changes perspective and so on, continuously modifying and adjusting the illustration. In all cases, the end result is evaluated to determine the consequences of a decision. This can be accomplished using analytic procedures or by examining partial results in a framebuffer. How this is accomplished is purely a question of implementation. What is important is that the result of a decision is evaluated to detect goal conflicts.
Various aspects of an illustration cannot be determined until the illustration has been fully specified. Since our system depends on the success of visual effects and cues, it also depends on the ability to judge each of these visual effects. For example, consider the case in which it is important that an object appear red. Until the illustration is fully specified, it cannot be determined whether or not that object appears red in the illustration. First, it has to be determine if the object appears at all. It may be occluded by other objects or it may reside outside the view volume. Second, the object may take up so little space in the illustration that its color is illegible. Third, the lighting may be defined so that the object is so dark that it is difficult to determine its hue. These conditions can only be tested for when the view specification and viewport sizing are determined, the lighting is set, and the set of objects appearing in the scene is determined and a rendering style is assigned to each.
The separation of design and style provides a clear delineation between content and rendering. The design of an illustration specifies how to achieve communicative intent, the overall plan for an illustration, and what visual effects are needed. The style of an illustration specifies how to achieve visual effects, the individual style choices, and what illustration procedures are called. We again draw upon our characterization of illustration by a human illustrator to determine that there are two main types of decisions made during the illustration task. First, the illustration is designed. This is analogous to the human illustrator determining what sets of visual cues or style strategies are necessary to convey the communicative intent. The simplest case entails that a certain object should be depicted. However, the list of goals can be large: the object has to be seen from a certain angle, the text on that object must be legible, some part of the object must be clearly highlighted, and another object must also appear in the scene and so on. Each of these goals can be accomplished in a number of different ways. The decision to use one method rather than another to achieve each goal should therefore be based on the interaction of the various elements in the illustration itself and not determined beforehand.
For example, suppose we need to show where a building is located. There are several designs we can adopt to achieve this goal. We can draw some kind of map, or we can draw a picture of the house with a street sign clearly in view, or we can show the building with a label displaying its address. These different solutions differ in design because the visual cues used to depict location are different. In the first solution we have chosen to depict part of the city, in the second part of a block and sidewalk, in the third just the building. In each design, though, the building itself is depicted, but how? It may be depicted photorealistically, as a simple line drawing, or iconically. These solutions all differ in style, and each design could be achieved using any one of these styles. Thus, there is a clear distinction between the high-level design goals as opposed to the lower-level style goals. Design decisions should not involve issues such as in what particular shade of gray the building should be drawn; since drawing the building in that particular shade of gray will not necessarily convey its location. Thus, the separation of design from style is enforced by a division of labor between two components: illustrators select design rules while drafters select style rules.
The methodology presented in this study is intended to be general rather than object domain-specific and can be adopted for a wide variety of applications and output devices. In an attempt to demonstrate the versatility of our methodology, we have focused on two main domains; other smaller domains have been modeled to demonstrate specific functionality. The system we have implemented as proof of concept, IBIS (Intent-Based Illustration System), generates illustrations for each of these different domains. In this section we will describe our primary domain, COMET and its army radio object-domain. However, IBIS also generates illustrations of other object-domains (such as the dice world shown in Chapter 1) and the laser-printer for KARMA, as described in Chapter 7.

Figure 3-3. The COMET display showing automatically generated text and graphics.
We began by considering the graphics needs of the multimedia explanation system COMET (COordinated Multimedia Explanation Testbed) [Feiner and McKeown 90, Feiner and McKeown 91] and its army radio domain. This domain is the principal domain for our work. The types of things COMET explains range from the placement of the radio to performing complex diagnostic tasks. Figure 3-3 shows a COMET explanation for turning the channel-knob generated during an interactive session. In this example, the user has requested instructions to troubleshoot a loss of memory. The text and graphics have been automatically generated to comply with the user’s request that the system explain with greater detail how to clear the holding battery’s memory.
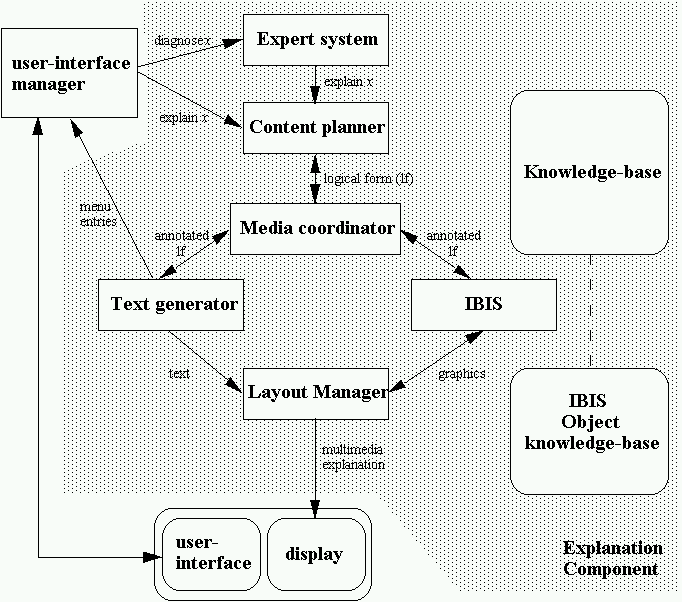
Figure 3-4. COMET’s architecture.
Figure 3-4 shows COMET’s architecture. COMET’s content planner [McKeown 85] generates a logical form [Allen 87] specifying what needs to be explained to the user. This logical form is shared by all the media generators [Elhadad et al. 89, Elhadad et al. 91]. COMET’s graphics generator is IBIS and COMET’s text generator[McKeown et al. 90] consists of FUF [Elhadad 91, Elhadad 93] and a lexical chooser [McKeown et al. 93]. A media coordinator annotates this logical form by assigning the communicative goals specified in the logical form to different combinations of the media generators. For example, visual information is typically assigned to the graphics generator, identity information is typically assigned to the text generator, and location information is assigned to both. The illustrations IBIS generates for COMET are fully shaded 3D graphics and are displayed on a high-resolution graphics display with the generated text as shown in Figure 3-3.
A COMET user selects from a menu of tasks and diagnostic procedures. The presentation is not static; the user can interact with the system to request further explanation, greater detail, answers to additional queries, and the user can manipulate the generated illustrations. These interactions are described in Chapter 6. The graphics generated for COMET are designed to correspond, both in function and appearance, to the graphics found in an illustrated printed manual.
COMET provides a suitable domain for our work. The army radio domain is well documented and real. Early versions of the printed manuals used by the army personnel to maintain and use the radio provide us with concrete examples as well as a point of comparison and the texts that outline how instructional manuals should be written and designed provide us with style guidelines. Additionally, because the input to IBIS is generated for the text generator as well, it is not hand-tailored for a graphics component. This input accurately reflects the content of needed explanations in a real world domain.
The communicative intent is represented by an ordered list of communicative goals. Each goal is assigned a threshold value that represents the minimum required degree for success. For example, the communicative intent for the illustration shown in Figure 3-1 is shown in Figure 3-5.
(change channel-knob turn position-1 highest)
(location channel-knob medium)
The intent is to show the user how to turn the channel-knob to position 1 with the highest priority and, at the same time, show where the channel-knob is located with medium priority. Our system evaluated the illustration shown in Figure 3-1 as achieving both goals successfully. The ordering of the goals represents the order in which each should be handled, while the threshold represents importance. If, for example, we reversed the order of the goals, then the illustration designed could be different. These differences are unimportant since in all cases the illustration will be evaluated to have achieved the minimum degree of success for each goal. In this example, the illustrations generated would be the same.
Our system is designed to be general, so that different object domains can be handled without requiring that the rule base be changed. Part of the input to the system consists of a knowledge-base describing the objects. Each object representation consists of two parts. The first part consists of the standard information used to render 3D objects: a set of coordinates that define its surface, its material, location and orientation. The second part includes information necessary for intent-based illustration such as an object’s name, it parent, and what aspects of the object are important to show so that it is recognizable or understood. In Section 3.9 we describe how each object is represented.
The input can also consist of other types of specialized knowledge such as special rules for certain classes of objects, specific objects, and different output media. For example, the illustrations of the radio domain are specified with a knowledge-base that describes over two hundred objects; while the knowledge-base used to generate the illustrations of the dice shown in the figures in Chapter 1, consists of just five objects. Only one specialized rule, in this case a concept-specific rule, was introduced to generate the illustration depicting the “roll” of the dice shown in Figure 1-4. Otherwise, the rule base is identical for both domains.
Illustration can be characterized as a process of trail and error. Human illustrators may be capable of imagining the results of a series of illustrative techniques and in doing so may visualize the results. Our system, must also, determine what the results of a decision will be in order to detect when goals have been achieved or violated.
Our approach is based on the idea that visual effects depend upon certain conditions. It is by identifying these conditions and then testing for them that our illustration system can determine when the desired set of visual effects is successful. If they are not successful, then alternative plans should be applied. For example, the style strategies are representations of visual effects whose success depends upon the elements of an illustration and the properties of the objects in the real world. The appearance of each object in the illustration is unknown until certain aspects of the illustration are specified. It is for this reason that a goal’s success cannot be computed beforehand. Similarly, although previous decisions can be used to rule out certain methods, methods cannot be guaranteed to be successful until all methods are applied and the illustration is completely specified.
For example, a highlighting procedure that simply outlined an object in red would fail if applied to a red object against a red background or if other objects in the illustration were colored in red. In the first case the highlighting would be obscured, in the second case, the technique may not be noticeable. In the first case, the background object’s color value needs to be determined. This can be accomplished only once a view specification and rendering information for all the objects in the scene is specified. In the second case, the other objects’ color values need to be determined. Again, this is dependent upon the lighting and view, since white objects lit by a red colored light will appear red, while red objects in a dim light may appear black.
The application of different methods must therefore be based on the eventual outcome. The visual language we use is designed to represent the fundamental properties of certain visual effects as well as their communicative value. It is these properties that must be continuously evaluated during the illustration process.
As shown in Figure 3-2, communicative goals match with a design method in the illustrator’s design rule base. The design method asserts a set of style strategies. Style strategies match with style methods in the drafter’s style rule base. This, in turn, activates a set of illustration methods that access the illustration-object directly. Corresponding style evaluators activate a set of illustration evaluators that also access the illustration. The illustration evaluators match with style evaluators to assert the success ratings for style strategies. The evaluated style strategies match with design evaluators and assert the success ratings for communicative goals. The process is dynamic. Any change may activate a new evaluation and thereby alert the system when a goal has been violated.
Our current implementation employs just one inference engine controlling the three components shown in Figure 3-2. During the illustration process only one component is active at a one time. However, our architecture is designed to easily enable a multi-processor implementation, in which communication between the various components is handled by message passing of the goal activations and evaluations that are currently asserted in working memory.
Illustrators are the components that select and apply design rules. They know how a visual language is used to achieve communicative intent. An illustrator is assigned a set of communicative goals to fulfill. It selects a set of designs to accomplish these goals. The designs require that style strategies be both applied and evaluated. The illustrator is not aware of how each visual effect is achieved, how the objects appear, or their geometries. The input communicative goals, therefore, need not be encumbered with the knowledge necessary to either render the objects or make style decisions. The illustrator is responsible for the overall design of the illustration. It decides what concepts to depict. Not only does the illustrator determine what visual cues to use, but it assigns importance to each of these.
Drafters are the components that select and apply style rules. Drafters do not know about communicative intent. They are the unheralded workers who translate the illustrators’ plans into reality. A drafter is assigned style strategy goals, but is not aware why it has been assigned these particular goals. A drafter is tied to the hardware it utilizes. For example, it is a drafter who calls the illustration procedures that examine the color of an object as it will appear on the display or to modify the lighting of the scene. The drafter is responsible for the specific style choices used in the illustration. It decides how objects will appear.
An illustration is a complex object consisting of data and procedures. It is described in greater detail in Section 3.8.
We have chosen to represent the decomposition of goals into subgoals with two types of rules. Methods describe how a goal is achieved by a set of subgoals, while evaluators describe how well a goal is achieved based on how well subgoals have been achieved.
Each goal is assigned a threshold for success. This threshold represents the minimum value at which it is necessary for the goal to be successful. Thresholds are represented numerically with values corresponding to: highest, high, medium, low, lowest. Some evaluators are designed to return just one particular rating. A goal that must be achieved with the highest rating must be evaluated as successful by an evaluator designed to test success at the highest degree. A goal that must be achieved to a high degree is deemed successful if an evaluator for high or highest returns successful.
Figure 3-6 shows how methods are represented. The rules are implemented in the Clips production language [Culbert 91]. In the interest of clarity, we will use simplified versions of the rules. The first line is reserved for the name of the rule. Comments are preceded by “;”. The conditional portion of the rule precedes the arrow. Variables preceded by “?” indicate single values, while variables preceded with “$?” indicate lists (of zero or more length), other symbols must match exactly. Thus the goal and threshold must match exactly to fire the method. The expressions following the arrow indicate what actions to take when the rule is fired. Subgoals are asserted by methods that are assigned to the appropriate component. Thus subgoals 1 to n are asserted when the rule is fired.
(method-for-goal-at-threshold
;; ASSIGNED GOAL
(goal ?object $?args threshold)
=>
ASSIGN TO SUBORDINATE:
(subgoal1 ?object args1 value1)
(subgoal2 ?object args2 value2)
.
.
.
(subgoaln object argsn valuen)
)
(evaluator-for-goal-at-value
;; EVALUATIONS FROM SUBORDINATE
(evaluated subgoal1 ?object args1 ?value1:>= threshold1)
(evaluated subgoal2 ?object args2 ?value2:>= threshold2)
.
.
.
(evaluated subgoaln ?object argsn ?valuen:>=
thresholdn)
=>
ASSERT :
(evaluated goal object args value)
)
Each method has at least one corresponding evaluator. Figure 3-7 shows how evaluators are represented. The rule is fired when a set of subgoals have been evaluated to a minimum degree of success. The expression “?value:>=threshold” specifies that “?value” must be greater or equal to the specified threshold. If a set of subgoals has been evaluated to a degree equal or higher than the threshold, then it is asserted that the goal is evaluated at a particular value which is reported to the appropriate component.
We use thresholds in two distinct ways. First, they serve as a cut-off point for the search. Once all goals have been achieved in a manner equal to or above the specified threshold, the intent is achieved. Second, they serve to select methods that have been designed explicitly to achieve a visual effect with the corresponding level of importance.
The first communicative goal specified in Figure 3-5 creates the variable mappings shown in Figure 3-8. The design method in Figure 3-9 shows the design method applied in the illustration shown in Figure 3-1 to accomplish the change goal. This method describes the six subgoals, or in this case, the six style strategies that must be achieved to depict successfully how the object is turned to reach a particular state. First, the object must be included in the picture. Second, other objects that represent some portion of the world, or provide context must be included. Third, the object must be visible in the picture. Fourth, it must appear in such a manner so that it is recognizable. Fifth, the object should be highlighted. Sixth, a meta-object, or special annotation object, should be generated to show how the object is turned. This rule is designed to model what a skilled illustrator would do if he or she were to draw a picture that shows how an object is turned. Figure 3-10 shows the corresponding evaluator for the design method. Once each subgoal has been evaluated (by the drafter) to reach or surpass the specified thresholds, the change goal is evaluated to be successful to the highest degree.
(change channel-knob turn position-1 highest)
(?goal = change)
?object = channel-knob
?action = turn
?state = position-1
(?threshold = highest)
(method-for-showing-change-with-highest-priority
;; ASSIGNED TO ILLUSTRATOR
(change ?object ?action ?state highest)
=>
ASSIGN TO DRAFTER:
(include ?object ?state highest) ;; 1
(context ?object highest) ;; 2
(visible ?object high) ;; 3
(recognizable ?object high) ;; 4
(highlight ?object high) ;; 5
(meta-object ?object ?action ?state highest) ;; 6
)
(evaluator-for-change-at-highest rating
;; EVALUATIONS FROM DRAFTER
(evaluated include ?object ?state ?val1:>=highest) ;;
1
(evaluated context ?object ?val2:>=highest) ;; 2
(evaluated visible ?object ?val3:>=high) ;; 3
(evaluated recognizable ?object ?val4:>=high) ;; 4
(evaluated highlight ?object ?val5:>=high) ;; 5
(evaluated meta-object ?object ?action ?state ?val6:>=highest)
;; 6
=>
ASSERT :
(evaluated change ?object ?action ?state highest)
)
The illustration shown in Figure 3-1 is evaluated to achieve these subgoals. The channel-knob and parts of the radio are among the objects included in the list of objects associated with the illustration. The channel-knob is visible, that is, it appears in the illustration and it is not occluded by other objects. The channel-knob is recognizable; it occupies a minimum area of the illustration and it is seen from an angle that is designed to show it in a way that makes it recognizable. (We describe how recognizability constraints are represented in Section 3.9.) The channel-knob is highlighted using special lighting, and an arrow has been generated to show how the dial is turned. Because all subgoals have been evaluated as successful, the change goal is evaluated as successful.
Figures 3-11 and 3-12 show simplified pseudo-code for how the illustrator and drafter components work. The main difference between the illustrator and the drafter is that the illustrator waits for the evaluations from the drafter, while the drafter calls illustration procedures directly. Each component is assigned goals to accomplish and is expected to evaluate its work. Each component attempts to achieve each goal in the order that it was assigned.
All the rules are ordered and reordered dynamically during the illustration process. We call the initial ordering a preferred illustrative style. This ordering specifies that certain methods are preferred over others and should be tried first. When a preferred method fails, another method is chosen, and the illustrative style is overridden. Figure 3-13 shows the partial style method ordering that was used to generate Figure 3-1. It specifies that the preferred mode for highlighting an object is to increase the lights shone on it, that the preferred way to show context is to include the object’s semantic parent, as discussed in Section 3.9, and that the preferred method for making an object visible is to select a view specification.
Illustrator
while all communicative goals are not satisfied to at least the
minimum degree
{
reorder rules (either by illustration preference or control rules)
select the next goal gi
while there are rules to apply for goal gi and gi
is unsuccessful
{
if we are backtracking then
control rules determine where to backtrack to
select rule rj
if we decide to apply the method for rj
{
apply rj -method
assign the style strategies subgoals to the drafter
}
if we decide to apply the evaluator for rj
{
apply rj -evaluator (or the evaluator associated with
that rule)
assign the style strategies evaluation requests to the drafter
}
}
if we are waiting for evaluations and they come in then
compute the value of gi based on the subgoal evaluations
}
}
Drafter
while all style strategy goals are not satisfied to at least the
minimum degree
{
reorder rules (either by illustration preference or control rules)
select the next goal gi
while there are rules to apply for goal gi and gi
is unsuccessful
{
if we are backtracking then
control rules determine where to backtrack to
select rule rj
if we decide to apply the method for rj then
{
apply rj-method (or the method associated with that rule)
call the illustration procedures
}
apply rj-evaluator (or the evaluator associated with that rule)
call the illustration procedures
compute the value of gi using the illustration procedure
return values
}
}
Unless specified otherwise, the goals are handled in the order that they are assigned. Each subsequent goal is treated as an addition to the illustration. The ordering is applied for each subsequent run of evaluations. Meta-rules determine whether or not each component applies the evaluator or method first. During the initial design of an illustration, methods are applied first and then evaluated. However, for each subsequent communicative goal handled, the evaluators are applied first. Methods are applied when these evaluations fail. This mechanism is designed to avoid unnecessary changes to the illustration. A method may therefore be evaluated as successful even if it was not explicitly applied. Thus, the methods are applied when corresponding evaluations fail.
(methods-for-highlight
with_lights ;; increase the lights shone on the object
with_muting ;; decrease the lights shone on the object
)
(methods-for-context
include_semantic_parent ;; include the object’s parent
in the semantic hierarchy
include_physical_parent ;; include the object’s parent
in the geometric hierarchy
)
(methods-for-visible
view_spec ;; select a view specification
with_cut_away ;; remove pieces of occluding objects
with_ghosting ;; ghost away pieces of occluding objects
with_transparency ;; render occluding objects with transparency
by_removal ;; remove occluding objects
)
.
.
.
The illustrator that was assigned the goals for the illustration shown in Figure 3-1, first applied the design method in Figure 3-9 to satisfy the change goal. Figure 3-14 shows the variable mappings based on both the input communicative intent and information in the knowledge-base. The illustrator begins to process the location goal and selects the design method shown in Figure 3-15 which is designed to show location to a moderate degree. This method specifies that the object should be included, visible, and highlighted and that the context-object should be included and moderately recognizable. The radio is the parent object of the channel-knob, as specified in the object-representation. The illustrator assigns the style strategies to the drafter. The drafter first applies evaluators rather than modifying the illustration. In this case, the first four style strategies have already been evaluated as successful. However, the fifth style strategy, to show the radio in such a way that it is recognizable to a medium degree is a new goal. The view specification is not yet fully specified (a representation for the view is incrementally constrained to accommodate goals, but the final view is not selected until rendering). The drafter applies a method to ensure that radio is recognizable to a medium degree. Consequently, the view is modified so that some of the radio’s unique parts appear in the illustration. This modification to the view specification does not affect the success rating for the other goals. The illustration is now completely specified (shown in Figure 3-1) and is evaluated as successful.
Unless specified otherwise, the search is depth-first. Previously attained goals, if violated, disqualify the currently tried methods. Meta-rules embody specialized knowledge for combining methods. For example, the channel-knob in the illustration shown in Figure 3-1 is highlighted by a combination of two methods. The next section describes this mechanism in detail.
(location channel-knob medium)
(physical_object parent channel-knob radio)
(goal = location)
?object = channel-knob
(threshold = medium)
?parent = radio
(method-for-showing-location-with-medium-priority
;; ASSIGNED TO ILLUSTRATOR
(location ?object medium)
;; FROM THE OBJECT REPRESENTATION
(physical_object parent ?object ?parent)
=>
;; ASSIGN TO DRAFTER
(include ?object highest) ;; 1
(include ?context-object highest) ;; 2
(visible ?object high) ;; 3
(highlight ?object high) ;; 4
(recognizable ?parent medium) ;; 5
)
Unless specified otherwise, the low-level components have priority over the high-level components. For example, the illustrator waits until the drafter returns evaluations for the style strategy goals the illustrator assigned.
Meta-rules apply specialized knowledge in the different situations described in Chapters 5 and 6 to prune the search by disqualifying methods and by reordering the rules, and prioritize speed over accuracy during interactive sessions. For example, meta-rules are designed to enforce the consistent use of visual cues. Once one method has been selected, the methods are reordered to favor that method over others.
One of the style strategies applied in Figure 3-1, specified by the design method in Figure 3-9 is to highlight the object. An object is highlighted by using a visual cue to draw the user’s attention to that object. One way to highlight an object is to make it appear different from the other objects. The method used to highlight an object is meant to be obvious so that the user understands that an illustrative technique is being applied to emphasize that object. For example, if an object is highlighted by coloring it another color, the user should not be confused and believe that object is now colored differently, but instead understand that color is being used as a visual cue.
Figures 3-16 and 3-17 show the methods applied when Figure 3-1 was designed. Figure 3-16 shows the style method for highlighting by increasing the lighting on the highlighted object. Figure 3-17 shows the style method for highlighting by decreasing the lighting on all other objects.
(method-for-highlighting-with-lights-high
(highlight ?object high)
=>
. . .
(HighlightByLights ?object ?intensity)
. . .
)
(method-for-highlighting-with-muting-high
(highlight ?object ?high)
=>
. . .
(MuteLightingOnAllOtherObjects ?object ?dimmer-value)
. . .
)
The evaluator for the first method is shown in Figure 3-18. It specifies that in order to successfully highlight an object by increasing the lights shining on it, the object must be assigned special lighting, it must appear different with the lighting than it would without the lighting, and most importantly, the contrast between the highlighted object and the other objects must be high. The evaluator for the second method, shown in Figure 3-19, specifies that all other objects must have altered lighting, that they appear different, and again that the contrast between the object and all other objects be high.
(evaluator-for-highlighting-by-increasing-lighting
(activated evaluation highlight ?object with-lights)
=>
(if (and (ChangedLighting ?object)
(ChangedAppearanceByLights ?object))
then
(evaluated highlight ?object
(ContrastWithOtherObjects ?object)
with-lights)
else
(evaluated highlight ?object lowest with-lights)
)
)
(evaluator-for-highlighting-by-decreasing-lighting
(activated evaluation highlight ?object with-muting)
=>
(if (and (ChangedLightingAllBut ?object)
(ChangedAppearanceByLightsAllBut ?object))
then
(evaluated highlight ?object
(ContrastWithOtherObjects ?object)
with-muting)
else
(evaluated highlight ?object lowest with-muting)
)
)
For the purposes of this demonstration we have removed the highlight goal from the design method listed in Figure 3-9 to generate the illustration shown in Figure 3-20. The drafter is now assigned the goal to highlight the channel-knob. The methods are ordered as shown in Figure 3-13. A meta-rule specifies that these two methods can be combined:
(combine-method highlight with-lights with-muting)

Figure 3-20. Channel knob with no highlighting.
The method with-lights is tried first. The channel-knob is assigned additional lights. The procedures ChangedAppearanceByLights and ContrastWithOtherObjects both return failure. The state of the illustration is shown in Figure 3-21. The procedure ChangedAppearanceByLights returns failure because the illustration evaluators detect that the dial’s markings are brightest white, so increasing their lighting does not change their appearance. The procedure ContrastWithOtherObjects returns low because the other objects also have markings that are white and therefore do not contrast sufficiently with the channel-knob’s markings. Therefore, the method fails so the system backtracks and returns the illustration to the state shown in Figure 3-20.

Figure 3-21. Highlight Method: Brighten object.
The system next tries the method with-muting. The lights shining on all objects except the channel-knob are dimmed. Figure 3-22 shows the state of the illustration. The procedure ContrastWithOtherObjects determines that the contrast between the channel-knob and other objects is low. The system backtracks and returns the illustration to the state shown in Figure 3-20.
The combine-method rule is activated and methods with-lights and with-muting are applied together. All evaluations succeed. The drafter reports back to the illustrator that the channel-knob is successfully highlighted. The resulting illustration is shown in Figure 3-1.

Figure 3-22. Highlight Method: Mute other objects.
Figure 3-23 shows the structure of an illustration. The illustration contains all the information necessary for the computer graphic to be rendered. When the illustration is rendered, the user sees the results of the values for the view specification, lighting models, the set of objects, and rendering instructions. The illustration contains procedures that directly change these values as well as examine various properties of the illustration. The illustration is the only portion of the system that contains machine-dependent code, in particular graphics-package specific.
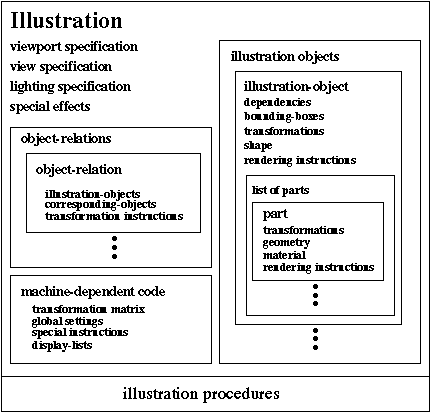
Figure 3-23. Illustration structure.
The illustration contains procedures to compare various aspects of objects as they will appear when rendered. For example, there are procedures to determine what objects block another object, to compute the bounding box of an object, and to determine the number of pixels occupied by a particular object. These procedures are used to examine the various aspects of the computer graphic picture and evaluate how well visual effects are achieved. The illustration also contains procedures that alter various aspects of the objects. For example, there are procedures to generate cutaway views, to place labels, and to assign different lighting to a particular object.
The illustration maintains a dynamic relationship between the objects that appear in the illustration and the objects in the real world or knowledge-base. A semantic meaning is associated with all the objects that appear in the illustration. We define three classes of objects: illustration-objects, physical-objects, and meta-objects. All the objects that appear in an illustration are illustration-objects, each of which is created for a specific illustration. Physical-objects are the objects found in the knowledge-base of the world being depicted. Meta-objects are annotation objects such as labels and arrows that do not exist in the real world but appear in illustrations [Feiner 85].
Illustration-objects typically correspond to physical-objects, but include additional information about the style in which they will be rendered. As shown in Figure 3-24, object-relations represent the relationships between illustration-objects and physical or meta-objects. In many cases, an illustration-object represents a single physical-object, but there need not be a one-to-one correspondence between illustration-objects and physical-objects. A single illustrator-object may represent many physical-objects. For example, a pile of laundry, comprising of many individual objects, may be represented by a single illustration-object. More than one illustration-object may represent the same object. For instance, each illustration-object may depict the same object in different states. Objects are included only if a goal requires it. Many of the physical-objects in the knowledge-base may have no corresponding illustration-object. Finally, an illustration-object, such as a label, may correspond to no object in the knowledge-base.
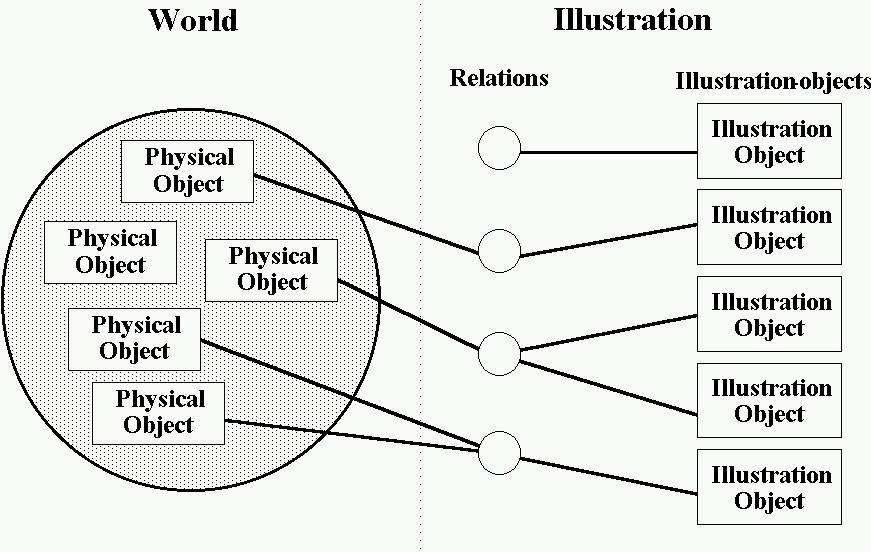 Figure 3-24. Physical-objects and illustration-objects.
Figure 3-24. Physical-objects and illustration-objects.
Figure 3-25 shows the illustration-objects and their corresponding physical-objects for the illustration shown in Figure 3-1. There are only three illustration-objects. The first illustration-object represents the channel-knob. It was generated to satisfy the include channel-knob goal. The channel-knob is depicted with the labels that mark its settings. To partially satisfy the highlight goal for the channel-knob, this illustration-object is assigned special lighting which causes it to appear brighter. The second illustration-object corresponds to the radio itself and was generated to satisfy the context goal. The channel knob and its labels are not included in the radio object. To partially satisfy the highlight goal for the channel-knob, this illustration-object has been assigned dimmed global lighting, which causes it to appear darker. The third illustration-object is the arrow that shows how the dial is turned. It was generated to satisfy the meta-object goal, and appears in a particular style and color to conform to a style preference for meta-objects that show turning.
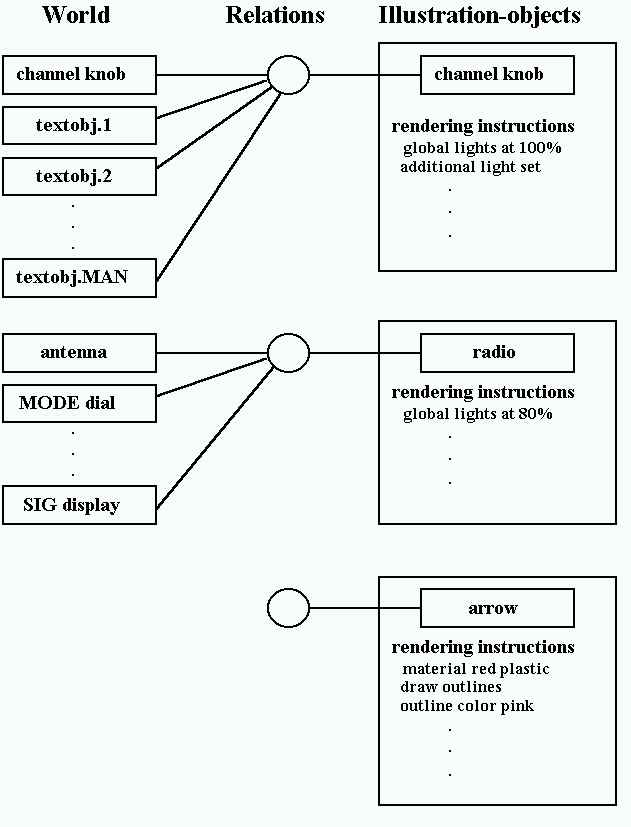
Figure 3-25.Illustration-objects for Figure 3-1.3.9.
Knowledge-Base: Object Representation
In this section we describe both the information that is required for each object as well as the specialized knowledge that is used to enhance the capabilities of the system. Figure 3-26 shows how each physical object is represented. At the very least, our system requires that the object be assigned a name, a position in the world, a shape, and at least one factor to consider in order to view the object in a manner so that it is legible and thereby recognizable. Figure 3-27 shows part of the object representation used in the radio domain for COMET. The immediate and extended family describe the objects that, if omitted, might falsely imply the object is incomplete. The labels marking the settings of the channel-knob are associated with the channel knob. They are part of the front face but are semantically part of the radio. The visibility knowledge identifies objects that should not be considered to block other objects. Thus, the channel knob, though it obscures parts of the front face, is not listed as an occluding object when the front face’s visibility is computed.
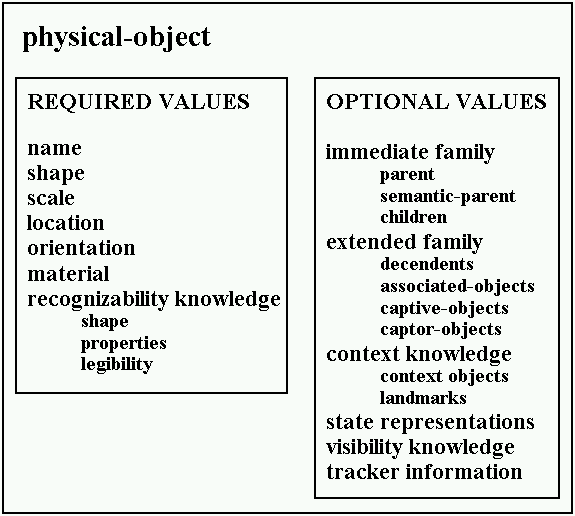
Figure 3-26. Physical-object representation.

Figure 3-27.Part of the object representation for the radio.
For the purposes of efficiency we opted to create shape libraries to describe the geometry of each object. This separates the cumbersome geometric information necessary for rendering each object from the object representation. Additionally, it provides the flexibility to use different geometric representations for the same object. We will show in Chapter 7 how two geometric representations are used together.
The taxonomy of shapes controls inheritance of specialized methods for object classes. For example, all objects of the shape “die,” inherit the methods and specialized knowledge for dice. Figure 3-28 shows some of the shapes used in the radio domain. For example, there are three types of dials, simple-dial, channel-dial, and grip-dial. The channel-knob is an instance of type channel-dial.
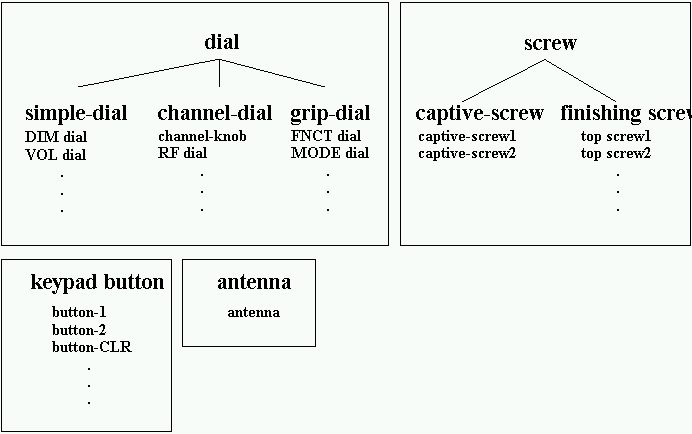
Figure 3-28. Some shapes in the radio domain.
The scale of an object is also represented. This allows generic shapes to be shared among different objects. For example, the channel-knob and RF dial are different scaled versions of the same shape. The channel-knob is stored with the following shape and scale information:
(physical_object scale c-channel-knob 1.1 1.1 1.1)
(physical_object shape c-channel-knob channel_dial)
Each object is stored with a location and orientation vector that represents the object in a base state. For example, each dial is stored in its lowest setting. The location and orientation information is relative to the object’s parent or captor object (or the object that contains or to which the object is attached). For example, the box is the captor of the objects in it. When the box is moved, so do the objects in it.
(physical_object location c-channel-knob -5.8 2.95 -9.0)
(physical_object orientation c-channel-knob 0.0 0.0 180.0)
Each object is assigned a material surface definition, but the shape representation may override global material settings for special subparts. Screws are made of one material while the grip dials are made of a base material, plastic, and rubber. The material for the channel-knob is set:
(physical_object material c-channel-knob army_light_green_paint)
One of the style strategies we have discussed is to make an object recognizable. In order to ensure that an object is recognizable, or that the user will be able to recognize it, certain constraints are placed on how that object is depicted. The notion of recognizability of an object is not simply visual or geometric, but extends to the semantics of the object. For example, for a die to be recognizable it can simply be depicted in such a way that the viewer discerns that it is indeed a six-faced object with spots in a particular configuration. In this case it is not important that the die is ivory or white, that the spots are concave or filled; although this knowledge is included in the geometric model of the die.
In order to recognize an object, the user must be able to “read” it. The legibility value constrains the appearance of the object in the illustration by specifying the minimum area it must occupy in the illustration. For example, a dial that occupies only one pixel is barely visible. The question is how many pixels are necessary to render it legible. The world coordinate system is used as the basis for the constraint. The channel-knob is constrained to occupy a minimum of 50 pixels per centimeter. This value is based on the characteristics of our high-resolution display and a default value representing the user’s distance from the screen. Determining the legibility of an object is accomplished by computing the projected bounding boxes of the object. Text has the additional requirement that it be viewed head-on to be legible.
Each object is represented with information that describes the angle from which the object should be viewed. For example, a cube should be depicted with three faces showing so that its shape is recognizable. A red cube with one white face should be depicted so that the one white face is shown with two other red ones. A button that has text on it should be shown so that the text is shown. Each object is stored with at least one ray that specifies how it should be viewed. This ray is represented by a lookat point and direction. Figure 3-29 illustrates the preferred angle of view for the channel-knob, represented by:
(physical_object reference c-channel-knob origin 0 0 -1.0)
Some work has been done to automatically generate characteristic views [Chakravarty 82, Kamada and Kawai 88] of geometric models. A characteristic view of an object is a view of an object in which the distinguishing features of an object are projected so that the viewer can parse its shape. Characteristic views are designed to accurately show proportion and form. We do not address this very difficult problem, but instead store the hand-entered values representing preferred views. Ideally, procedures for deriving characteristic views dynamically would be used to generate these values automatically.
Returning to the example of the red cube with the one white face, ensuring that the white face is depicted with two red faces is useless unless the color of the faces is shown as well. The color property of each face is specified as a recognizability constraint. Objects have other properties and characteristics that may be important to show to make them recognizable. If two, otherwise identical objects, such as an old and new battery need to be recognizable, somehow that one is “old” and the other is “new” needs to depicted. Several objects may seem alike unless labeled, and an object’s function or use may not be apparent from its shape.
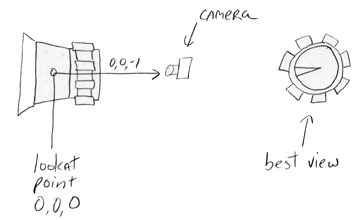
Figure 3-29.One recognizability constraint for the channel knob.
The traditional hierarchical arrangement for objects in graphics systems is a parts hierarchy. The hierarchy indicates how transformations for rendering the objects in their relative positions are handled. For example, if the printer moves, then so should all of its children (unless specified otherwise). If the radio is turned to its top side, then all its children turn with it.
Objects may have children, or objects that are considered to be parts of them. For instance, our model of the printer has five children: the printer-lid, the printer-base, printer-lever, paper-tray, and the toner cartridge.
Thus, we represent two different types of parenthood. One is the geometric parenthood, when objects inherit transformations from their geometric parents. The second is semantic parenthood and represents how objects are grouped together. Every object may have a parent object which corresponds to the parent of the object in the geometric parts hierarchy.. For example, the parent of the printer-lid and printer-base is the printer. However, the paper-tray is a free agent and its parent is the world. Its semantic parent is the printer. Although it does not necessarily inherit its position and orientation information from the printer, it is still considered to be a child of the printer. This way, when the printer is included, the paper-tray will be included as well. However, the parent of the buttons on the keypad is the keypad which consists of a plate of metal within which they are lodged, but the semantic parent of the buttons is the radio.
There are three types of objects that are associated with a particular object: descendants, associated objects and captive and captor objects. These are objects that should be included in the representation of the object.
An object is included by generating an illustration-object to depict that object. The illustration-object is generated to represent all sub-objects and other objects to complete the representation of the object. An object’s set of descendants in the object hierarchy is calculated unless it is specified that another set of objects should be used to replace this set.
There are two other kinds of objects that are not direct descendants of the object but should be included when the object is included. Associated objects are objects that were they not included with the object would make the object seem incomplete. For example the labels of a dial are associated objects. Captive objects are physically tied to captor objects but are not part of that object. For example, the captive screws in the holding battery cover are captives to the cover and the cover is captor of each captive screw.
Figure 3-25 shows that the illustration-object for the channel-knob represents not only the knob itself, but the associated set of labels on the radio’s front panel that describe the channel-knob’s settings. When the style strategy goal for including the channel-knob is activated, an illustration-object is generated for the channel-knob to include all the members of the extended family.
Context knowledge specifies the appropriate ancestor or set of ancestor objects to use to show context. Without context knowledge the object’s parent is the default ancestor object. For example, the default context object for a button on the radio’s keypad is its semantic parent, the radio. The context knowledge is used to populate the object list. Although the system may decide that it is only necessary to show the key in context of the keypad, the resultant illustration view specification may otherwise show parts of the radio. To omit these parts from the object list could cause the illustration to depict the keypad alone, as though it were floating in air, introducing the false implication that it was not attached to the radio.
Context knowledge can be computed, and need not be provided with the object. Procedures for identifying landmark objects (or objects that serve to help locate other objects) are used to evaluate how well context is shown. One such procedure determines whether or not the boundary (or edge) of an object appears in the illustration. This is accomplished by computing and analyzing the projected bounding box of the object. Unfortunately, this procedure is incorrect because the bounding box is not accurate since it is rectangular and the object may occupy a non-rectangular area in the illustration.
Another procedure identifies unique objects. This procedure determines uniqueness using the shape description stored with each object. The antenna and keypad on the radio are considered landmark objects for the radio. The buttons on the keypad are also landmark objects because, although they share the same shape, they differ in the text displayed.
The state of an object is represented by a name and a set of properties, and is referred to by rules. For example, a dial is set to channel 3, a switch is on, the lid is open, and the LED display contains a particular message. In each case, the object’s attributes have a particular value. The dial is rotated some number of degrees, the switch is lit, the lid is in a particular position, and the individual LED display segments are either on or off. The state representations consist of the values to be substituted. For example, the state of the channel-knob in position 1 is represented:
(instance shape orientation c-channel-knob c-position-1 all 0 0 197.0)
This indicates that the shape (and all subparts) of the c-channel-knob is rotated 0° in x, 0° in y and 197° in z, when the channel-knob is set to position 1.
State representation is also useful during a simulation. We represent the state of the dice “at rest” when they are no longer are moving. It is only at this point that the goal for showing the value of the roll of the dice can be activated, otherwise the roll cannot be illustrated.
We will also show in Chapter 7 how state knowledge is used to determine when goals are satisfied by active intervention of the user (or the objects themselves).
Applying blanket rules for determining and maintaining an object’s visibility poses several problems. Let us consider the case of an instruction concerning the loosening of a screw. All designs for showing the screw will activate a goal for the screw’s visibility. Without specialized rules, the objects that the screw pierces will be classified as occluding objects and a method for making the entire screw visible will be applied.
For example, a cutaway view could be generated to reveal the screw’s shaft. In some cases, this may be desirable, but generally it is not. It is then required that specialized rules for different types of objects need to be introduced to handle such cases. These rules cannot be derived automatically, they are too closely tied to convention.
Our object representation lists objects that are not considered as occluders. For example, as shown in Figure 3-25, the channel-knob is not considered an occluder of the radio-face, although it does obscure parts of the radio-face. Figure 3-30 shows part of the radio representation. The holding battery cover plate and two captive screws are children of the radio. The cover plate is a captor of both screws (so if the cover plate changes position, the screws move with it). The cover plate is also considered a non-occluder of each captive screw as are each screw considered a non-occluder for the cover plate.
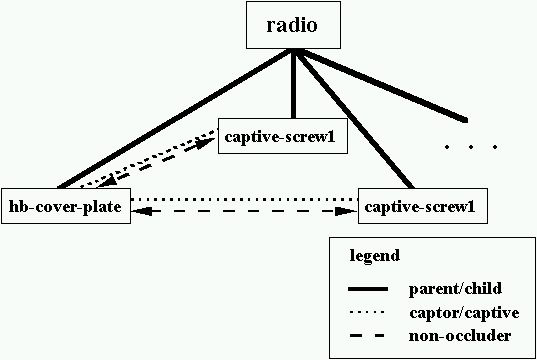
Figure 3-30. Part of the object representation for the radio.
To represent visibility knowledge more rigorously, a set of subparts that must be visible should be stored with each object. This would require that a separate object for each of these object’s subparts be created. Even a screw consists of many subparts, so generating a separate object representation for each is costly. To reduce overhead, segmentation could be put off until a visibility goal is associated with a particular object.
Using a generate-and-test approach we can automatically generate
illustrations based on a communicative intent. By using methods
to apply stylistic choice and evaluators
to test for the effectiveness of a stylistic choice, our system can backtrack to adopt new plans when goals conflict. Our system applies a visual language we have devised that is based on the separation of design and style. The illustration task is thus decomposed, and each level of goals is handled by a different component. Our system uses standard geometric information to define objects, but represents objects with additional information to enable intent-based illustration. We have described the main features of our architecture and shown how they help generate the illustration shown in Figure 3-1. The relationship between the various components is dynamic. In following chapters we will show how this dynamic relation is exploited to extend the capabilities of the system.