
Speech and Natural Language Processing Papers Accepted to the ACL 2020
Papers from the Speech and Natural Language Processing groups were accepted to the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020). The research developed systems that improve fact-checking, generate sarcasm, and detect deception and a neural network that extracts knowledge about products on Amazon.
A team led by Shih-Fu Chang, the Richard Dicker Professor and Senior Executive Vice Dean School of Engineering, won a Best Demonstration Paper award for GAIA: A Fine-grained Multimedia Knowledge Extraction System, the first comprehensive, open-source multimedia knowledge extraction system.
Kathleen McKeown, the Henry and Gertrude Rothschild Professor of Computer Science, also gave a keynote presentation – “Rewriting the Past: Assessing the Field through the Lens of Language Generation”.
R3 : Reverse, Retrieve, and Rank for Sarcasm Generation with Commonsense Knowledge Tuhin Chakrabarty Columbia University, Debanjan Ghosh Educational Testing Service, Smaranda Muresan Columbia University, and Nanyun Peng University of Southern California
The paper proposes an unsupervised approach for sarcasm generation based on a non-sarcastic input sentence. This method employs a retrieve-and-edit framework to instantiate two major characteristics of sarcasm: reversal of valence and semantic incongruity with the context, which could include shared commonsense or world knowledge between the speaker and the listener.
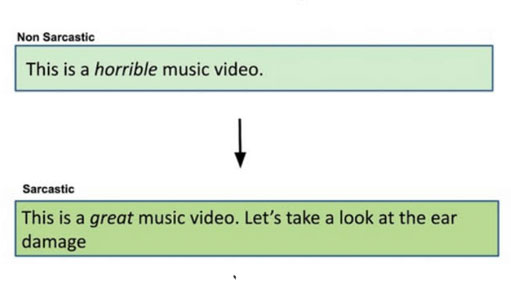
While prior works on sarcasm generation predominantly focus on context incongruity, this research shows that combining valence reversal and semantic incongruity based on commonsense knowledge generates sarcastic messages of higher quality based on several criteria. Human evaluation shows that the system generates sarcasm better than human judges 34% of the time, and better than a reinforced hybrid baseline 90% of the time.
Acoustic-Prosodic and Lexical Cues to Deception and Trust: Deciphering How People Detect Lies
Xi (Leslie) Chen Columbia University, Sarah Ita Levitan Columbia University, Michelle Levine Columbia University, Marko Mandic Columbia University, Julia Hirschberg Columbia University
Humans are very poor lie detectors. Study after study has found that humans perform only slightly above chance at detecting lies. This paper aims to understand why people are so poor at detecting lies, and what factors affect human perception of deception. To conduct this research, a web-based lie detection game called LieCatcher was created. Players were presented with recordings of people telling lies and truths, and they had to guess which are truthful and which are deceptive. The game is entertaining for players and simultaneously provides labels of deception perception.
Judgments from more than 400 players were collected. This perception data was used to identify linguistic and prosodic (intonation, tone, stress, and rhythm) characteristics of speech that lead listeners to believe what is true or to trust it.
The researchers studied how the characteristics of trusted speech align or misalign with indicators of deception, and they trained machine learning classifiers to automatically identify speech that is likely to be trusted or mistrusted. They found several intuitive indicators of mistrust, such as disfluencies (e.g. “um”, “uh”) and speaking slowly. An indicator of trust was a faster speaking rate — people tended to trust speech that was faster. They also observed a mismatch between features of trusted and truthful speech and the strategies used by the players to be ineffective.
What surprised the researchers is that prosodic indicators of deception, such as pitch and loudness changes, were the most difficult for humans to perceive and interpret correctly. In fact, many prosodic cues to deception were perceived by human raters as cues to the truth. For example, utterances with a higher pitch were perceived as more truthful, when in fact this is a cue to deception.
This work is useful for a number of applications, such as generating trustworthy speech for virtual assistants or dialogue systems.
TXtract: Taxonomy-Aware Knowledge Extraction for Thousands of Product Categories
Giannis Karamanolakis Columbia University, Jun Ma Amazon.com, Xin Luna Dong Amazon.com
The paper presents TXtract, a neural network that extracts knowledge about products from Amazon’s taxonomy with thousands of product categories, ranging from groceries to health products and electronics.
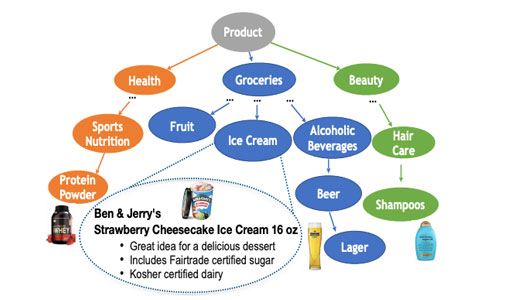
For example, given an ice cream product at Amazon.com with text description “Ben & Jerry’s Strawberry Cheesecake Ice Cream 16 oz”, TXtract extracts text phrases as product attributes:
Flavor: “strawberry cheesecake”
Package size: “16 oz”
Values extracted through TXtract lead to a richer catalog with millions of products and their corresponding attributes, which is promising to improve the experience of customers searching for products at Amazon.com or asking product-specific questions through Amazon Alexa.
DeSePtion: Dual Sequence Prediction and Adversarial Examples for
Improved Fact-Checking
Christopher Hidey Columbia University, Tuhin Chakrabarty Columbia University, Tariq Alhindi Columbia University, Siddharth Varia Columbia University, Kriste Krstovski Columbia University, Mona Diab Facebook AI & George Washington University, and Smaranda Muresan Columbia University
The increased focus on misinformation has spurred the development of data and systems for detecting the veracity of a claim as well as retrieving authoritative evidence. The FactExtraction and VERification (FEVER) dataset provide such a resource for evaluating end-to-end fact-checking, requiring retrieval of evidence from Wikipedia to validate a veracity prediction.
This paper shows that current systems for FEVER are vulnerable to three categories of realistic challenges for fact-checking – multiple propositions, temporal reasoning, and ambiguity and lexical variation – and introduces a resource with these types of claims.
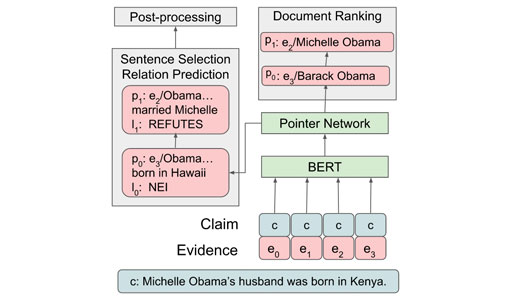
from two different sources (Michelle Obama and Barrack Obama).
The researchers present a system designed to be resilient to these “attacks” using multiple pointer networks for document selection and jointly modeling a sequence of evidence sentences and veracity relation predictions. They found that in handling these attacks they obtained state-of-the-art results on FEVER, largely due to improved evidence retrieval.