Feature-Flow

We developed a tracker which is capable of long-term tracking of tools in surgical environments. It achieves this by learning and adjusting online. Given only an initial seed of the track in the form of a bounding box (x, y, width and height), we learn the appearance of the tool as it twists and turns and changes in perspective and scale. In addition, our tracker can recover from lost tracks due to severe occlusions or exiting the frame.
The following shows the algorithm flow, described in more detail below:
When the first frame comes in (A), we extract corner features (B) within the supplied bounding box only. The goal is to build up a database of track states, representing discrete views of the object as it changes in appearance due to movements and lighting changes. Each track state (J) contains the image representing that state, the track location, and a list of corner features which represent that track view.
With each subsequent frame, we expand the search region at the location of the last track (C), but slightly larger (~1.5x larger than the previous track size), and extract corner features within this expanded search region (D) as candidate object features. Then we match into the database (E) to find the closest matching track state. This consists of feature matching and an attempt to align the candidate matches to the track features in each states of the database. Using each alignment, we warp the track chip from the database and compute a similarity measure (using normalized cross-correlation) to retrieve the best matching track state.
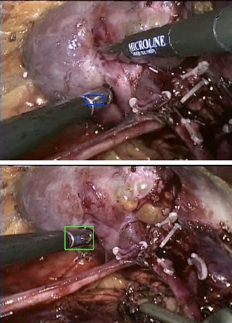
This could result in the final estimate of the track on the new frame, and if we stop here we get the following result:
[Top] In this case, the
tracker gets locked on
to the same part of the
tool that it has seen across
different views, but it’s
unable to identify new
parts of the object as it
twists and turns (blue).
Eventually the track is lost
because the camera is
viewing a part of the object
it’s never seen before and
has no way of knowing that
this is still the same object.
[Bottom] With our
algorithm, we are
able to discover new parts
of the object online and
track for longer periods of
time (green).
Likelihood Discovery
In order to discover new parts of the object, we construct multi-feature likelihoods (F) using a variety of appearance-based features (color, texture, etc). Each chosen feature results in a pixel-level likelihood map, representing at each pixel the likelihood that this pixel represents the object being tracked.
For the current results, we use a normalized cross-correlation of the best-matched track state against the entire image. This yields a correlation map.
We also represent color discriminability using the work of Collins, et. al., where local discriminative color features are computed and adjusted online based on the local background. Finally, we use a Gaussian bias using the location of the best-matched track state alignment. Combining all 3 features together by multiplying at each pixel, we get a composite likelihood which allows us to grow into regions of the object which are probabilistically likely to be apart of the object being tracked, even if they are outside the estimated tracking area.
We grow (G) by using inlier locations from the best matching track state alignment step as seed points within the composite likelihood image. In this way, we can flow amongst features to discover new parts of the object online, and this results in longer tracking times. As a final step, we refine the object features (H) that were originally extracted in (D) to recover newer object features and enter into the track database.
New entries are done periodically at fixed periods of time, so that we can sample the views of the object over time, but not too densely. For more details, please see the IROS 2010 paper.
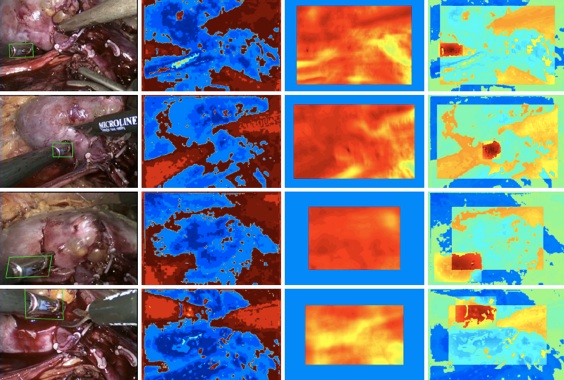
Here are some results:
[Left] The resulting tracks from our algorithm from 4 frames of a human laparoscopic procedure. [Middle-Left] Color likelihood map. [Middle-Right] Correlation likelihood map. [Right] Composite likelihood map, including the Gaussian bias (not shown). This is the likelihood which is used to grow into new parts of the object using the inlier points from the database matching step.
Our algorithm is able to persist through significant changes in perspective and scale:
We can use any features in the likelihood step which are capable of pixel level likelihood maps. We are currently incorporating Histogram-of-Oriented-Gradient features (using distances from a template) as well as Region Covariance descriptors.
The next step is to augment this tracker to recover the full 6-DOF pose of the tool (3-D position and 3-D orientation) in a robust manner, possibly including a model-based approach, such as POSIT.