A convenient way to mark up SCU contributors in text is to use the Wordfreak tool.
If you are on one of the CS linux system, one of the coral machines
for example, you can launch WordFreak with this command:
/usr/local/java/j2sdk1.4.2_01/jre/javaws/javaws /proj/nlp/users/devans/arabic/DUC2004_data/pyramid/wordfreak.jnlp
Once in the text tab, you should see two windows, like this:
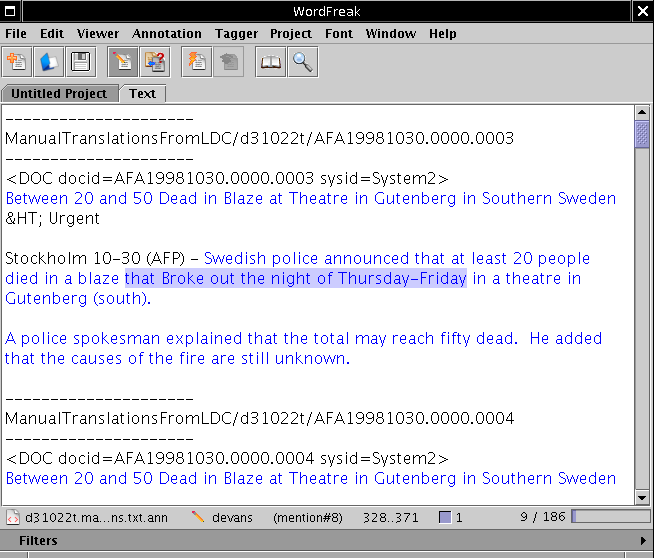
Read the plain text summaries to familiarize yourself with the
topic. Then chose a content unit that is shared by several summaries. To
create a new SCU, highlight a contributor with the mouse in the text
field, then select "Mention" under the Type selection
on the annotation bar. The contributor will
be copied under "Mention". You can add the SCU Label in the Comment
field in the annotation window. To add contributors from other
summaries, select the text, and select the "+" button next to the SCU
you want to add the contributor to.
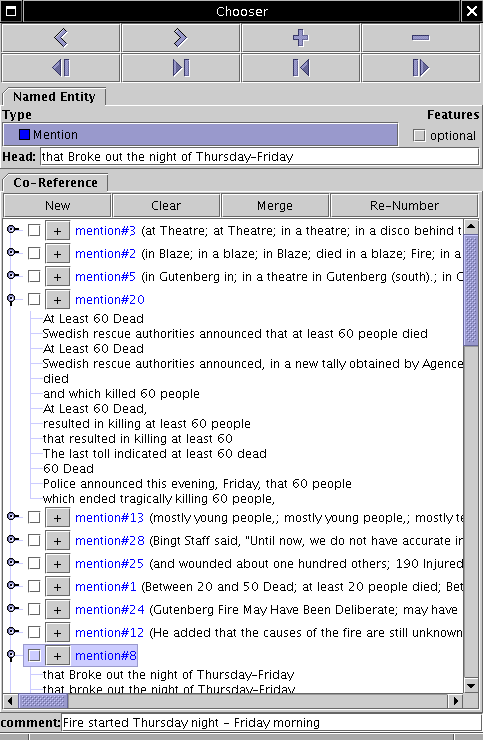
You can also use the large "+" button on the upper right of the
Chooser window to create a new SCU.
Parts of the text that belong to an already assigned contributor will
become blue in the text field. You can work your way through the texts
in any way you like, you will be done when all of the initially black
text in the text window becomes blue.
When you click on text that has been assigned to a SCU, the SCU will
be selected and made visible in the Chooser window. Please
make sure that the text knows which SCU it belongs to. In some rare
cases, when a blue portion of the text is clicked, no SCU will be
highlighted, and down in the status area it will only say (mention)
and not (mention#8)! If that happens, please click the
contributor, and use the large "-" button in the Chooser to remove
this un-attached annotation, and re-add the sentence to the proper
SCU. Either create a new one, or add it using the "+" button next to
the existing SCU that the contributor should be part of.
If you need to merge two SCUs, click on the boxes next to the SCUs you want to merge, then select "Merge" from the top annotation panel.
There is no way to split a single SCU into two SCUs. You will have to remove the annotation from each contributor, and create two new ones.
As you become more familiar with the process of annotation you might come up with your own strategy of traversing the summaries and identifying SCUs. If you wonder how to begin, two useful approaches might be a) Start reading the first sentence of the first summary, then identify if the information is included in any other summary and start marking up the SCUs. b) Decide for yourself what is the main topic of the summaries and find how it is expressed in each specific summary and form your first SCU. Afterwards, look for more details about the main topic, leading to the formation of additional SCUs. No matter how you start, the final goal is to cover all the text of all summaries in the annotation file.
Note: occasionally, two non-adjacent snippets of the sentence are contributors to a single SCU. Currently, the annotation tool does not support the mark up of non-adjacent contributor parts, so chose one of the parts only. You can enter a comment that indicates that missing part that should be included. It is ok to leave the non-adjacent text un-marked in this case.
To get a sense of what a complete annotation looks like, load the
/proj/nlp/users/devans/arabic/DUC2004_data/pyramid/d31022t/d31022t.manual_translations.txt
file with the annotation of the manual translations of Arabic
documents about a fire in Sweden and look at the annotation choices
there. By clicking on the mention annotation you will see the
contributors highlithed in the text window. (Do not open the file with
text editors other than wordfreak, because the introduction of new
characters will interfere with the mark-up visualization!)
Find does not seem to work well if you have text selected, so don't select text first.