Table of Contents
- 1. Administrivia
- 2. Introduction
- 3. Storyline: Designing Sommelier, a Microprocessor for Fluid Viscosity Analysis
- 4. Tools for the Project
- 5. Design Flow
- 6. Available Components and System Configuration
- 7. Software Optimization
- 8. How to Run the Tools
- 9. Additional Hints
- 10. Submitting the Report
- 11. Grading
- References
|
|
|
|
This project is worth 220 points, and is due on Friday, 12/14/2012 at 11:59pm EST. |
|
|
|
|
You are strongly encouraged to work in pairs, although you are not forced
to. Submissions will be organized in teams of either one or two members.
All teams need to apply for a unique team id via email. To do so,
please send one email per team (with all team members in Cc, if applicable)
with your names and UNIs to |
|
|
|
|
This project was prepared by Emilio G. Cota. His office hours take place in the TA Room every Thursday between 4.30 and 6.30pm. |
In this project you will work with SESC, an instruction set architecture simulator that can be used also to model multi-core architectures. You will also use the web version of CACTI to model various cache-memory organizations. CACTI is an integrated cache and memory access time, cycle time, area, leakage, and dynamic power model (for details see [cacti_hp].)
Motivated by recent geological analyses performed by the Curiosity rover on Mars, scientists at NASA are working on a new rover capable of drilling through Mars' mantle, in the hope that primitive forms of life may be confined there.
Mars' mantle is expected to be at very high temperature and pressure. Diverse models have been devised by NASA geophysicists, but they still cannot agree on what the viscosity of the mantle could be, and therefore whether any forms of life could develop in it.
To tackle this problem, you have been approached by NASA engineers working on the prospecting unit to be deployed by the rover. Given the extreme conditions under which the device will operate, no communication with the surface (and thus with Earth) will be possible. The only option left is to equip the unit with all the hardware necessary to elaborate a model of the mantle’s viscosity. You have been asked to design an embedded microprocessor, called Sommelier, to perform the necessary fluid mechanics computations. The NASA team have given you a set of kernels representative of the kind of operations they need to solve efficiently; they are essentially systems of differential equations (overdetermined due to environmental noise), that once preprocessed are treated as operations on dense matrices.
The most representative kernels that Sommelier needs to run efficiently are: matrix-matrix multiplication, matrix-vector multiplication, matrix scaling by a constant factor, and matrix addition. The major design requirements you have been given are:
- Power budget of 30W due to packaging constraints.
- 32nm technology process.
You are given three benchmarks of different size, summarized in Table 1, “List of provided tests.”. On each iteration, the four matrix operations mentioned above are executed in sequence, since the solver the benchmarks are modeling is a recursive one. Note that the frequency of each type of matrix operation is the same on all tests; what varies across benchmarks is the size of the matrices and the number of iterations. Your goal is to minimize the running time of the large test case. To accomplish this you should attack the problem on two fronts: 1) software optimization, exploring parallelism (ILP and thread-level) with emphasis on achieving cache efficiency, and 2) design space exploration based on the SESC simulator for architectures that execute the software optimally.
Table 1. List of provided tests.
| Test Name | Main loop iterations | Array size |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Apart from the large benchmark, you have also been given two smaller (small and medium); you must make sure the CPU is within the power budget when running them; however, you can safely ignore their running time, since such short inputs are not common among those that Sommelier will commonly run.
We have prepared a Virtual Machine (VM) that includes test files, this documentation, boilerplate code for Sommelier, a skeleton for the project report, and the SESC simulator [sesc]. Step by step, this is what you should do to get started:
- Download and install VMWare Player, or any equivalent product that can run a VM image. You can download VMWare Player free of charge from the following link: http://www.vmware.com/products/player/
- Download the archived virtual-machine image for the project from: http://www.cs.columbia.edu/~cs4824/project/projectVM.tar.bz2
-
Extract the archive:
$ tar xvf projectVM.tar.bz2
- Launch VMWare Player and select “Open a VM”, then find the CSEE4824Ubuntu.vmx file, and click on “Open”.
-
Log in as user with password csee4824. At this point it would be wise
to change the password with the
passwdcommand. -
The project folder is located under
~/project. -
The SESC executable (
sesc.smp) is located in the~/project/workspacesubdirectory.
You can use the web version of CACTI--See [cacti_hp] for information on this tool.
To optimize both hardware and software in order to get the best performance, you should follow this procedure:
- Choose a combination of processing cores, memory hierarchy, and clock frequency.
-
Modify and compile the
sommelierprogram in order to get the best performance for the combination you chose. - Run CACTI to find an access time of all caches. Convert the access times from ns to clock cycles and put them into the configuration file.
- Prepare the configuration file for SESC with all the data for cores.
- Run wattchify and cactify to preprocess the chosen configuration.
- Run SESC simulations for all the benchmarks and input data set combinations.
- Analyze the results of each simulation by using the report.pl script.
The following Sections provide detailed information for each of these steps.
You can design your optimized microprocessor architecture by mixing and matching the components (processing cores and memory elements) that you can choose among those described in this section. As long as you stay within the 30W power budget and follow the specific rules explained in these pages, you are free to design any type of microprocessors including heterogeneous or homogeneous multi-core architectures.
You can design your architecture by choosing among various possible processing cores. As detailed in the following table there are three main core types: LargeCore, MidCore, and SmallCore. The differences among core types depend on the issue width, which must be specified in the SESC configuration file as described in the following tables.
Table 2. Configuration parameters for each core type.
| Core Type | Issue Width | In-order |
|---|---|---|
|
LargeCore |
issueLarge |
inorder |
|
MidCore |
issueMid |
inorder |
|
SmallCore |
issueSmall |
inorder |
Table 3. Differences among core types
| Core Type | # of Execution Units | ReOrder Buffer (ROB) Size |
|---|---|---|
|
LargeCore |
issueLarge |
$32 + 36 \times\text{issueLarge}$ |
|
MidCore |
$1 + \lceil \text{issueMid} / 2 \rceil$ |
$32 + 18 \times \text{issueMid}$ |
|
SmallCore |
1 |
$32 + 9 \times \text{issueSmall}$ |
For each core type, you can only choose one design (i.e. one set of configuration parameters). For example, it is not allowed to have a 6-way LargeCore and a 4-way LargeCore in the same microprocessor architecture. However, you can combine cores belonging to different core types to build a heterogeneous multi-core architecture. For example, it is possible to have a 4-way LargeCore together with a 4-way MidCore.
In the SESC configuration file, set the procsPerNode parameter to the
number of cores you want. Note that total number of cores in the system
i.e. procsPerNode) should be smaller than 64. For each cpucore[i]
in the configuration file with $0 \lt i \le$ procsPerNode,
use array notation to specify a core type in the corresponding table (e.g.
cpucore[0] = LargeCore.) Note that you can also use a range operator
“:” in the bracket (e.g. cpucore[1:3] = SmallCore). If you decide to use
an in-order core, modify the inorder parameter in the corresponding core
Section to true. In order to choose the issue width of each core type,
modify the parameter described in the ‘Issue Width’ column above.
To organize your memory hierarchy you can choose among three types of L2
cache organizations: no L2, Shared L2, and Private L2. For the two main
core configurations, we prepared 5 different configuration files that are
found in the ~/project/confs directory (see Section 4, “Tools for the Project”). You
have to use the configuration file that corresponds to the memory hierarchy
organization that you choose according to the naming conventions described
in Table 4, “Configuration File for each cache organization”.
Table 4. Configuration File for each cache organization
| Core Configuration | L2 Type | Configuration File |
|---|---|---|
|
Single-Core |
No L2 |
|
|
Single-Core |
L2 |
|
|
Multi-Core |
No L2 |
|
|
Multi-Core |
Shared L2 |
|
|
Multi-Core |
Private L2 |
|
Table 5, “All possible memory hierarchy organizations and their corresponding configuration file names.” illustrates all possible memory hierarchy organizations and their corresponding configuration file names. Note that there are two separate buses between L1 and its lower level i.e. instruction bus and data bus) when you combine L1 caches with lower level of hierarchy. You must use CACTI to estimate the area of the on-chip portion of your memory organization.
Table 5. All possible memory hierarchy organizations and their corresponding configuration file names.
| Single-Core | Multi-Core | |
|---|---|---|
|
no L2 |
|
|
|
Shared L2 |
|
|
|
Private L2 |
|
|

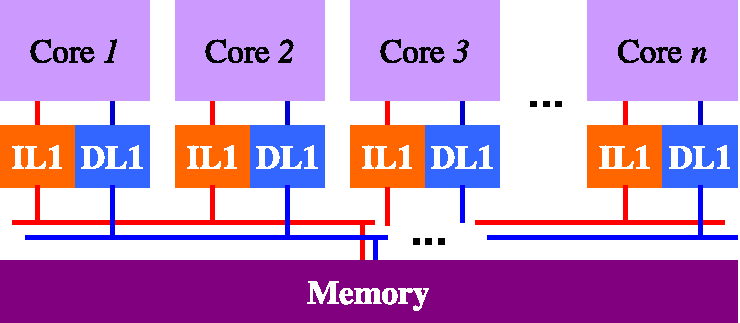
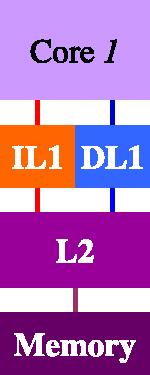
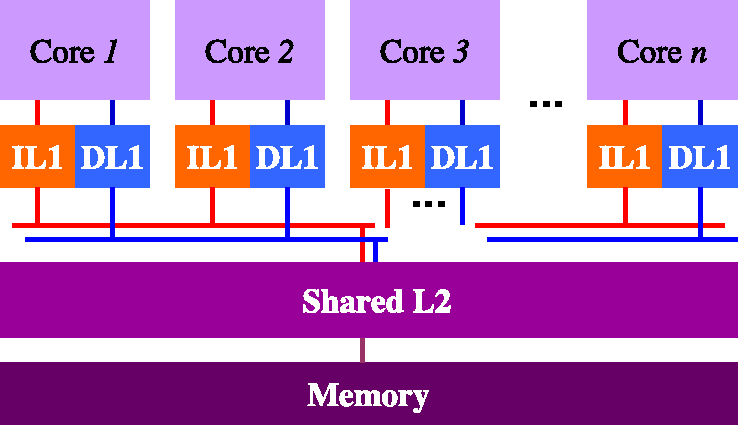
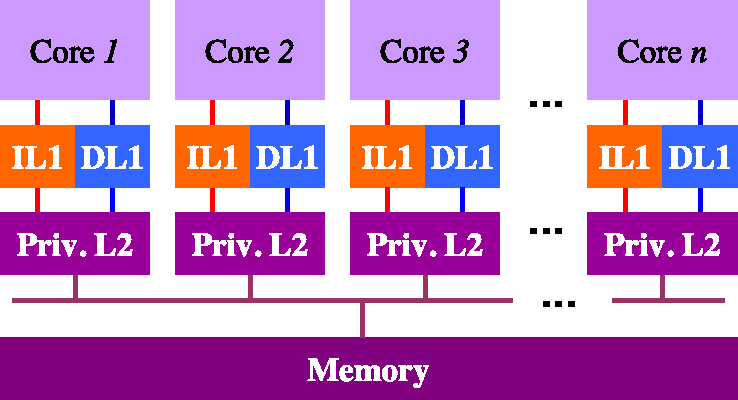
As long as you respect the following basic rules, you are free to choose the values for the various parameters of each cache in the memory hierarchy (cache size, block size, and associativity). Note that if you decide to use a Level-2 cache you can also have multiple banks). The basic rules are:
- Cache size, block size, associativity, and number of banks for each cache should be a power of 2 (e.g. 1, 2, 4, …).
- The minimum block size is 8, i.e. 8 bytes.
- The minimum cache size is 16KB, i.e. 16384 bytes.
- The minimum number of index in a cache is 32.
- The maximum associativity of a cache is 16.
- L1 cache block size should be equal to the L2 cache block size, e.g. if the L1 block size is 32 bytes, the L2 block size should be 32 bytes.
After designing your caches, you need to know which parameter needs to
be modified to apply your design. Except for the cache block size, the
parameter you want to modify in the chosen configuration file can be found
by combining a prefix and a suffix from Table 6, “Prefix of L1 parameters in configuration files”, Table 7, “Prefix of L2 parameters in configuration files”
and Table 8, “Suffix of parameters and the parameter for cache blocks in configuration files”. For the cache block size, there is a parameter
called CacheBlockSize, which is described in Table 8, “Suffix of parameters and the parameter for cache blocks in configuration files”.
Table 6. Prefix of L1 parameters in configuration files
| Core Type | IL1 Prefix | DL1 Prefix |
|---|---|---|
|
LargeCore |
|
|
|
MidCore |
|
|
|
SmallCore |
|
|
Table 7. Prefix of L2 parameters in configuration files
| Core Type | L2 Prefix |
|---|---|
|
Any, No L2 |
- |
|
Any, Shared L2 |
|
|
LargeCore, Private L2 |
|
|
MidCore, Private L2 |
|
|
SmallCore, Private L2 |
|
Suffixes in Table 8, “Suffix of parameters and the parameter for cache blocks in configuration files” specify the cache size, block size, and
associativity. For the L2 cache in SharedL2Multi.conf and L2Single.conf,
note that you also need to configure the number of banks. The multi-banked
caches are the banked storage i.e. SRAM) with shared cache controller. While
the multi-banked caches may reduce the access time or power dissipation per
access, they may also introduce more misses. The multi-banked cache and
its address division scheme are illustrated in Figure 1, “An example of banked L2 cache organization. 64-index per bank, 2-way assoc, 16-bank L2”.
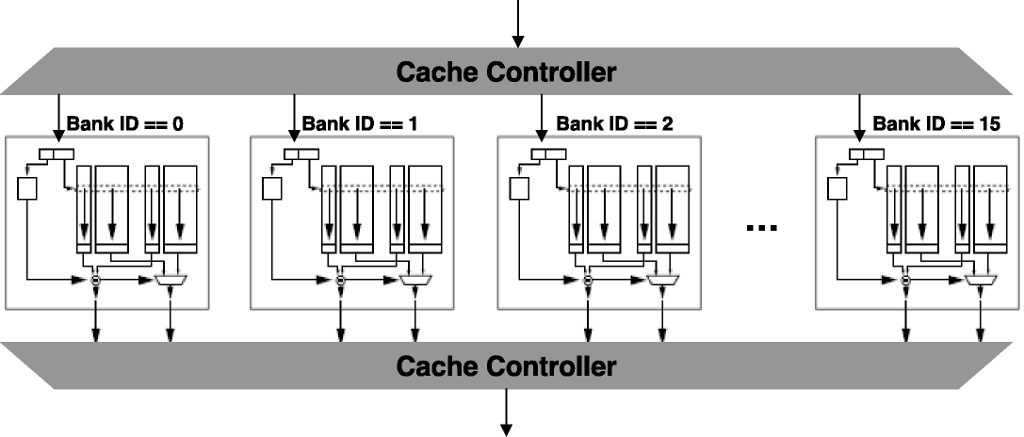
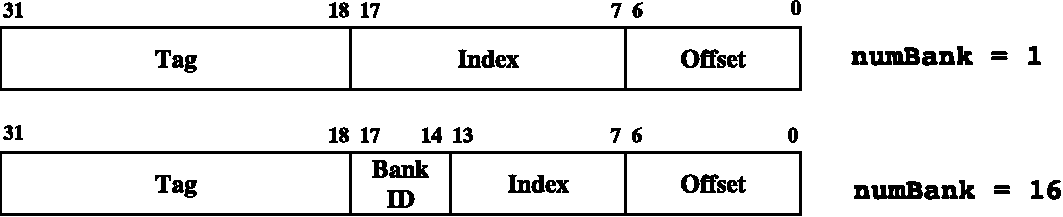
Table 8. Suffix of parameters and the parameter for cache blocks in configuration files
| Cache Level | Cache Size | Associative | Access Time per c.c. | # Banks | Block Param |
|---|---|---|---|---|---|
|
IL1 & DL1 |
|
|
|
- |
|
|
L2 |
|
|
|
NumBanks |
|
DL1 caches in SharedL2Multi.conf and L2 caches in PrivL2Multi.conf
include some state machines for bus-snooping MESI cache coherency
protocol. Note that the cache coherency protocol takes some time to synchronize
contents among cores. Thus, if you decide to use a single core, it is better to
use the configuration file for single-core instead of using the multi-core one.
Modify the parameters you have chosen from the tables above. For all
parameters that have AccessTime as prefixes, you need to calculate
access time per clock cycle (see Section 4.1, “CACTI”).
Also note that you must follow the basic rules described above to
avoid an incorrect simulation or an infinite loop.
You can change the clock frequency in order to save power or to improve performance.
Modify Frequency parameter to the designated clock frequency.
For example, if you want to use 1GHz instead of 100MHz, set Frequency to
1000000000 and recalculate the access time of each cache you configured.
If you change the clock frequency, remember to recalculate the access time
of each cache (see Section 4.1, “CACTI”).
|
|
|
|
The clock frequency must be in the range of [100MHz, 2.1GHz]. Frequencies outside of that range are not supported by the simulator. |
To help you get started with software optimization, we prepared a very naive
version of sommelier, written in C. This implementation is in the naive.c
file; note how main() in sommelier.c calls the functions in naive.c
in a loop. Adding your own implementation of Sommelier is very easy; we
recommend you to copy naive.c (say to foo.c) and then build it with:
$ make ALG=foo
The build creates two executables: sommelier can be run natively in your
VM, and sommelier.sesc is the one to run on SESC.
You can run regression tests on your new implementation with:
$ make ALG=foo test
A successful run of the test suite will report "test OK".
Cleaning up the compilation can be done with:
$ make clean
Feel free to set the ALG variable in the Makefile to point to one of your
algorithms. By default it points to the naive algorithm we provide.
Several implementations of the matrix operations can coexist as long as
they live on separate files—it is just a matter of passing the right ALG
parameter to the makefile. Make sure you get familiar with sommelier.[ch],
smat.[ch], naive.c and the provided Makefile before you continue.
|
|
|
|
The only files that you should modify are the ones that implement
your algorithms (e.g. |
To run the large test for implementation foo on the VM, do:
$ cd ~/project/sommelier $ make clean $ make ALG=foo $ ./sommelier -t large
- Your algorithm must be correct. At the very least, it must pass the regression test (ie “make test ALG=myalg”.)
|
|
|
|
Admittedly, the provided test is not as thorough as it could be. This means that passing ‘make test’ is a necessary but not sufficient condition for correctness. It is your responsibility to provide a correct implementation, and the outcome of ‘make test’ should only be taken as informative. |
-
If you decide to use multiple threads, you should obey the following two rules (If you don’t, SESC may fall into an infinite loop):
- The number of threads that can run simultaneously should be smaller or equal to the number of cores.
- Only the main thread can spawn new threads, ie a child thread cannot spawn any threads.
-
Your code should be written in C (ie no inline assembly), compiled with
no optimizations (
gcc -O0, which is the default). This is enforced by the provided makefile, which you are not allowed to modify.
Unfortunately, SESC is not compatible with pthreads, which is the POSIX standard for multi-threaded programming. This means that we either need to maintain separate files for SESC and pthreads, with the burden that it implies, or provide some glue code to abstract their differences, in order to retain a single source file for every algorithm.
For simplicity, we decided to implement the second option and provide the
glue code. We acknowledge that given the limitations just seen, pthreads
cannot be mapped in its entirety onto SESC's API. Nonetheless our needs
are so modest that our glue code serves the purpose well; with it, we can
natively test our code compiled with pthreads (which is turned on when doing
make ALG=foo), and if it works, we can be confident that it will also
function correctly on SESC.
Our very simple layer on top of sesc_api/pthreads is implemented in
job_api.h. You just need to modify the ‘struct work` defined in it,
and include the file from your C sources to use it. We have included
an example, job_api_example.c to make the process easier for you.
You can build the example for both sesc/pthreads with `make example’.
The example file is thoroughly commented; make sure you understand
it. Skimming over job_api.h at this point is also recommended.
- You can assume that all matrices used in Sommelier are square matrices. This makes the code slightly easier to write.
- You can assume no broadcasting can possibly take place; that is, all matrix-matrix and matrix-vector operations have their inputs appropriately sized. For example, an (m,n)-array can only multiply an n-vector.
-
Numerical stability should
not be a concern, unless you are doing something extremely fiddly.
As long as you can pass
make test, with regards to stability, you are fine.
- Make sure you understand the problems, and the classic ways of dealing with it. [CLRS] is certainly a good place to start.
- If you have trouble with C, Kernighan & Ritchie have all the answers. If you cannot compile your code, chances are the compiler will throw a meaningful error message. Do not overlook it.
- Some parallel implementations may seem useful on paper, but note that due to the simple job scheduler that the simulator supports, you should make sure that all spawned jobs (remember: one per core!) have a similarly complex workload.
-
Sparse, a semantic
parser for C, can help you detect subtle bugs. Run it with
make sparse ALG=foo. - Special attention must be paid to memory usage. An algorithm may be more complex (in terms of number of operations) than others, but more cache-efficient and thus run faster. Make sure you follow a quantitative approach, and choose the algorithm that yields the best results.
- When trying to parallelize the code, think about the order in which the intermediate data structures you use are accessed.
- If your code segfaults, run it under gdb to see where it crashed.
In the next sections we explain how to model a memory organization using
CACTI, run a simulation using SESC, and analyze the experimental
results using the report.pl script. Note that these calculations
should be done after choosing a combination of system configuration.
Let us go through an example: for this purpose we have chosen the single-core without L2 cache configuration (i.e. the one in the first column and the first row of Table 5, “All possible memory hierarchy organizations and their corresponding configuration file names.”) that is characterized by the following structure:
- Core Configuration: a 1-way issued in-order SmallCore;
- Cache Hierarchy: IL1 and DL1 caches, no L2 cache;
- IL1 and DL1 caches configuration: the cache size is 32768B, the block size is 32B, and the associativity is 2
- Clock Frequency: 100 MHz.
As explained in Section 6.2, “Designing the Memory Hierarchy”, in this case you need to choose
confs/NoL2Single.conf as a configuration file to run SESC.
The configuration listed above is the default configuration of the
file. However, you still need to get the access time of IL1 and DL1 caches.
Now, it is time to run CACTI.
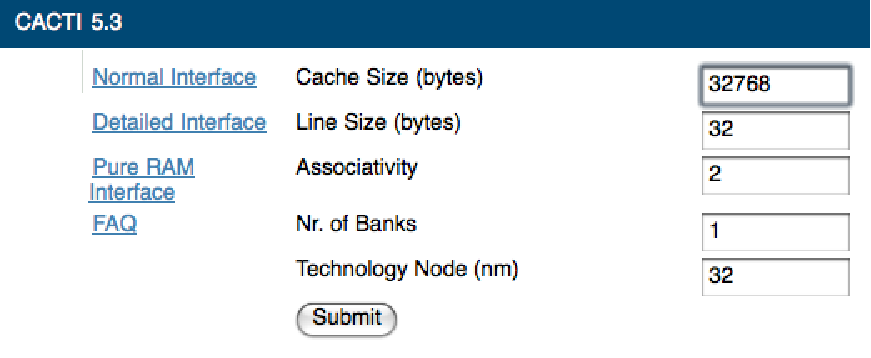
To run CACTI, load [cacti_hp] on your web browser. You will see the web page reported in Figure 3, “The web version of CACTI model available at [cacti_hp]”. It is straightforward to input the cache configuration. Enter the numbers for the desired configuration (see Figure 3, “The web version of CACTI model available at [cacti_hp]”) and click on the “Submit” button. Since you are using a 32nm technology, do not forget to enter 32 for the “Technology Node” field. The results that you will obtain are reported in Figure 4, “Result from running CACTI of the specified configuration.”. In particular, “Access Time” is the most important number.
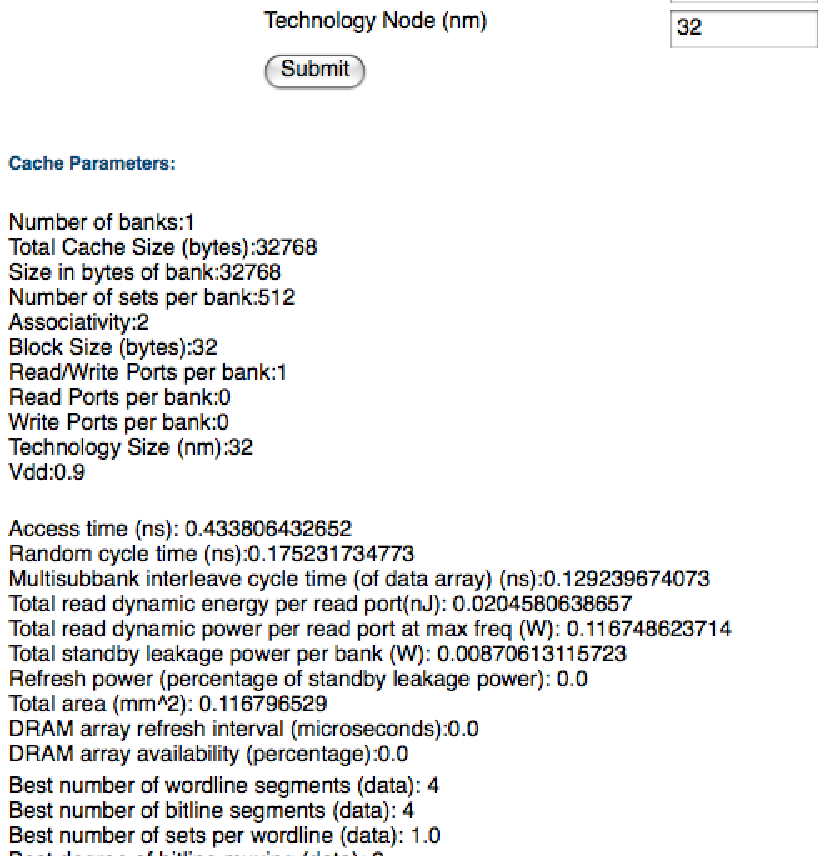
As shown in Figure 4, “Result from running CACTI of the specified configuration.”, the delay for our configuration is
0.433806432652ns. Since SESC only works with the notion of clock cycles,
you need to manually convert the Access Time of the L1 caches in nanoseconds
to the number of clock cycles with the
ceiling
function, ie:
Clock Cycle Time for Cache Access = $\lceil \text{Access Time} \times \text{Clock Frequency} \rceil$ = $\lceil 0.433806432652 \times {10}^{-9} \times 1 \times {10}^8 \rceil$ = $\lceil 0.0433806432652 \rceil$ = 1
For a clock frequency of 100 MHz, the SmallIL1AccessTime and
SmallDL1AccessTime parameters should be set to 1 in the
confs/NoL2Single.conf file.
In order to measure power with SESC, you need to preprocess the configuration
you want to use. Use wattchify and cactify to include power figures
in the config file for the microarchitecture and cache banks of the system.
Note that each time you modify the configuration file, you have to run both
wattchify and cactify.
To run wattchify and cactify with NoL2Single.conf, type the following
commands in your project/workspace directory:
$ ./wattchify ../confs/NoL2Single.conf ../confs/tmp.conf $ ./cactify ../confs/tmp.conf ../confs/NoL2SinglePower.conf
Then tmp.conf and NoL2SinglePower.conf will be generated in the conf
directory. Note that you have to use the NoL2SinglePower.conf file to
run simulations. tmp.conf can be discarded.
If necessary, build sommelier and sommelier.sesc as described in Section
Section 7, “Software Optimization” by issuing make ALG=foo from the sommelier directory.
To run SESC with the NoL2SinglePower.conf configuration file and
sommelier with the large dataset, issue the following command from the
workspace directory:
$ ./sesc.smp -c../confs/NoL2SinglePower.conf -dsimlarge -fresult \
../sommelier/sommelier.sesc -t large
|
|
|
|
If this is your first run, you probably want to use the small test instead of the large one to check that everything works. small runs much faster! |
Setting the -d flag as simlarge for the prefix and the -f as result
for the suffix of the result file, will produce the simlarge.result file.
To see the statistics of results, you can use a script file by typing:
$ ../scripts/report.pl simlarge.result
From the results you see, Simulated Time ("Sim Time") is the most important, since it gives you how long it takes for your architecture to run the specified program.
Other parameters of interest are cache hit/miss ratios (reported separately
for instruction and data), CPI, and total power, which is reported in the
last column of the last line of the results (i.e. the Total line of the
Total (watts) column).
|
|
|
|
If you run multiple simulations with the same result file, each
result will be appended at the end of the file. Since the appended result
cannot be analyzed by the |
-
The power model in SESC is based on sim-wattch.
Specifically, sim-wattch considers dynamic power
$P_{d} = \alpha CV^{2}_{dd}f$ as the main source of power
consumption. The two most important factors in our simulation are the load
capacitance C and clock frequency f. Note that more complex logic and
bigger caches may increase C, while you can manually modify f by changing
the
Frequencyparameter of the configuration file. - A multicore architecture is not always the best. A sequential program may run slower on a multicore than on a single core that exploits the great amount of instruction-level parallelism (ILP).
- The algorithm with better asymptotic behavior, such as characterized by big-O notation, is not necessarily the best in practice. For example, if there is a complex algorithm that introduces more dependencies than a simpler one, parallelizing the simple algorithm may be a better option. That said, you are encouraged to look for fresh ideas in academic publications; make sure you include the corresponding citations in the report.
- In some cases an L2 with a multi-bank configuration can be a better choice as it provides low access time and power dissipation in L2. However, if the traffic from L1 always goes into one bank, you will get more cache misses without saving power consumption.
- Having a bigger cache is not always the best choice. If the cache is large enough to contain all data/instructions for one or more cores, a bigger cache may not be useful. On the other hand, there are some cases where the entire dataset of a program is too big to fit in a cache of any reasonable size. What can you do to address these problems?
- If you increase the number of cores to run multiple threads, the running time of SESC (ie time taken to run a simulation on your machine) may increase. To reach a good design may require a significant amount of simulations and it is important to start working on this project early, especially if you anticipate trouble in the programming part of the assignment.
We want to receive from you by the deadline a tarball with the following contents:
- README: very brief explanation of the added code files
-
Working source code (ie the
sommelierdirectory) -
Final result files for large, medium and small tests, along with
your final config file (
project.conf), bundled in a directory calledresults/. Note that by "result files" we mean the result files produced by SESC, not the output fromreport.pl. -
A report describing your work called
report.pdf.
To make your life easier we have added a makefile to the top-level directory.
You just need to type ‘make tarball TEAM=X’ (if your team id is X)
from ~/project to generate a tarball with the contents described above.
If you are not sure about what the makefile will do, type
make -n tarball
This will not create the tarball; it will just print the commands that the
makefile would execute (if -n had not been passed)
Once you have the tarball, extract it to check that it has all the necessary
files, and then send it as an attachment to 4824project+f12@gmail.com before
the deadline.
We will be looking at your code. Try to write code that is easy to read and understand. We would like your code to adhere to the linux kernel coding style; to help you with this, we have added a script to automatically check the compliance to the coding style. Simply type
$ make checkpatch ALG=foo
from ~/project/sommelier to check the style of the files that build
sommelier, in this case including foo.c.
We want to know what optimizations you tried, what worked and what didn’t, and also expect you to be analytical throughout the design exploration effort. For this, writing concisely is crucial, but also note that using some tables, diagrams and/or plots could be very helpful, too.
Given the modular way in which sommelier is built, you are invited to leave there implementations of suboptimal solutions that you found and then discarded—this way we can better assess your understanding.
You are encouraged to get inspired and try whatever approach you find reasonable, be it from a paper, the course’s material or the web. Make sure to cite all references.
Describe your work (including details on the configurations) and your simulation results in a report in PDF format (double column, 10 point font, 6 page limit). Your report must clearly state the simulation time and power dissipated of the small, medium and large tests.
We have added a LaTeX skeleton for the report under project/report/. You can
just edit the .tex file and type make to build the document. If you do not
want to use the provided skeleton, make sure to have your final report
reachable at ~/project/report/report.pdf when invoking make tarball.
In this case, you may also want to delete the makefile in the report
subdirectory, since an accidental run of make there could overwrite your
report.pdf file.
|
|
|
|
Both team members (if applicable) receive the same grade. |
This is not at all a race of sorts to see who finds the best implementation. While finding a very fast implementation is probably correlated with having done a good job, in no way it guarantees a good grade. Most of your grade is based on your level of understanding. This is why we encourage you to document things that work as well as things that didn’t in the report.
To demonstrate how serious we are about this, here is how the grading will be done: we will grade three major aspects of your work, roughly assigning a third of the grade to each of them. These aspects are:
- Code. Easy to understand, checkpatch/sparse-clean code that runs very efficiently gets full credit. Note that having tried multiple options (e.g. single vs multi-threaded) is a must for a good grade here.
- Design Space Exploration. You should follow a quantitative approach, drawing conclusions only after the numbers make it obvious. In order to get there you are expected to run and analyze a very significant amount of simulations; the sooner you start, the better.
- Report. If you have done the above as described, then please make sure you properly document your findings in the report. It would be a pity to ruin all your hard work with a report done in the last minute—and sadly, we have seen this happen. Note that while we can just read your code to judge its quality, reading your report is our only way of assessing your understanding and the quality of your exploration. Therefore, writing a good report is crucial if you want to do well.
[cacti_hp] http://www.hpl.hp.com/research/cacti/
[sesc] http://sesc.sourceforge.net
[CLRS] Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein, Introduction to Algorithms, Third Edition, Check Appendix D for basic matrix operations. Chapter 4.2 covers Strassen’s algorithm for matrix multiplication. Chapter 27 has valuable information about multithreading, and uses basic matrix operations as examples for parallelization.
[simwattch] http://reference.kfupm.edu.sa/content/w/a/wattch__a_framework_for_architectural_le_17924.pdf
[kernel_coding_style] http://www.kernel.org/doc/Documentation/CodingStyle